jieba库的使用和好看的词元
2024-10-10 17:48:58
一.jieba库的使用与说明
1.jieba库基本介绍
jieba库是优秀的中文分词第三方库
-中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
2.jieba库使用说明
(1)、jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
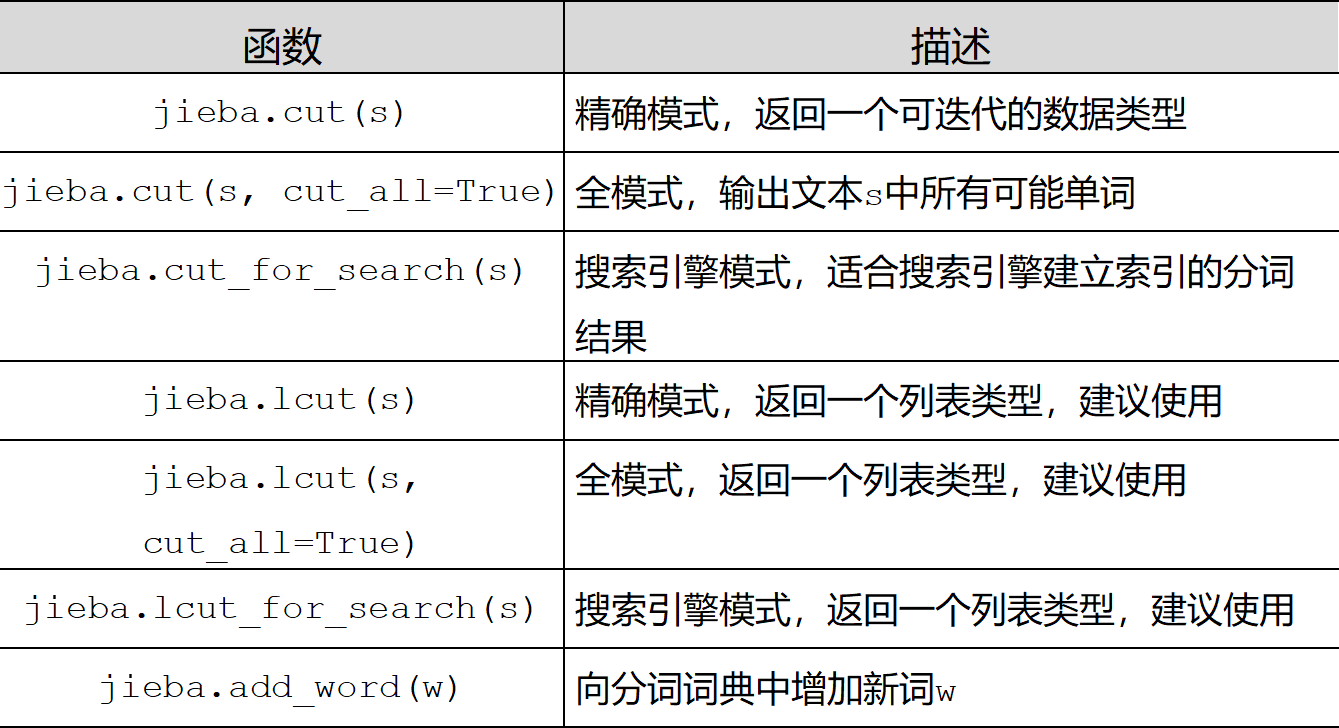
(2)、jieba库常用函数
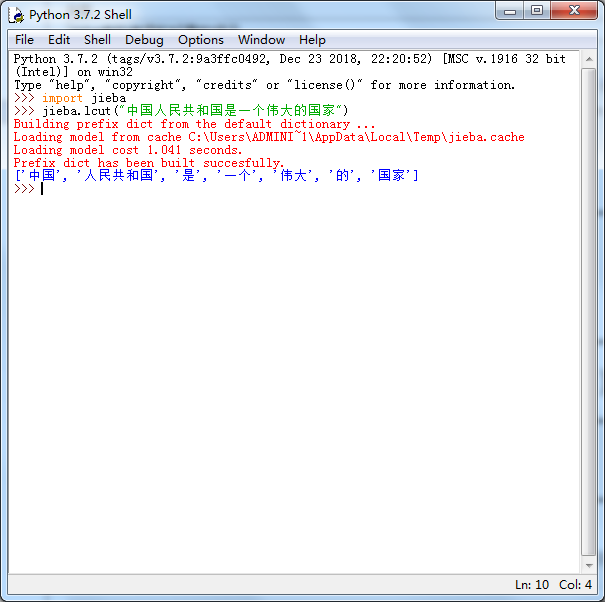
3.jieba库的利用实例显示
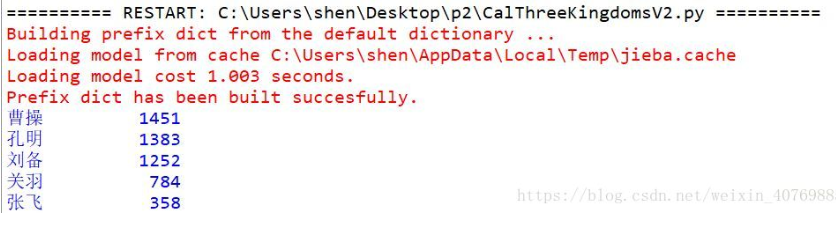
4.利用jieba库统计三国演义的人物出场次数
(1)代码如下
import jieba
excludes = {"将军","却说","荆州","二人","不可","不能","如此","商议","军士","如何",
"主公","军马","左右",}
txt = open("./三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == :
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,) +
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[], reverse=True)
for i in range():
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
(2)结果显示如下:
二、利用好看的词元
1.Python的词元图的生成
(1)安装库
pip install jieba wordcloud matplotlib
(2)准备
- txt文本
- 字体(simhei.ttf)
- 词云背景图片
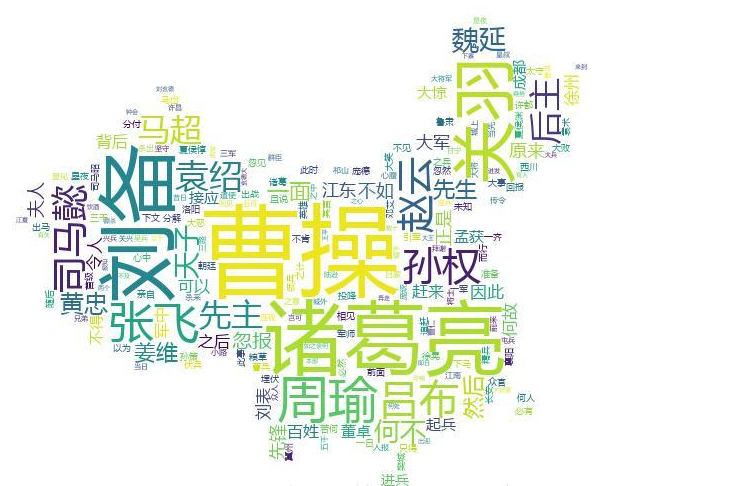
由上面的三国演义的文本txt可以生成如下图形:
Python jieba和词元的利用到此结束....................
最新文章
- H3 BPM让天下没有难用的流程之功能介绍
- Java EE之一个表单两个按钮响应不同界面(登录与注册)
- 多线程下的for循环问题
- 在SqlServer查询分析器里 访问远程数据库 进行数据查询更新等操作(openrowset)
- CentOS 6.6 (Desktop)部署Apache、MySQL以及Eclipse Luna等记录
- VMware Workstation 10.0.4.2249910 CN
- 关于MySql全文索引
- Android IOS WebRTC 音视频开发总结(四五)-- ORTC背后的真相
- wget下载FTP的文件
- Windows2008安装IIS方法
- Spring【AOP模块】就是这么简单
- Redis登录密码设置
- C++中几个输入函数的用法和区别(cin、cin.get()、cin.getline()、getline()、gets()、getchar())
- Python在终端通过pip安装好包以后,在Pycharm中依然无法使用的解决办法
- LeetCode--030--串联所有单词的字串(java)
- Hibernate search使用示例(基础小结-注解方式)
- Vivado Design Suite用户指南之约束的使用第二部分(约束方法论)
- 使用CGlib出现java.lang.NoClassDefFoundError: org/objectweb/asm/Type异常
- 对word2vec的理解及资料整理
- luogu1073 最优贸易 (tarjan+dp)