Python 3 Anaconda 下爬虫学习与爬虫实践 (1)
环境python 3
anaconda
pip
以及各种库
1.requests库的使用
主要是如何获得一个网页信息
重点是
r=requests.get("https://www.google.com/?hl=zh_CN")
这里是爬取了谷歌主页(科学上网)可以换成其他页面爬取
import requests
r=requests.get("https://www.google.com/?hl=zh_CN")
print(r.status_code)
r.encoding='utf-8'
print(r.text)
这里是代码部分,requests.get获得了一个网页的信息,存入r中
这个时候使用r.status_code如果返回200则证明调用成功,404表示失败,其实不是200就是失败
r.text是响应内容的字符串形式
r.encoding是从http header中猜测的响应内容编码方式(如果header中不存在charset,则认为编码方式为ISO-8859-1,这个时候就需要改为备选编码中的编码形式)
r.apparent_encoding 是从内容中分析出的响应内容编码方式(其实较为准确)
r.content 相应内容的二进制形式(比如获取图像时使用)
异常处理
r.raise_for_status() 如果不是200,产生异常requests.HTTPError
加入异常处理后形成了一个爬取网页的通用代码框架(使得爬取更稳定)
如下:
import requests def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常" if __name__=="__main__":
url="http://www.baidu.com/"
print(getHTMLText(url))
为理解这个库,需要理解HTTP
HTTP:Hypertext Transfer Protocol,超文本传输协议
HTTP对数据的操作与request库是对应的
通过URL获得资源
head方法可以通过较少的流量获得大概信息
requests.request(method,url,**kwargs) 最后一个参数可以省略
最常使用的还是get和head,主要是get
关于爬虫的量级
1.小规模,数据量小,爬取速度不敏感,爬取网页,玩转网页为目的的 这个时候使用requests库就可以满足
2.中规模,数据规模较大,爬取速度敏感,爬取网站,爬取系列网站 Scrapy库
3.爬取全网,大规模,搜索引擎比如百度,google,爬取速度关键,这一类的爬虫是定制开发的而非第三方库
下面是实践部分,有一些网站有反爬机制,比如亚马逊,所以需要改动我们的user-agent进行伪装,代码如下:
import requests def getHTMLText(url):
try:
# 更改头部信息,模拟成一个浏览器
kv = {'user-agent': 'Mozilla/5.0'}
r=requests.get(url,headers=kv,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.request.headers) return r.text[:1000]
except:
return "产生异常" if __name__=="__main__":
url="https://www.amazon.cn/dp/B07FDT8P6C/ref=cngwdyfloorv2_recs_0?pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_s=desktop-2&pf_rd_t=36701&pf_rd_i=desktop&pf_rd_m=A1AJ19PSB66TGU&pf_rd_r=G32Y9X81496BTATWRG3A&pf_rd_r=G32Y9X81496BTATWRG3A&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e"
print(getHTMLText(url))
包含搜索的百度爬虫代码,期中kv_word是提交的输入关键词,最终返回获得的信息数量,每次略有差别,我随便一次为319295:
import requests def getHTMLText(url):
try:
# 更改头部信息,模拟成一个浏览器
kv_head = {'user-agent': 'Mozilla/5.0'}
kv_word={'wd':'Python'}
r=requests.get(url,params=kv_word,headers=kv_head,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.request.url) return len(r.text)
except:
return "产生异常" if __name__=="__main__":
url='https://www.baidu.com/s'
print(getHTMLText(url))
下面尝试爬取图片,主要就是用r.content转换为二进制进行存取代码如下:
import requests def getHTMLText(url):
try:
path='F:/a/abc.jpeg'
# 更改头部信息,模拟成一个浏览器
kv_head = {'user-agent': 'Mozilla/5.0'}
r=requests.get(url,headers=kv_head,timeout=30)
print(r.status_code)
#将获得的存入路径中,r.content是二进制文件
with open(path,'wb') as f:
f.write(r.content)
f.close()
return len(r.text)
except:
return "产生异常" if __name__=="__main__":
url='https://b-ssl.duitang.com/uploads/item/201601/25/20160125170559_SPKF2.jpeg'
print(getHTMLText(url))
下面我们尝试通过ip138网站来提交ip相关信息,爬取ip地址所在地,
可以先手动提交一个,发现其特点:
http://www.ip138.com/ips138.asp?ip=10.3.8.211
所以我们就可以仿真这个来进行查询
下面是代码部分:
import requests
url='http://www.ip138.com/ips138.asp?ip='
try:
r=requests.get(url+'10.3.8.211')
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
这个样例主要是帮助学习怎么用改变url的方式模拟按键,输入等等操作
要学会以URL的视角看待网络内容,也就是要以爬虫的视角来看待网络内容
下面就进入了解析的学习
这里需要用到的库是beautiful soup
简单来说主要是两行代码
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>data</p>',"html.parser")
就可以解析我们看到的信息
<p>...</p> 标签Tag
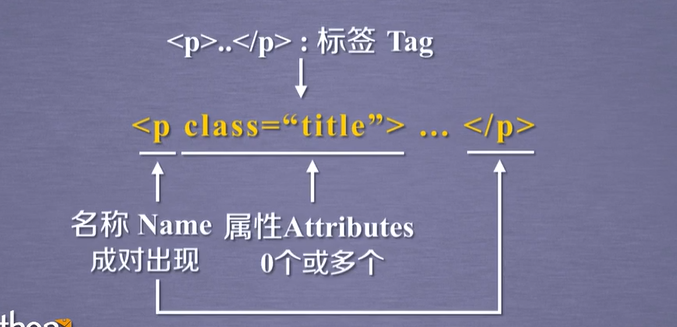

现在学习获取a标签也就是链接标签的内容的写法,这个时候主要就是写tag=soup.a
代码为:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.a
print(tag)
执行结果为:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">æ°é»</a>
标签被打印出来,如果文件中有多个a标签就只会返回第一个
如果相知道上一层是什么标签可以使用
soup.a.parent.name
就可以获得其上一层标签的名字,这里接着上一个代码写,所以上一层获得的返回结果为dev
下面学习怎么获得不同属性的值,通过
print(tag.attrs)
可以知道有哪些属性,比如我们需要获得class属性的值,那么使用tag.attrs['class']
刚刚几步实验的代码如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag)
那么我们怎么可以获得中间文本的值(也就是标签内非属性字符串)呢,这个时候就要用到
soup.a.string
标签之间的关系如下图:
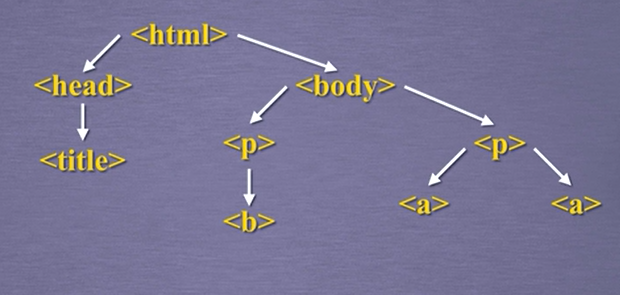
以及一些其他的对于标签的处理函数,如下代码:
import requests
from bs4 import BeautifulSoup r=requests.get("https://scholar.google.com/citations?hl=en&user=NoVsmbcAAAAJ")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.tbody
print(tag)
print(tag.contents)#找到里面内容
print(len(tag.contents))#内容长度
print(tag.contents[1])#取其中的第二个数据
for child in tag.children: #遍历儿子节点
print(child)
#print(tag.attrs['class'])
#print(soup.a.string)
同理.parent返回父标签, .parents返回祖先标签
以及还有一些平行标签
print(tag.next_sibiling)
通过这些知识,我们可以对前后标签进行遍历

最新文章
- django使用ldap认证
- 运用ASMIOSTAT脚本监控asm disk磁盘性能
- 兼容IE, Chrome的ajax function
- WM_INITDIALOG与WM_CREATE消息的区别
- memcached-win32-1.4.4-14 help doc
- 前端--json数据的处理及相关兼容问题
- [SOJ] Ordering Tasks
- 阿里云ECS部署ES
- 201521123097《Java程序设计》第五周学习总结
- Java_Date_02_截断日期到日
- 第七次作业——numpy统计分布显示
- bootstrap-3-上传图片-列表显示
- Install windows server 2008 on ESXi 5.1, add to domain and config for remote desktop
- webpack 打包问题2
- Apache JMeter的基本使用
- Scrum Meeting 6 -2014.11.12
- 在 Pandas 中更改列的数据类型
- C# 高级编程9 第30章MEF C#可扩展编程之MEF第2章(抄录)
- Java从零开始学十(Arrays类对数组的常用方法)
- CentOS 6.7 配置LVM (逻辑卷管理)