049 DSL语句
2024-10-13 08:45:42
1.说明

2.sql程序
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show()
}
}
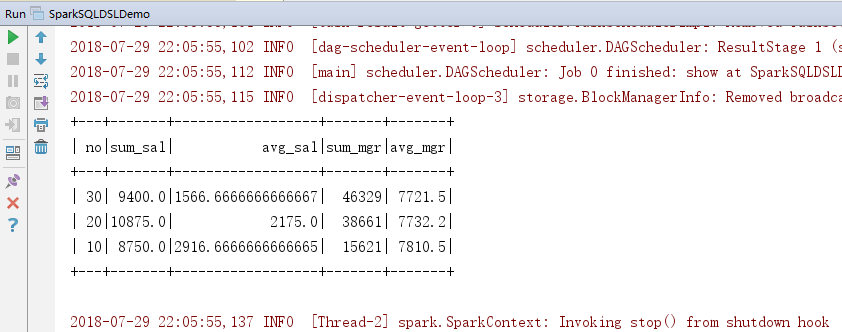
3.效果
4.DSL对上面程序重构
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show()
}
}
5.效果

6.Select语句
可以使用string,也可以使用col,或者$。
在Select中可以使用自定义的函数进行使用。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show()
}
}
7.Where语句
//=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show()
8.groupBy语句
建议使用第三种方式,也是最常见的使用方式。
同样是支持自定义函数。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() }
}
9.sort、orderBy排序
//=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show()
10.窗口函数
//=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
二:总程序总览
package com.scala.it import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show() //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show() //=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show() //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() //=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show() //=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
}
}
最新文章
- javascript自定义滚动条插件,几行代码的事儿
- <转>java 快速查找
- centos 安装sphinx
- laravel named route
- IOS开发一些资源收集
- Retrofit2.0+OkHttp打印Request URL(请求地址参数)
- MinGW 使用 msvcr90.dll
- fiddler--firefiox代理
- loadrunner使用socket协议来实现客户端对服务器产生压力实例。(通过发送心跳包,达到连接多个客户端的目的)
- C# Async/await 异步多线程编程
- shell script测试命令(test)
- SQL使用总结-like,MAX,MIN
- c# 单元测试工程如何取得当前项目路径
- Tail Recusive
- Blender设置界面语言
- 【排序算法】选择排序(Selection sort)
- 各浏览器 position: fixed 造成的bug 通用解决办法,Safari, iOS
- HTML5 File API 全介绍
- ubuntu 设置静态IP GW
- Selector#wakeup()