Spark、Shark集群安装部署及遇到的问题解决
1.部署环境
- OS:Red Hat Enterprise Linux Server release 6.4 (Santiago)
- Hadoop:Hadoop 2.4.1
- Hive:0.11.0
- JDK:1.7.0_60
- Python:2.6.6(spark集群需要python2.6以上,否则无法在spark集群上运行py)
- Spark:0.9.1(最新版是1.1.0)
- Shark:0.9.1(目前最新的版本,但是只能够兼容到spark-0.9.1,见shark 0.9.1 release)
- Zookeeper:2.3.5(配置HA时使用,Spark HA配置参见我的博文:Spark:Master High Availability(HA)高可用配置的2种实现)
- Scala:2.11.2
2.Spark集群规划
- 账户:ebupt
- master:eb174
- slaves:eb174、eb175、eb176
3.建立ssh
cd ~
#生成公钥和私钥
ssh-keygen -q -t rsa -N "" -f /home/ebupt/.ssh/id_rsa
cd .ssh
cat id_rsa.pub > authorized_keys
chmod go-wx authorized_keys
#把文件authorized_keys复制到所有子节点的/home/ebupt/.ssh目录下
scp ~/.ssh/authorized_keys ebupt@eb175:~/.ssh/
scp ~/.ssh/authorized_keys ebupt@eb176:~/.ssh/
另一个简单的方法:
由于实验室集群eb170可以ssh到所有的机器,因此直接拷贝eb170的~/.ssh/所有文件到eb174的~/.ssh/中。这样做的好处是不破坏原有的eb170的ssh免登陆。
[ebupt@eb174 ~]$rm ~/.ssh/*
[ebupt@eb170 ~]$scp -r ~/.ssh/ ebupt@eb174:~/.ssh/
4.部署scala,完全拷贝到所有节点
tar zxvf scala-2.11.2.tgz
ln -s /home/ebupt/eb/scala-2.11.2 ~/scala
vi ~/.bash_profile
#添加环境变量
export SCALA_HOME=$HOME/scala
export PATH=$PATH:$SCALA_HOME/bin
通过scala –version便可以查看到当前的scala版本,说明scala安装成功。
[ebupt@eb174 ~]$ scala -version
Scala code runner version 2.11.2 -- Copyright 2002-2013, LAMP/EPFL
5.安装spark,完全拷贝到所有节点
解压建立软连接,配置环境变量,略。
[ebupt@eb174 ~]$ vi spark/conf/slaves
#add the slaves
eb174
eb175
eb176
[ebupt@eb174 ~]$ vi spark/conf/spark-env.sh
export SCALA_HOME=/home/ebupt/scala
export JAVA_HOME=/home/ebupt/eb/jdk1..0_60
export SPARK_MASTER_IP=eb174
export SPARK_WORKER_MEMORY=4000m
6.安装shark,完全拷贝到所有节点
解压建立软连接,配置环境变量,略。
[ebupt@eb174 ~]$ vi shark/conf/shark-env.sh
export SPARK_MEM=1g # (Required) Set the master program's memory
export SHARK_MASTER_MEM=1g # (Optional) Specify the location of Hive's configuration directory. By default,
# Shark run scripts will point it to $SHARK_HOME/conf
export HIVE_HOME=/home/ebupt/hive
export HIVE_CONF_DIR="$HIVE_HOME/conf" # For running Shark in distributed mode, set the following:
export HADOOP_HOME=/home/ebupt/hadoop
export SPARK_HOME=/home/ebupt/spark
export MASTER=spark://eb174:7077
# Only required if using Mesos:
#export MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so
source $SPARK_HOME/conf/spark-env.sh #LZO compression native lib
export LD_LIBRARY_PATH=/home/ebupt/hadoop/share/hadoop/common # (Optional) Extra classpath export SPARK_LIBRARY_PATH=/home/ebupt/hadoop/lib/native # Java options
# On EC2, change the local.dir to /mnt/tmp
SPARK_JAVA_OPTS=" -Dspark.local.dir=/tmp "
SPARK_JAVA_OPTS+="-Dspark.kryoserializer.buffer.mb=10 "
SPARK_JAVA_OPTS+="-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps "
SPARK_JAVA_OPTS+="-XX:MaxPermSize=256m "
SPARK_JAVA_OPTS+="-Dspark.cores.max=12 "
export SPARK_JAVA_OPTS # (Optional) Tachyon Related Configuration
#export TACHYON_MASTER="" # e.g. "localhost:19998"
#export TACHYON_WAREHOUSE_PATH=/sharktables # Could be any valid path name
export SCALA_HOME=/home/ebupt/scala
export JAVA_HOME=/home/ebupt/eb/jdk1..0_60
7.同步到slaves的脚本
7.1 master(eb174)的~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH export JAVA_HOME=/home/ebupt/eb/jdk1..0_60
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=$HOME/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export ZOOKEEPER_HOME=$HOME/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH export HIVE_HOME=$HOME/hive
export PATH=$HIVE_HOME/bin:$PATH export HBASE_HOME=$HOME/hbase
export PATH=$PATH:$HBASE_HOME/bin export MAVEN_HOME=$HOME/eb/apache-maven-3.0.
export PATH=$PATH:$MAVEN_HOME/bin export STORM_HOME=$HOME/storm
export PATH=$PATH:$STORM_HOME/storm-yarn-master/bin:$STORM_HOME/storm-0.9.-wip21/bin export SCALA_HOME=$HOME/scala
export PATH=$PATH:$SCALA_HOME/bin export SPARK_HOME=$HOME/spark
export PATH=$PATH:$SPARK_HOME/bin export SHARK_HOME=$HOME/shark
export PATH=$PATH:$SHARK_HOME/bin
7.2 同步脚本:syncInstall.sh
scp -r /home/ebupt/eb/scala-2.11. ebupt@eb175:/home/ebupt/eb/
scp -r /home/ebupt/eb/scala-2.11. ebupt@eb176:/home/ebupt/eb/
scp -r /home/ebupt/eb/spark-1.0.-bin-hadoop2 ebupt@eb175:/home/ebupt/eb/
scp -r /home/ebupt/eb/spark-1.0.-bin-hadoop2 ebupt@eb176:/home/ebupt/eb/
scp -r /home/ebupt/eb/spark-0.9.-bin-hadoop2 ebupt@eb175:/home/ebupt/eb/
scp -r /home/ebupt/eb/spark-0.9.-bin-hadoop2 ebupt@eb176:/home/ebupt/eb/
scp ~/.bash_profile ebupt@eb175:~/
scp ~/.bash_profile ebupt@eb176:~/
7.3 配置脚本:build.sh
#!/bin/bash
source ~/.bash_profile
ssh eb175 > /dev/null >& << eeooff
ln -s /home/ebupt/eb/scala-2.11./ /home/ebupt/scala
ln -s /home/ebupt/eb/spark-0.9.-bin-hadoop2/ /home/ebupt/spark
ln -s /home/ebupt/eb/shark-0.9.-bin-hadoop2/ /home/ebupt/shark
source ~/.bash_profile
exit
eeooff
echo eb175 done!
ssh eb176 > /dev/null >& << eeooffxx
ln -s /home/ebupt/eb/scala-2.11./ /home/ebupt/scala
ln -s /home/ebupt/eb/spark-0.9.-bin-hadoop2/ /home/ebupt/spark
ln -s /home/ebupt/eb/shark-0.9.-bin-hadoop2/ /home/ebupt/shark
source ~/.bash_profile
exit
eeooffxx
echo eb176 done!
8 遇到的问题及其解决办法
8.1 安装shark-0.9.1和spark-1.0.2时,运行shark shell,执行sql报错。
shark> select * from test;
17.096: [Full GC 71198K->24382K(506816K), 0.3150970 secs]
Exception in thread "main" java.lang.VerifyError: class org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$SetOwnerRequestProto overrides final method getUnknownFields.()Lcom/google/protobuf/UnknownFieldSet;
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2531)
at java.lang.Class.privateGetPublicMethods(Class.java:2651)
at java.lang.Class.privateGetPublicMethods(Class.java:2661)
at java.lang.Class.getMethods(Class.java:1467)
at sun.misc.ProxyGenerator.generateClassFile(ProxyGenerator.java:426)
at sun.misc.ProxyGenerator.generateProxyClass(ProxyGenerator.java:323)
at java.lang.reflect.Proxy.getProxyClass0(Proxy.java:636)
at java.lang.reflect.Proxy.newProxyInstance(Proxy.java:722)
at org.apache.hadoop.ipc.ProtobufRpcEngine.getProxy(ProtobufRpcEngine.java:92)
at org.apache.hadoop.ipc.RPC.getProtocolProxy(RPC.java:537)
at org.apache.hadoop.hdfs.NameNodeProxies.createNNProxyWithClientProtocol(NameNodeProxies.java:334)
at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:241)
at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:141)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:576)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:521)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:146)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2397)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:89)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2431)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2413)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:368)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296)
at org.apache.hadoop.hive.ql.Context.getScratchDir(Context.java:180)
at org.apache.hadoop.hive.ql.Context.getMRScratchDir(Context.java:231)
at org.apache.hadoop.hive.ql.Context.getMRTmpFileURI(Context.java:288)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1274)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1059)
at shark.parse.SharkSemanticAnalyzer.analyzeInternal(SharkSemanticAnalyzer.scala:137)
at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:279)
at shark.SharkDriver.compile(SharkDriver.scala:215)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:337)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:909)
at shark.SharkCliDriver.processCmd(SharkCliDriver.scala:338)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:413)
at shark.SharkCliDriver$.main(SharkCliDriver.scala:235)
at shark.SharkCliDriver.main(SharkCliDriver.scala)
原因:不知道它在说什么,大概是说“protobuf”版本有问题.
解决:找到 jar 包 “hive-exec-0.11.0-shark-0.9.1.jar” 在$SHARK_HOME/lib_managed/jars/edu.berkeley.cs.shark/hive-exec, 删掉有关protobuf,重新打包,该报错不再有,脚本如下所示。
cd $SHARK_HOME/lib_managed/jars/edu.berkeley.cs.shark/hive-exec
unzip hive-exec-0.11.-shark-0.9..jar
rm -f com/google/protobuf/*
rm hive-exec-0.11.0-shark-0.9.1.jar
zip -r hive-exec-0.11.0-shark-0.9.1.jar *
rm -rf com hive-exec-log4j.properties javaewah/ javax/ javolution/ META-INF/ org/
8.2 安装shark-0.9.1和spark-1.0.2时,spark集群正常运行,跑一下简单的job也是可以的,但是shark的job始终出现Spark cluster looks dead, giving up. 在运行shark-shell(shark-withinfo )时,都会看到连接不上spark的master。报错类似如下:
shark> select * from t1;
16.452: [GC 282770K->32068K(1005568K), 0.0388780 secs]
org.apache.spark.SparkException: Job aborted: Spark cluster looks down
at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$abortStage$1.apply(DAGScheduler.scala:1028)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$abortStage$1.apply(DAGScheduler.scala:1026)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$abortStage(DAGScheduler.scala:1026)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$processEvent$10.apply(DAGScheduler.scala:619)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$processEvent$10.apply(DAGScheduler.scala:619)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.processEvent(DAGScheduler.scala:619)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$start$1$$anon$2$$anonfun$receive$1.applyOrElse(DAGScheduler.scala:207)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:498)
at akka.actor.ActorCell.invoke(ActorCell.scala:456)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:237)
at akka.dispatch.Mailbox.run(Mailbox.scala:219)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:386)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
FAILED: Execution Error, return code -101 from shark.execution.SparkTask
原因:网上有很多人遇到同样的问题,spark集群是好的,但是shark就是不能够很好的运行。查看shark-0.9.1的release发现
Release date: April 10, 2014
Shark 0.9.1 is a maintenance release that stabilizes 0.9.0, which bumps up Scala compatibility to 2.10.3 and Hive compliance to 0.11. The core dependencies for this version are:
Scala 2.10.3
Spark 0.9.1
AMPLab’s Hive 0.9.0
(Optional) Tachyon 0.4.1
这是因为shark版本只兼容到spark-0.9.1,版本不兼容导致无法找到spark集群的master服务。
解决:回退spark版本到spark-0.9.1,scala版本不用回退。回退后运行正常。
9.集群成功运行
9.1启动spark集群standalone模式
[ebupt@eb174 ~]$ ./spark/sbin/start-all.sh
9.2测试spark集群
[ebupt@eb174 ~]$ ./spark/bin/run-example org.apache.spark.examples.SparkPi 10 spark://eb174:7077
9.3 Spark Master UI:http://eb174:8080/
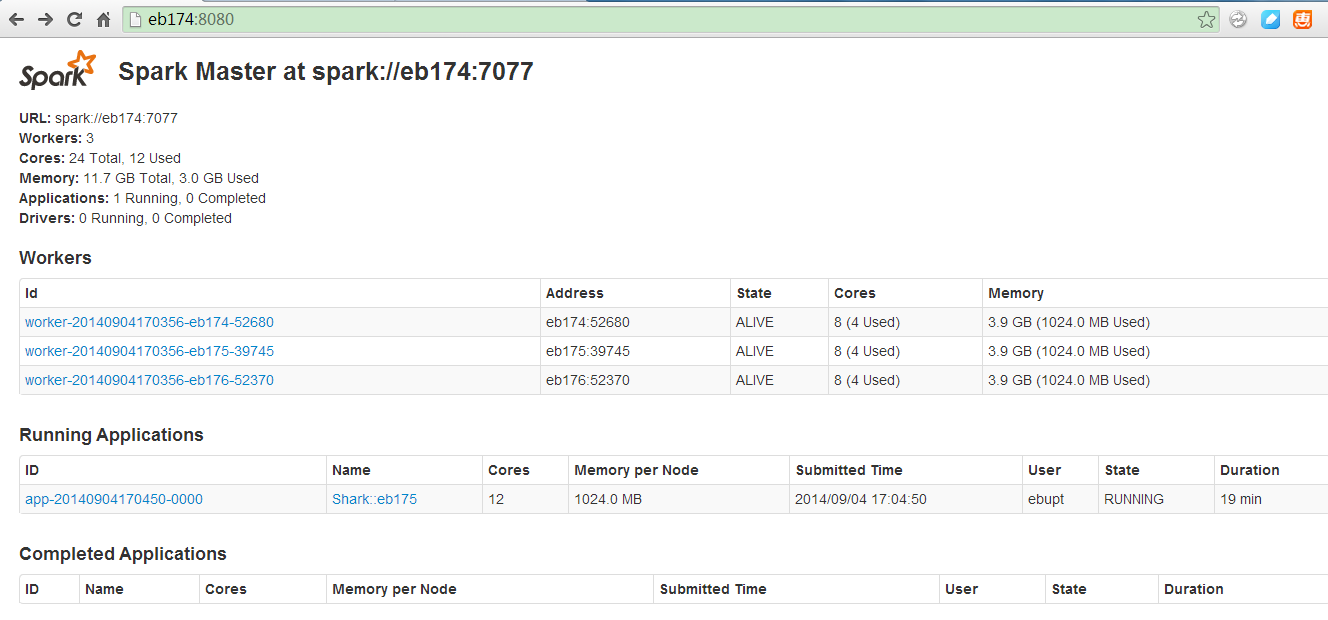
10 参考资料
- Apache Spark
- Apache Shark
- Shark安装部署与应用
- Spark github
- Shark github
- Spark 0.9.1和Shark 0.9.1分布式安装指南
- google group-shark users
- ERIC'S BLOG
最新文章
- PHP环境配置
- 下载php扩展笔记
- UITableViewCell 顶格
- NS2中trace文件分析
- Python3.5连接Mysql
- android中的提示信息显示方法(toast应用)
- for循环,如何结束多层for循环
- [POJ] 2226 Muddy Fields(二分图最小点覆盖)
- QSS 样式表 (一)
- C#第十一天(winform)
- C++使用: C++中map的基本操作和用法
- CAN协议教程
- C# 如何物理删除有主外键约束的记录?存储过程实现
- EXISTS 与 NOT EXISTS 的用法及返回结果
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
- 以为是tomcat出现using问题,怎么改都改不好终于找到原因
- js中script的上下放置区别 , Dom的增删改创建
- 在ubuntu中如何向U盘复制粘贴文件 Read-only file system
- Intel Caffe 与原生Caffe
- 动态获取selected的value值