一个豆瓣电影Top250爬虫
2024-10-20 16:24:25
一个爬虫
这是我第一次接触爬虫,写的第一个爬虫实例。
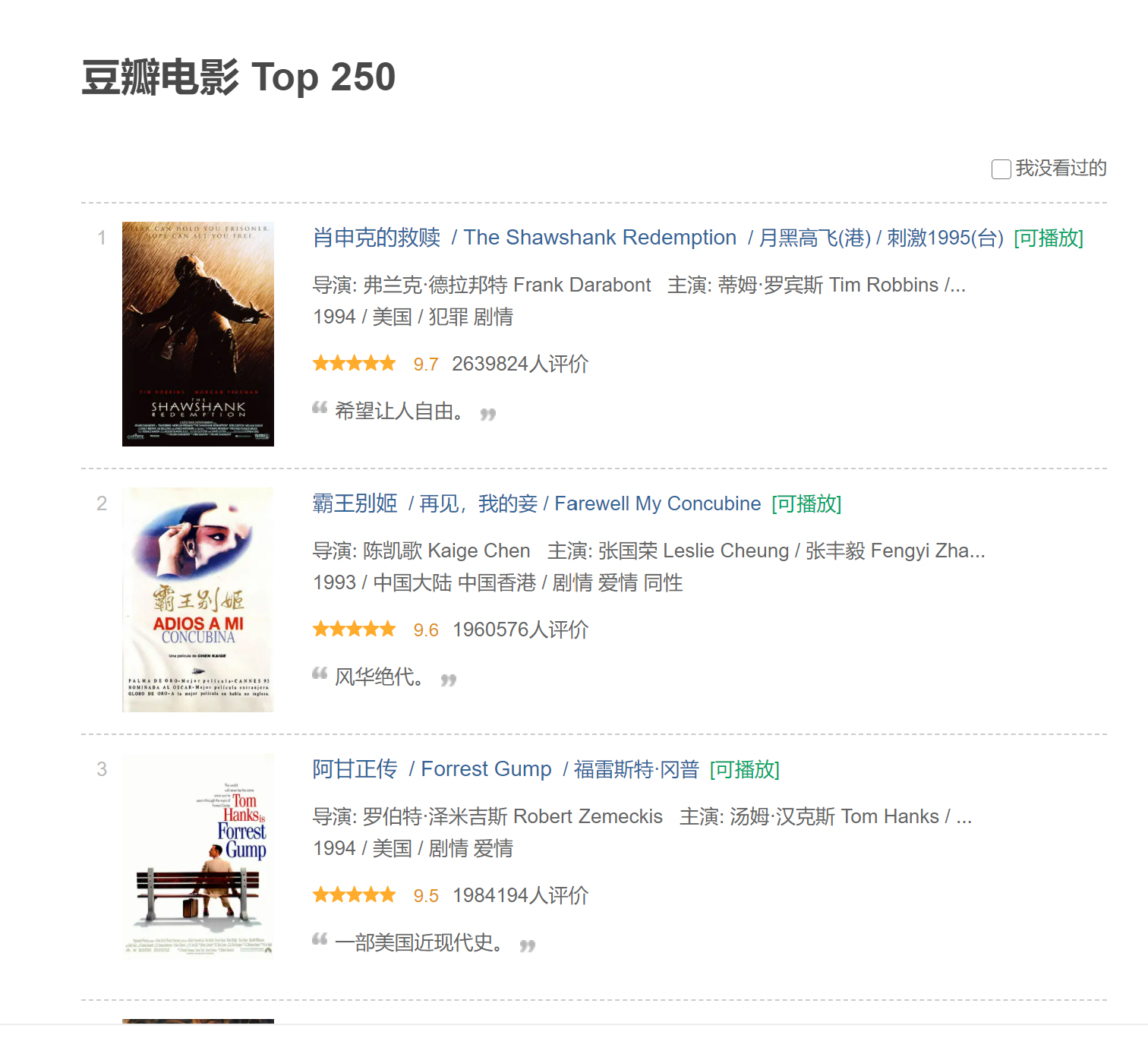
https://movie.douban.com/top250
模块
import requests #用于发送请求
import re #使用正则表达式,用于匹配处理文本
import os #用于创建文件夹
from lxml import etree #这里我使用了Xpath表达式用于数据解析,我觉得这个模块比BeautifulSoup好用,强烈推荐
from fake_useragent import UserAgent #反爬虫,随机获取浏览器 UA 信息
代码
import requests
import re
import os
from lxml import etree
from fake_useragent import UserAgent
class doubanSpider(object):
def __init__(self):
if not os.path.exists('db/douban'):
os.makedirs('db/douban')
else:
pass
self.f = open('./db/douban/douban.txt', 'a', encoding='utf-8')
def start(self):
for i in range(46):
headers = {
'User-Agent': UserAgent().random
}
url = 'https://movie.douban.com/top250?start=' + str(i * 25)
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
li_list = html.xpath('//*[@id="content"]/div/div[1]/ol/li')
movies = []
for each in li_list:
movie = {}
order = each.xpath('.//div/div[1]/em/text()')[0]
movie['id'] = order
cover = each.xpath('.//div/div[1]/a/img/@src')[0]
movie['cover'] = cover
name = each.xpath('.//div/div[2]/div[1]/a/span/text()')
flag = ''
for mo in name:
flag += mo
movie['name'] = flag
info = each.xpath('.//div/div[2]/div[2]/p[1]/text()[1]')[0].strip()
info = info.replace("\n", "")
info = info.replace("\xa0", "")
director = re.findall(r'[导演:].+[主演:]', info)[0]
director = director[4:len(director) - 3]
movie['director'] = director
try:
role = re.findall(r'主.+', info)[0]
role = role[4:]
except IndexError:
role = ''
movie['role'] = role
plot = each.xpath('.//div/div[2]/div[2]/p[1]/text()[2]')[0].strip()
plot = plot.replace("\xa0", "")
movie['plot'] = plot
star = each.xpath('.//div/div[2]/div[2]/div/span[2]/text()')[0]
movie['star'] = star
try:
comment = each.xpath('.//div/div[2]/div[2]/p[2]/span/text()')[0]
except IndexError:
comment = ''
movie['comment'] = comment
movies.append(movie)
self.f.write(str(movie)+'\n')
print(movie)
def run(self):
self.start()
self.f.close()
if __name__ == '__main__':
spider = doubanSpider()
spider.run()
最新文章
- Servlet过滤器,Servlet过滤器创建和配置
- Windows操作系统优化(Windows优化大师版) - 进阶者系列 - 学习者系列文章
- 成为 Linux 终端高手的七种武器 之七 条件执行&&
- linux下如何安装charles
- MVC4 WebAPI POST数据问题
- raspberryPi 拍照
- 第三百三十五天 how can I 坚持
- struts2开发经验小结(method="{1}"等)
- NET 2015
- HDFS概述(2)————Block块大小设置
- 在找一份相对完整的Webpack项目配置指南么?这里有
- 通用的Android控件抖动效果实现
- 深入理解Session与Cookie(一)
- UVA 1146 Now or later
- VS的Mvc项目右键没有控制器右键菜单(转)
- Javaweb学习笔记——(十一)——————JSP、会话跟踪、Cookie、HttpSession
- 24. Swap Nodes in Pairs 链表每2个点翻转一次
- vim basic
- CentOS 7配置Let’s Encrypt支持免费泛域名证书
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装