Mongo3基础操作
由于3.X的文档是在3.X当前最新版本前记录,所以这里列出一些常用的操作,比如建立库,删除库,等一些格式,然后在描述开启远程和创建用户的一些区别,以及讲解2.X和3.X配置文件区别。
1. Mongo配置文件及其它操作
MongoDB2.6开始推荐一种基于YAML格式的配置文件,并且仍然兼容之前的配置文件。
1.1 Mongo2.X配置文件
Mongo2.X版本配置文件是比较传统的配置文件,且一般现在如果用到mongo2.X版本,大多在centos6上,一般使用yum安装,这里贴出每个配置的详细含义,具体就不错做讲解。


#verbose:日志信息冗余。默认false。提高内部报告标准输出或记录到logpath配置的日志文件中。要启用verbose或启用verbosity 用vvvv参数
verbose = true
#启动verbose冗长信息,它的级别有 vv~vvvvv,v越多级别越高,在日志文件中记录的信息越详细。
vvvv = true #port:端口。默认27017,MongoDB的默认服务TCP端口,监听客户端连接。要是端口设置小于1024,比如1021,则需要root权限启动,不能用mongodb帐号启动
port = 27017 #bind_ip:绑定地址。默认127.0.0.1,只能通过本地连接。进程绑定和监听来自这个地址上的应用连接。要是需要给其他服务器连接,则需要注释掉这个或则把IP改成本机地址,可以用一个逗号分隔的列表绑定多个IP地址。
bind_ip = 0.0.0.0 #maxConns:最大连接数。默认值:取决于系统(即的ulimit和文件描述符)限制。MongoDB中不会限制其自身的连接。当设置大于系统的限制,则无效,以系统限制为准。这对于客户端创建很多“表”,允许连接超时而不关闭“表”的时候很有用。设置该值的高于连接池和总连接数的大小,以防止尖峰时候的连接。注意:不能设置该值大于20000。
maxConns = 1000 #objcheck:强制验证客户端请求。2.4的默认设置为objcheck成为true,在早期版本objcheck默认为false。因为它强制验证客户端请求,确保客户端绝不插入无效文件到数据库中。对于嵌套文档的对象,会有一点性能影响。设置noobjcheck 关闭。
objcheck = true
#noobjcheck = false #logpath:指定日志文件,该文件将保存所有的日志记录、诊断信息。除非另有指定,mongod将所有的日志信息输出到标准输出。如果没有指定logappend,重启则日志会进行覆盖操作。
logpath= /usr/local/mongodb/logs/mongodb.log
#logappend:写日志的模式:设置为true为追加。默认是覆盖。如果未指定此设置,启动时MongoDB的将覆盖现有的日志文件。
logappend=true #syslog:日志输出都发送到主机的syslog系统,而不是标准输出到logpath指定日志文件。syslog和logpath不能一起用,会报错:
syslog = false #pidfilepath:进程ID,没有指定则启动时候就没有PID文件。默认缺省。
pidfilepath = /usr/local/mongodb/data/mongo.pid #keyFile:指定存储身份验证信息的密钥文件的路径。默认缺省。
keyFile = /usr/local/mongodb/keyfile #nounixsocket:套接字文件,默认为false,有生成socket文件。当设置为true时,不会生成socket文件。
nounixsocket = false #unixSocketPrefix:套接字文件路径,默认/tmp
unixSocketPrefix = //usr/local/mongodb/tmp #fork:是否后台运行,设置为true 启动 进程在后台运行的守护进程模式。默认false。
fork = true #auth:用户认证,默认false。不需要认证。当设置为true时候,进入数据库需要auth验证,当数据库里没有用户,则不需要验证也可以操作。直到创建了第一个用户,之后操作都需要验证。比如:通过db.addUser('sa','sa')在admin库下面创建一个超级用户,只能在在admin库下面先认证完毕了:ab.auth('sa','sa'),才能去别的库操作,不能在其他库验证。这样连接数据库也需要指定库:
#mongo -usa -psa admin #sa 帐号连接admin
#mongo -uaa -paa test #aa 帐号连接test
auth = true #noauth:禁止用户认证,默认true
noauth = true #cpu:设置为true会强制mongodb每4s报告cpu利用率和io等待,把日志信息写到标准输出或日志文件。默认为false。
cpu = false #dbpath:数据存放目录。默认:/data/db/
dbpath= /usr/local/mongodb/data/ #diaglog:创建一个非常详细的故障排除和各种错误的诊断日志记录。默认0。设置为1,为在dbpath目录里生成一个diaglog.开头的日志文件,设置不等于0,日志会每分钟flush一次。产生的日志可以用mongosniff来查看,当重新设置成0,会停止写入文件,但mongod还是继续保持打开该文件,即使它不再写入数据文件。如果你想重命名,移动或删除诊断日志,你必须完全关闭mongod实例。
0 off. No logging. #关闭。没有记录。
#1 Log write operations. #写操作
#2 Log read operations. #读操作
#3 Log both read and write operations. #读写操作
#7 Log write and some read operations. #写和一些读操作 #directoryperdb:设置为true,修改数据目录存储模式,每个数据库的文件存储在DBPATH指定目录的不同的文件夹中。使用此选项,可以配置的MongoDB将数据存储在不同的磁盘设备上,以提高写入吞吐量或磁盘容量。默认为false。要是在运行一段时间的数据库中,开启该参数,会导致原始的数据都会消失(注释参数则会回来)。因为数据目录都不同了,除非迁移现有的数据文件到directoryperdb产生的数据库目录中,所以需要在规划好之后确定是否要开启。
directoryperdb = false #journal:日志,(redo log,更多的介绍请看这里和这里)。默认值:(在64位系统)true。默认值:(32位系统)false。
#设置为true,启用操作日志,以确保写入持久性和数据的一致性,会在dbpath目录下创建journal目录。
#设置为false,以防止日志持久性的情况下,并不需要开销。为了减少磁盘上使用的日志的影响,您可以启用nojournal,并设置为true。
#注意:在64位系统上禁用日志必须使用带有nojournal的。
journal = false #nojournal:禁止日志,默认值:(在64位系统)false。默认值:(32位系统)true。
#设置nojournal为true关闭日志,64位,2.0版本后的mongodb默认是启用 journal日志。
nojournal = true #journalCommitInterval:刷写提交机制,默认是30ms或则100ms。较低的值,会更消耗磁盘的性能。此选项接受2和300毫秒之间的值:
#如果单块设备提供日志和数据文件,默认的日记提交时间间隔为100毫秒。
#如果不同的块设备提供的日志和数据文件,默认的日记提交的时间间隔为30毫秒。
journalCommitInterval = 100 #ipv6:是否支持ipv6,默认false。
ipv6 = true #jsonp:是否允许JSONP访问通过一个HTTP接口,默认false。
jsonp = true #nohttpinterface:是否禁止http接口,即28017 端口开启的服务。默认false,支持。
nohttpinterface = false #noprealloc:预分配方式。默认false:使用预分配方式来保证写入性能的稳定,预分配在后台进行,并且每个预分配的文件都用0进行填充。这会让MongoDB始终保持额外的空间和空余的数据文件,从而避免了数据增长过快而带来的分配磁盘空间引起的阻塞。设置noprealloc= true来禁用预分配的数据文件,会缩短启动时间,但在正常操作过程中,可能会导致性能显著下降。
noprealloc = false #noscripting:是否禁止脚本引擎。默认是false:不禁止。ture:禁止,要是设置成true:运行一些脚本的时候会出现:"server-side JavaScript execution is disabled"
noscripting = true #notablescan:是否禁止表扫描操作。默认false:不禁止,ture:禁止,禁止要是执行表扫描会出现:"table scans not allowed"
notablescan = true #nssize:命名空间的文件(即NS)的默认大小,默认16M,最大2G。所有新创建的默认大小命名空间的文件(即NS)。此选项不会影响现有的命名空间的文件的大小。默认值是16M字节,最大大小为2 GB。让小数据库不让浪费太多的磁盘空间,同时让大数据在磁盘上有连续的空间。
nssize = 16 #profile:数据库分析等级设置。记录一些操作性能到标准输出或则指定的logpath的日志文件中,默认0:关闭。
#0 关。无分析。
#1 开。仅包括慢操作。
#2 开。包括所有操作。
#控制 Profiling 的开关和级别:2种,第一种是直接在启动参数里直接进行设置或则启动MongoDB时加上–profile=级别,其信息保存在 生成的system.profile 中。第二种是在客户端用db.setProfilingLevel(级别)命令来实时配置,其信息保存在 生成的system.profile 中。默认情况下,mongod的禁用分析。数据库分析可以影响数据库的性能,因为分析器必须记录和处理所有的数据库操作。所以在需要的时候用动态修改就可以了。
profile = 0 #slowms:记录profile分析的慢查询的时间,默认是100毫秒。具体同上。
slowms = 200 #quota:配额,默认false。是否开启配置每个数据库的最多文件数的限制。当为true则用quotaFiles来配置最多文件的数量。
quota = true
#quotaFiles:配额数量。每个数据库的数据文件数量的限制。此选项需要quota为true。默认为8。
quotaFiles = 8 #rest: 默认false,设置为true,使一个简单的 REST API。设置为true,开启后,在MongoDB默认会开启一个HTTP协议的端口提供REST的服务(nohttpinterface=false),这个端口是你Server端口加上1000,即28017,默认的HTTP端口是数据库状态页面,(开启后,web页面的Commands行中的命令都可以点进去)。mongodb自带的REST,不支持增、删、改,同时也不支持 权限认证。
rest = true #repair:修复数据库操作,默认是false。设置为true时,启动后修复所有数据库,设置这个选项最好在命令行上,而不是在配置文件或控制脚本。启动时修复,需要关闭journal.并且启动时,用控制文件指定参数和配置文件里指定参数的方式进行修复之后,(修复信息见log),需要再禁用repair参数才能启用mongodb。注意:mongod修复时,需要重写所有的数据库文件。如果在同一个帐号下不能运行修复,则需要运行chown修改数据库文件的权限。
repair = true #repairpath:修复路径,默认是在dbpath路径下的_tmp 目录。
repairpath = _tmp #smallfiles:是否使用较小的默认文件。默认为false,不使用。设置为true,使用较小的默认数据文件大小。smallfiles减少数据文件的初始大小,并限制他们到512M,也减少了日志文件的大小,并限制他们到128M。如果数据库很大,各持有少量的数据,会导致mongodb创建很多文件,会影响性能。
smallfiles = true #syncdelay:刷写数据到日志的频率,通过fsync操作数据。默认60秒。默认就可以,不需要设置。不会对日志文件(journal files)有影响。警告:如果设置为0,SYNCDELAY 不会同步到磁盘的内存映射文件。在生产系统上,不要设置这个值。
syncdelay = 60 #sysinfo:系统信息,默认false。设置为true,mongod会诊断系统有关的页面大小,数量的物理页面,可用物理??页面的数量输出到标准输出。当开启sysinfo参数的时候,只会打印上面的信息,不会启动mongodb的程序。所以要关闭该参数,才能开启mongodb。
sysinfo = false #upgrade:升级。默认为false。当设置为true,指定DBPATH,升级磁盘上的数据格式的文件到最新版本。会影响数据库操作,更新元数据。大部分情况下,不需要设置该值。
upgrade = false #traceExceptions:是否使用内部诊断。默认false。
traceExceptions = false #quiet:安静模式。
quiet = true #setParameter:2.4的新参数,指定启动选项配置。想设置多个选项则用一个setParameter选项指定.格式:setParameter = <parameter>=<value>,如配置文件里设置syncdelay:
setParameter = syncdelay= 55,notablescan = true,journalCommitInterval = 50,traceExceptions = true
Mongo2配置文件
1.2 Mongo3.X配置文件
Mongodb 3.x配置说明,本文内容忽略了Enterprise版和一些不常用的配置。
1.2.1 配置说明
在Mongod安装包中,包含2个进程启动文件:mongod和mongos;其中mongd是核心基础进程,用来接收读写请求、负责存储实际数据,mongod实例是构成集群的基本单位,比如Replication set、Sharding Cluster、Config Servers等;mongos是Sharding Cluster架构模式中的“路由”进程,即客户端请求访问mongos,然后有mongos将请求转发给合适的sharding server执行操作,并将result返回给客户端,所以mongos基本不存储数据,只是在内存中缓存部分shard key与sharding server的对应关系,便于路由。
在配置文件方面,mongod和mongos有很多相同之处,下文中如有区别之处将会特别指出。
在一个节点上,通常同时启动mongod和mongos进程是正常的,他们之间不存在资源竞争,但是为了避免冲突,我们希望它们使用各自的配置文件,比如mongod.conf、mongos.conf;mongodb的某些平台下的安装包中没有自带配置文件,需要开发者自己创建。
(比如centos版本没有任何配置文件)
在centos版本中使用的Mongo没有任何配置以及目录,都需要手动创建,这里把yum安装的配置拷贝过来做了点更改,只需要一些默认参数,Mongodb就可以启动。
1.2.2 重要配置参数讲解
1、processManagement:
fork: <true | false>
描述:是否以fork模式运行mongod/mongos进程,默认为false。
pidFilePath:<路径>
描述:配合"fork:true"参数,将mongod/mongos进程ID写入指定的文件,如果不指定,将不会创建PID文件。
2、net:
bindIp: <127.0.0.1>
描述:mongod/monogs进程绑定的IP,application通过此IP、port建立链接。可以绑定在任意网卡接口上,如果你的mongos/mongod只需要内网访问,可以绑定在内网IP(例如:192.168.1.100),如果需要外网访问,那么则绑定外网IP,如果此值为“0.0.0.0”,则绑定到所有接口即内网、外网IP均可以访问。(不建议)可以绑定都多个ip上,ip地址之间用“,”分割。
port: 27017
描述:mongod/mongos侦听端口,默认为27017;不过因为mongodb有2种典型的架构模式:replica set和sharding,如果开发者在一个节点上部署多个mongod实例,需要注意修改此端口以避免冲突。
maxIncomingConnections: 65536
描述:mongod/mongos进程允许的最大连接数,如果此值超过操作系统配置的连接数阀值,将不会生效(ulimit);默认值为65536。通常客户端将会使用连接池机制,可以有效的控制每个客户端的链接个数。
wireObjectCheck: true
描述:当客户端写入数据时,mongos/mongod是否检测数据的有效性(BSON),如果数据格式不良,此insert、update操作将会被拒绝;默认值为true
ipv6: false
描述:是否支持mongos/mongod多个实例之间使用IPV6网络,默认值为false。此值需要在整个cluster中保持一致。
3、storage:
dbPath: db
描述:mongod进程存储数据目录,此配置仅对mongod进程有效。默认值为:/data/db。
indexBuildRetry: true
描述:当构建索引时mongod意外关闭,那么再次启动是否重新构建索引;索引构建失败,mongod重启后将会删除尚未完成的索引,但是否重建由此参数决定。默认值为true。
repairPath: _tmp
描述:配合--repair启动命令参数,在repair期间使用此目录存储临时数据,repair结束后此目录下数据将被删除,此配置仅对mongod进程有效。不建议在配置文件中配置,而是使用mongod启动命令指定。
engine: mmapv1
描述:存储引擎类型,mongodb 3.0之后支持“mmapv1”、“wiredTiger”两种引擎,默认值为“mmapv1”;官方宣称wiredTiger引擎更加优秀。
journal:
enabled: true
描述:是否开启journal日志持久存储,journal日志用来数据恢复,是mongod最基础的特性,通常用于故障恢复。64位系统默认为true,32位默认为false,建议开启,仅对mongod进程有效。
directoryPerDB: false
描述:是否将不同DB的数据存储在不同的目录中,dbPath的子目录,目录名为db的名称。对已经存储数据的mongod修改此值,需要首先使用mongodump指令将数据导出,然后关闭mongod,再修改此值和指定新的dbPath,然后使用mongorestore指令重新导入数据。(即导出数据,并使用mongorestore将数据重新写入mongod的新目录中)
对于replica set架构模式,只需要在每个secondary依次操作:关闭secondary,然后配置新的dbPath,然后启动即可(会执行初始化sync,从primary中将数据去完全同步到本地)。最后操作primary。
此参数仅对mongod进程有效,默认值为false,不建议修改此值
syncPeriodSecs: 60
描述:mongod使用fsync操作将数据flush到磁盘的时间间隔,默认值为60(单位:秒),强烈建议不要修改此值;mongod将变更的数据写入journal后再写入内存,并间歇性的将内存数据flush到磁盘中,即延迟写入磁盘,有效提升磁盘效率。此指令不影响journal存储,仅对mongod有效。
mmapv1:(如下配置仅对MMAPV1引擎生效)
quota:
enforced: false
描述:配额管理,是否限制每个DB所能持有的最大文件数量,仅对mongod有效,默认值为false,建议保持默认值。
maxFilesPerDB: 8
描述:如果enforce开启,每个DB所持有的存储文件不会超过此阀值。仅对mongod进程有效。
smallFiles: false
描述:是否使用小文件存储数据;如果此值为true,mongod将会限定每个数据文件的大小为512M(默认最大为2G),journal降低到128M(默认为1G)。如果DB的数据量较大,将会导致每个DB创建大量的小文件,这对性能有一定的影响。在production环境下,不建议修改此值,在测试时可以设置为true,节约磁盘。
journal:
commitIntervalMs: 100
描述:mongod进程提交journal日志的时间间隔,即fsync的间隔。考虑到磁盘效能,mongod间歇性的flush日志数据;此值越小,数据丢失的可能性越低,磁盘消耗越大,性能越低。如果希望write操作强制立即写入journal,可以传递参数选项“j:true”(在客户端write操作中指定此选项即可),此操作(包括此前尚未提交的)将会立即fsync到磁盘。仅对mongod有效,单位:毫秒
nsSize: 每个database的namespace文件的大小,默认为16,单位:M;最大值可以设置为2048,即dbpath下“.ns”后缀文件的大小。16M基本上可以保存24000条命名条目,新建一个collection或者index信息,即会增加一个namespace条目;如果你的database下需要创建大量的collection(比如数据分析),则可以适度调大此值。
wiredTiger:(如下配置仅对wiredTiger引擎生效(3.0以上版本)
engineConfig:
cacheSizeGB: 8
描述:wiredTiger缓存工作集(working set)数据的内存大小,单位:GB,此值决定了wiredTiger与mmapv1的内存模型不同,它可以限制mongod对内存的使用量,而mmapv1则不能(依赖于系统级的mmap)。默认情况下,cacheSizeGB的值为假定当前节点只部署一个mongod实例,此值的大小为物理内存的一半;如果当前节点部署了多个mongod进程,那么需要合理配置此值。如果mongod部署在虚拟容器中(比如,lxc,cgroups,Docker)等,它将不能使用整个系统的物理内存,则需要适当调整此值。默认值为物理内存的一半。
journalCompressor: snappy
描述:journal日志的压缩算法,可选值为“none”、“snappy”、“zlib”。
directoryForIndexes: false
描述:是否将索引和collections数据分别存储在dbPath单独的目录中。即index数据保存“index”子目录,collections数据保存在“collection”子目录。默认值为false,仅对mongod有效。
collectionConfig:
blockCompressor: snappy
描述:collection数据压缩算法,可选值“none”、“snappy”、“zlib”。开发者在创建collection时可以指定值,以覆盖此配置项。如果mongod中已经存在数据,修改此值不会带来问题,旧数据仍然使用原来的算法解压,新数据文件将会采用新的解压缩算法。
indexConfig:
prefixCompression: true
描述:是否对索引数据使用“前缀压缩”(prefix compression,一种算法)。前缀压缩,对那些经过排序的值存储,有很大帮助,可以有效的减少索引数据的内存使用量。默认值为true。
4、operationProfiling:
slowOpThresholdMs: 100
描述:数据库profiler判定一个操作是“慢查询”的时间阀值,单位毫秒;mongod将会把慢查询记录到日志中,即使profiler被关闭。当profiler开启时,慢查询记录还会被写入“system.profile”这个系统级的collection中。请参看mongod profiler相关文档。默认值为100,此值只对mongod进程有效。
mode: off
描述:数据库profiler级别,操作的性能信息将会被写入日志文件中,可选值:
1)off:关闭profiling
2)slowOp:on,只包含慢操作日志
3)all:on,记录所有操作
数据库profiling会影响性能,建议只在性能调试阶段开启。此参数仅对mongod有效。
5、replication:(复制集架构模式配置,如果只是单点,则无需配置)
oplogSizeMB: 10240
描述:replication操作日志的最大尺寸,单位:MB。mongod进程根据磁盘最大可用空间来创建oplog,比如64位系统,oplog为磁盘可用空间的5%,一旦mongod创建了oplog文件,此后再次修改oplogSizeMB将不会生效。此值不要设置的太小, 应该足以保存24小时的操作日志,以保证secondary有充足的维护时间;如果太小,secondary将不能通过oplog来同步数据,只能全量同步。此值仅对mongod有效。
enableMajorityReadConcern: false
描述:是否开启readConcern的级别为“majority”,默认为false;只有开启此选项,才能在read操作中使用“majority”。(3.2+版本)
replSetName: <无默认值>
描述:“复制集”的名称,复制集中的所有mongd实例都必须有相同的名字,sharding分布式下,不同的sharding应该使用不同的replSetName。仅对mongod有效。
secondaryIndexPrefetch: all
描述:只对mmapv1存储引擎有效。复制集中的secondary,从oplog中运用变更操作之前,将会先把索引加载到内存中,默认情况下,secondaries首先将操作相关的索引加载到内存,然后再根据oplog应用操作。可选值:
1)none:secondaries不将索引数据加载到内容
2)all:sencondaries将此操作有关的索引数据加载到内存
3)_id_only:只加载_id索引
默认值为:all,此配置仅对mongod有效。
localPingThresholdMs: 15
描述:ping时间,单位:毫秒,mongos用来判定将客户端read请求发给哪个secondary。仅对mongos有效。默认值为15,和客户端driver中的默认值一样。当mongos接收到客户端read请求,它将:
1、找出复制集中ping值最小的member。
2、将延迟值被此值允许的members,构建一个列表
3、从列表中随机选择一个member。
ping值是动态值,每10秒计算一次。mongos将客户端请求转发给延迟较小(与此值相比)的某个secondary节点。仅对mongos有效。
6、sharding:(仅对sharding架构模式下有效)
clusterRole: <无默认值>
描述:在sharding集群中,此mongod实例的角色,可选值:
1、configsvr:此实例为config server,此实例默认侦听27019端口
2、shardsvr:此实例为shard(分片),侦听27018端口
此配置仅对mongod有效。通常config server和sharding server需要使用各自的配置文件。
archiveMovedChunks: true
描述:当chunks因为“负载平衡”而迁移到其他节点时,mongod是否将这些chunks归档,并保存在dbPath下“moveChunk”目录下,mongod不会删除moveChunk下的文件。默认为true。
autoSplit: true
描述:是否开启sharded collections的自动分裂,仅对mongos有效。如果所有的mongos都设定为false,那么collections数据增长但不能分裂成新的chunks。因为集群中任何一个mongos进程都可以触发split,所以此值需要在所有mongos行保持一致。仅对mongos有效。
configDB: <无默认值>
描述:设定config server的地址列表,每个server地址之间以“,”分割,通常sharded集群中指定1或者3个config server。(生产环境,通常是3个config server,但1个也是可以的)。所有的mongos实例必须配置一样,否则可能带来不必要的问题。仅对mongos有效。
chunkSize: 64
描述:sharded集群中每个chunk的大小,单位:MB,默认为64,此值对于绝大多数应用而言都是比较理想的。chunkSize太大会导致分布不均,太小会导致分裂成大量的chunk而经常移动
##整个sharding集群中,此值需要保持一致,集群启动后修改此值将不再生效。仅对mongos有效。
7、sytemsLog:(系统日志,必须配置)
verbosity: 0
描述:日志级别,0:默认值,包含“info”信息,1~5,即大于0的值均会包含debug信息
quiet: true
描述:"安静",此时mongod/mongos将会尝试减少日志的输出量。不建议在production环境下开启,否则将会导致跟踪错误比较困难。
traceAllExceptions: true
描述:打印异常详细信息。
path: logs/mongod.log
logAppend: false
描述:如果为true,当mongod/mongos重启后,将在现有日志的尾部继续添加日志。否则,将会备份当前日志文件,然后创建一个新的日志文件;默认为false。
logRotate: rename
描述:日志“回转”,防止一个日志文件特别大,则使用logRotate指令将文件“回转”,可选值:
1)rename:重命名日志文件,默认值。
2)reopen:使用linux日志rotate特性,关闭并重新打开此日志文件,可以避免日志丢失,但是logAppend必须为true。
destination: file
描述:日志输出目的地,可以指定为“ file”或者“syslog”,表述输出到日志文件,如果不指定,则会输出到标准输出中(standard output)。
重要配置参数讲解
1.2.3 与安全有关的配置(摘要介绍)
security:
authorization: enabled
clusterAuthMode: keyFile
keyFile: /srv/mongodb/keyfile
javascriptEnabled: true
setParameter:
enableLocalhostAuthBypass: true
authenticationMechanisms: SCRAM-SHA-1
1)authorization:disabled或者enabled,仅对mongod有效;表示是否开启用户访问控制(Access Control),即客户端可以通过用户名和密码认证的方式访问系统的数据,默认为“disabled”,即客户端不需要密码即可访问数据库数据。(限定客户端与mongod、mongos的认证)
2)clusterAuthMode:集群中members之间的认证模式,可选值为“keyFile”、“sendKeyFile”、“sendX509”、“x509”,对mongod/mongos有效;默认值为“keyFile”,mongodb官方推荐使用x509,不过我个人觉得还是keyFile比较易于学习和使用。不过3.0版本中,mongodb增加了对TLS/SSL的支持,如果可以的话,建议使用SSL相关的配置来认证集群的member,此文将不再介绍。(限定集群中members之间的认证)
3)keyFile:当clusterAuthMode为“keyFile”时,此参数指定keyfile的位置,mongodb需要有访问此文件的权限。
4)javascriptEnabled:true或者false,默认为true,仅对mongod有效;表示是否关闭server端的javascript功能,就是是否允许mongod上执行javascript脚本,如果为false,那么mapreduce、group命令等将无法使用,因为它们需要在mongod上执行javascript脚本方法。如果你的应用中没有mapreduce等操作的需求,为了安全起见,可以关闭javascript。
“setParameter”允许指定一些的Server端参数,这些参数不依赖于存储引擎和交互机制,只是微调系统的运行状态,比如“认证机制”、“线程池参数”等。参见【parameter】
1)enableLocalhostAuthBypass:true或者false,默认为true,对mongod/mongos有效;表示是否开启“localhost exception”,对于sharding cluster而言,我们倾向于在mongos上开启,在shard节点的mongod上关闭。
2)authenticationMechanisms:认证机制,可选值为“SCRAM-SHA-1”、“MONGODB-CR”、“PLAN”等,建议为“SCRAM-SHA-1”,对mongod/mongos有效;一旦选定了认证机制,客户端访问databases时需要与其匹配才能有效。
与安全有关的配置
1.2.4 与性能有关的参数
setParameter: connPoolMaxShardedConnsPerHost: 200 connPoolMaxConnsPerHost: 200 notablescan: 0 1)connPoolMaxShardedConnsPerHost:默认值为200,对mongod/mongos有效;表示当前mongos或者shard与集群中其他shards链接的链接池的最大容量,此值我们通常不会调整。连接池的容量不会阻止创建新的链接,但是从连接池中获取链接的个数不会超过此值。维护连接池需要一定的开支,保持一个链接也需要占用一定的系统资源。 2)connPoolMaxConnsPerHost:默认值为200,对mongod/mongos有效;同上,表示mongos或者mongod与其他mongod实例之间的连接池的容量,根据host限定。
与性能有关的参数
1.2.5 配置样例
mongodb 3.0之后配置文件采用YAML格式,这种格式非常简单,使用<key>:<value>表示,开头使用“空格”作为缩进。需要注意的是,“:”之后有value的话,需要紧跟一个空格,如果key只是表示层级,则无需在“:”后增加空格(比如:systemLog:后面既不需要空格)。按照层级,每行4个空格缩进,第二级则8个空格,依次轮推,顶层则不需要空格缩进。如果格式不正确,将会出现如下错误:

1.2.5.1 mongod.conf
systemLog:
quiet: false
path: /data/mongodb/logs/mongod.log
logAppend: false
destination: file
processManagement:
fork: true
pidFilePath: /data/mongodb/mongod.pid
net:
bindIp: 127.0.0.1
port: 27017
maxIncomingConnections: 65536
wireObjectCheck: true
ipv6: false
storage:
dbPath: /data/mongodb/db
indexBuildRetry: true
journal:
enabled: true
directoryPerDB: false
engine: mmapv1
syncPeriodSecs: 60
mmapv1:
quota:
enforced: false
maxFilesPerDB: 8
smallFiles: true
journal:
commitIntervalMs: 100
wiredTiger:
engineConfig:
cacheSizeGB: 8
journalCompressor: snappy
directoryForIndexes: false
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
operationProfiling:
slowOpThresholdMs: 100
mode: off
mongod.conf
如果你的架构模式为replication Set,那么还需要在所有的“复制集”members上增加如下配置:
replication:
oplogSizeMB: 10240
replSetName: rs0
secondaryIndexPrefetch: all
如果为sharding Cluster架构,则需要在shard节点增加如下配置:
sharding:
clusterRole: shardsvr
archiveMovedChunks: true
当然,一个mongod实例即可以为“复制集”的member之一,也可以作为sharding集群中的一个分片,这取决你的架构模式。
mongod进程可以做为“config server”实例,只需要将“clusterRole: configsvr”即可;由此可见,一个mongod实例可以为“单点实例”、“config server”、“sharding server” + “replication set member”其中一个角色,建议使用不同的配置文件启动它。
1.2.5.2 mongos.conf
systemLog:
quiet: false
path: /data/mongodb/logs/mongod.log
logAppend: false
destination: file
processManagement:
fork: true
pidFilePath: /data/mongodb/mongod.pid
net:
bindIp: 127.0.0.1
port: 37017
maxIncomingConnections: 65536
wireObjectCheck: true
ipv6: false
replication:
localPingThresholdMs: 15
sharding:
autoSplit: true
configDB: m1.com:27018,m2.com:27018,m3.com:27018
chunkSize: 64
mongos.conf
mongos实例不需要存储实际的数据,对内存有一定的消耗,在sharding架构模式下使用;mongos需接收向客户端请求(后端的sharded和replication set则不需要让客户端知道),它可以将客户端请求转发到一个分片集群上(分片集群基于复制集)延迟相对较小的secondary上,同时还负责chunk的分裂和迁移工作。
1.3 其它
1.3.1 启动与关闭
配置文件中绝大部分参数,都可以通过进程启动命令指定,通常启动命令行中的参数将覆盖配置文件中的参数。
./mongod -f mongod.conf
当然,也可以通过使用多个命令行参数来启动,如下仅为示例:
./mongod --bind_ip 127.0.0.1 --port 27017 --dbpath /data/mongodb/db --logpath /data/mongodb/logs --storageEngine mmapv1 --fork
mongod配置中所指定的目录地址必须首先创建,否则将无法启动,这有别与其他系统
mongos启动方式同上。如果希望基于service方式启动mongod、mongos,请参考其他文档。
可以通过kill指令来关闭mongod进程,不过这种方式有些粗暴,在production环境中可能会导致数据损坏,建议使用mongo shell来“cleanly”关闭mongod进程,这种方式安全而且不会导致数据损坏。
./mongo
> use admin;
> db.shutdownServer();
可以使用“kill <mongod process ID>”的方式关闭,这种方式也是“cleanly”;如果使用“kill -9 ”方式就是强制线程退出,可能会导致数据丢失。如果在非fork下运行mongod,直接在shell上使用“CTRL-C”方式也是“cleanly”退出。对于线上环境,最好不要“kill -9”。
1.3.2 Repair
“修复”数据库,当mongodb运行一段时间之后,特别是经过大量删除、update操作之后,我们可以使用repair指令对数据存储进行“repair”,它将整理、压缩底层数据存储文件,重用磁盘空间,相当于数据重新整理了一遍,对数据优化有一定的作用。
如果mongod没有开启journaling日志功能,repair指令可以在系统异常crash之后,用于整理数据、消除损坏数据;如果开启了journaling日志功能,我们则需不要使用repair来修复数据,因为journal就可以帮助mongod恢复数据。在replication set模式下,可以使用repair,但是通常可以直接删除旧数据,使用“数据同步”操作,即可达到“恢复”、“整理”数据的目的,效果和repair一样,而且效率更高。
repair需要磁盘有一定的剩余空间,为当前database数据量 + 2GB,可以通过使用“--repairpath”来指定repair期间存储临时数据的目录。repair指令还会重建indexes,可以降低索引的数据大小。
如果mongod意外crash,需要首先正常启动mongod,让根据journal日志恢复完数据之后,才能执行repair;如果journal日志有数据尚未恢复,那么使用repair指令启动mongod将会失败。
repair时需要关闭mongod进程,执行完毕后再启动。
./mongod --dbpath=/data/mongodb/db --repair
mongodb比较倾向于使用shell来repair特定的database,这个操作相对比较可控,其内部工作机制一样。
>./mongo
>user mydatabase;
>db.repairDatabase();
1.3.3 mongodump与mongorestore
我们通常会使用到mongodb数据的备份功能,或者将一个备份导入到一个新的mongod实例中(数据冷处理),那么就需要借助这两个指令。
mongodump将整个databases全部内容导出到一个二进制文件中,可以在其他mongod使用mongorestore来加载整个文件。需要注意mongodump不会导出“local”数据库中的数据,当然这个local库对恢复数据也没有太大意义。
“-u”参数指定访问database的用户名,“-p”指定密码,“--host”和“--port”指定mongod实例的位置,“--db”指定需要dump的数据库,如果不指定则dump所有数据库,“--collection”指定需要dump的集合表,如果不指定则dumpl整个db下的所有collections;“--query <json>”指定dump时的查询条件,“--out”指定结果输出文件的路径:
>./mongodump --host m1.com --port 27017 -u root -p pass --out /data/mongodb/backup/dump_2015_10_10
mongorestore则将dump的数据文件导入到database,mongorestore可以创建新的database或者将数据添加到现有的database中。如果将数据restore到已经存在的database中,mongorestore仅执行insert,不会执行update,如果数据库中已经存在相同的“_id”数据,mongorestore不会覆盖原有的document。mongorestore会重新创建indexes,所有的操作都是insert而不会update。
基本指令类似于mongodump,“--db”指定需要将数据restore到哪个db中,如果此db不存在,则创建;如果没有指定“--db”,mongorestore则根据原始数据所属的db重新创建,这可能会导致数据覆盖。“--drop”表示在restore数据之前,首先删除目标db中原有的collections,--drop不会删除那些在dump文件中没有的collection。“--stopOnError”表示出错时强制退出。
./mongorestore --db mydatabase /data/mongodb/backup/dump_2015_10_10
1.3.4 mongoimport和mongoexport
mongoexport将数据导出为JSON或者CSV格式,以便其他应用程序解析。
因为mongodb数据是BSON格式,有些数据类型是JSON不具有的,所以导出JSON格式会仍然会丢失数据类型;所以如果导出的数据是准备给其他mongodb恢复数据,那么建议使用mongodump和mongorestore。
命令参数同3.1.3.3)
1.3.5 mongostat
可以间歇性的打印出当前mongod实例中“数据存储”、“flush”、读写次数、网络输出等参数,是查看mongod性能的有效手段。mongotop可以根据查看各个database下读写情况。
1.3.6 mongo shell操作简述
1)help:列出所有的function
2)show dbs:展示当前实例中所有的databases。
3)use <dbname>:切换到指定的db,接下来的操作将会在此db中。
4)show collections:展示出当前db中所有的collections。
5)show users:展示当前db中已经添加的所有用户。
6)show roles:展示当前db中所有内置的或者自定义的用户角色。
7)show profile:这涉及到profile相关的配置,默认情况下展示出最近5个操作耗时超过1秒的操作,通常用于跟踪慢查询。
8)db.help():展示出可以在db上进行的操作function。
9)db.<collection>.help():展示出可以在colleciton上进行的操作。
1.4 Mongo3.x 角色说明
|
角色分类 |
角色 |
权限及角色 (本文大小写可能有些变化,使用时请参考官方文档) |
|
Database User Roles |
read |
CollStats,dbHash,dbStats,find,killCursors,listIndexes,listCollections |
|
readWrite |
CollStats,ConvertToCapped,CreateCollection,DbHash,DbStats, DropCollection,CreateIndex,DropIndex,Emptycapped,Find, Insert,KillCursors,ListIndexes,ListCollections,Remove, RenameCollectionSameDB,update |
|
|
Database Administration Roles |
dbAdmin |
collStats,dbHash,dbStats,find,killCursors,listIndexes,listCollections, dropCollection 和 createCollection 在 system.profile |
|
dbOwner |
角色:readWrite, dbAdmin,userAdmin |
|
|
userAdmin |
ChangeCustomData,ChangePassword,CreateRole,CreateUser, DropRole,DropUser,GrantRole,RevokeRole,ViewRole,viewUser |
|
|
Cluster Administration Roles |
clusterAdmin |
角色:clusterManager, clusterMonitor, hostManager |
|
clusterManager |
AddShard,ApplicationMessage,CleanupOrphaned,FlushRouterConfig, ListShards,RemoveShard,ReplSetConfigure,ReplSetGetStatus, ReplSetStateChange,Resync, EnableSharding,MoveChunk,SplitChunk,splitVector |
|
|
clusterMonitor |
connPoolStats,cursorInfo,getCmdLineOpts,getLog,getParameter, getShardMap,hostInfo,inprog,listDatabases,listShards,netstat, replSetGetStatus,serverStatus,shardingState,top collStats,dbStats,getShardVersion |
|
|
hostManager |
applicationMessage,closeAllDatabases,connPoolSync,cpuProfiler, diagLogging,flushRouterConfig,fsync,invalidateUserCache,killop, logRotate,resync,setParameter,shutdown,touch,unlock |
|
|
Backup and Restoration Roles |
backup |
提供在admin数据库mms.backup文档中insert,update权限 列出所有数据库:listDatabases 列出所有集合索引:listIndexes 对以下提供查询操作:find *非系统集合 *系统集合:system.indexes, system.namespaces, system.js *集合:admin.system.users 和 admin.system.roles |
|
restore |
非系统集合、system.js,admin.system.users 和 admin.system.roles 及2.6 版本的system.users提供以下权限: collMod,createCollection,createIndex,dropCollection,insert 列出所有数据库:listDatabases system.users :find,remove,update |
|
|
All-Database Roles |
readAnyDatabase |
提供所有数据库中只读权限:read 列出集群所有数据库:listDatabases |
|
readWriteAnyDatabase |
提供所有数据库读写权限:readWrite 列出集群所有数据库:listDatabases |
|
|
userAdminAnyDatabase |
提供所有用户数据管理权限:userAdmin Cluster:authSchemaUpgrade,invalidateUserCache,listDatabases admin.system.users和admin.system.roles: collStats,dbHash,dbStats,find,killCursors,planCacheRead createIndex,dropIndex |
|
|
dbAdminAnyDatabase |
提供所有数据库管理员权限:dbAdmin 列出集群所有数据库:listDatabases |
|
|
Superuser Roles |
root |
角色:dbOwner,userAdmin,userAdminAnyDatabase readWriteAnyDatabase, dbAdminAnyDatabase, userAdminAnyDatabase,clusterAdmin |
|
Internal Role |
__system |
集群中对任何数据库采取任何操作 |
2. Mongo 3.X版本源码安装
由于Mongo3.X的yum 如果从官网安装,那么下载速度会很慢,所以这里使用源码安装的方式,文件夹以及配置文件、环境变量服务控制脚本这里需要自己准备。
1.首先解压Mongo3.X源码包,然后创建目录文件。
[root@CentOS7 tools]# tar zxf mongodb-linux-x86_64-3.4.10.tgz -C /usr/local/
[root@CentOS7 tools]# mv /usr/local/mongodb-linux-x86_64-3.4.10/ /usr/local/mongodb
[root@CentOS7 /]# mkdir -p /usr/local/mongodb/{conf,data,keyfile,logs,tmp}
2. 将mongodb的bin加入环境变量
[root@CentOS7 /]# echo 'export PATH=$PATH:/usr/local/mongodb/bin' >> /etc/profile ; source /etc/profile
3. Mongod配置文件。
这里其它不做配置,保证环境能正常运行即可
因为这里拷贝的配置是yum文件自带配置,所以这里的配置信息大多数保持默认
[root@CentOS7 /]# egrep -v "^#|^$" /etc/mongod.conf.bak
systemLog:
destination: file
logAppend: true
path: /usr/local/mongodb/logs/mongod.log
storage:
dbPath: /usr/local/mongodb/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /usr/local/mongodb/tmp/mongod.pid # location of pidfile
net:
port: 27017
bindIp: 0.0.0.0 # Listen to local interface only, comment to listen on all interfaces.
security:
authorization: enabled
4. Mongodo服务脚本
Centos6
由于centos6一般使用yum文件,里面已经自带了方法,但为了防止centos6安装3.X版本,这里贴出一份服务脚本供参考。
#!/bin/sh
#
#mongod - Startup script for mongod
#
# chkconfig: - 85 15
# description: Mongodb database.
# processname: mongod # Source function library
. /etc/rc.d/init.d/functions # things from mongod.conf get there by mongod reading it
# OPTIONS
OPTIONS=" -f /etc/mongod.conf" #mongod
mongod="/usr/local/mongodb/bin/mongod" lockfile=/usr/local/mongodb/keyfile/mongod start()
{
echo -n $"Starting mongod: "
$mongod $OPTIONS
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && touch $lockfile
} stop()
{
echo -n $"Stopping mongod: "
killproc $mongod -QUIT
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && rm -f $lockfile
} restart () {
stop
start
} ulimit -n 12000
RETVAL=0 case "$1" in
start)
start
;;
stop)
stop
;;
restart|reload|force-reload)
restart
;;
condrestart)
[ -f $lockfile ] && restart || :
;;
status)
status $mongod
RETVAL=$?
;;
*)
echo "Usage: $0 {start|stop|status|restart|reload|force-reload|condrestart}"
RETVAL=1
esac exit $RETVAL
mongod
Centos7
Centos7方式已全部改变,请参考Centos7 system 服务文档。这里贴出一个centos7 mongod的控制脚本
[Unit]
Description=mongo
After=network.target [Service]
Type=forking
PIDFile=/usr/local/mongodb/tmp/mongod.pid
ExecStart=/usr/local/mongodb/bin/mongod -f /etc/mongod.conf.bak
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true [Install]
WantedBy=multi-user.target
mongod.service
5. (可选)或者直接使用命令
mongod -f 配置文件
3. Mongo 3.X常用操作
3.1 MongoDB数据建模
MongoDB中的数据具有灵活的模式。文档在同一集合,但它们不需要具有相同的字段或结构集合,集合文档中的公共字段可以包含不同类型的数据。
MongoDB中的数据具有灵活的模式。与SQL数据库不同,SQL数据库必须在插入数据之前确定和声明表的模式,MongoDB的集合不会强制执行文档结构。这种灵活性有助于将文档映射到实体或对象。 每个文档可以匹配表示实体的数据字段,即使数据具有实质性的变化。然而,集合中的文档具有类似的结构。
数据建模中的关键挑战是平衡应用程序的需求,数据库引擎的性能特征和数据检索模式。 在设计数据模型时,请始终考虑数据的应用程序使用情况(即数据的查询,更新和处理)以及数据本身的固有结构。
在MongoDB中设计架构时有一些考虑:
- 根据用户要求设计架构。
- 将对象合并到一个文档中,否则分开它们(但确保不需要连接)。
- 复制数据(但有限制),因为与计算时间相比,磁盘空间便宜。
- 在写入时加入,而不是读取时加入。
- 为最常用的用例优化架构。
- 在模式中执行复杂聚合。
实例
假设客户需要他的博客/网站的数据库设计,并查看RDBMS和MongoDB架构设计之间的区别。网站有以下要求。
- 每个帖子都有唯一的标题,描述和网址。
- 每个帖子都可以有一个或多个标签。
- 每个帖子都有其发布者的名称和总人数。
- 每个帖子都有用户给出的评论以及他们的姓名,消息,数据时间和喜好。
- 每个帖子可以有零个或多个评论。
在RDBMS架构中,上述要求的设计将具有最少的三个表。表与表之间的关系如下 -
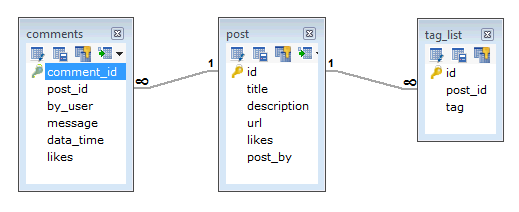
而在MongoDB模式中,设计将有一个集合post,其结构以下 –
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}
通过上面的示例说明可以知道,在显示数据时,在RDBMS中需要连接三个表,而在MongoDB中,数据将仅显示在一个集合中
3.2 MongoDB创建数据库
- use命令
MongoDB使用 use DATABASE_NAME 命令来创建数据库。如果指定的数据DATABASE_NAME不存在,则该命令将创建一个新的数据库,否则返回现有的数据库。
语法
use DATABASE语句的基本语法如下 -
use DATABASE_NAME
示例
如果要创建一个名称为<newdb>的数据库,那么使用use DATABASE语句将如下所示:
> use lizexiong
switched to db lizexiong
要检查当前选择的数据库,请使用 db 命令 -
>db
newdb
如果要检查数据库列表,请使用命令:show dbs。
>show dbs
local 0.000025GB
test 0.00002GB
创建的数据库(newdb)不在列表中。要显示数据库,需要至少插入一个文档,空的数据库是不显示出来的。
>db.name.insert({"name":" lizexiong"})
>show dbs
local 0.00005GB
test 0.00002GB
lizexiong 0.00002GB
在 MongoDB 中默认数据库是:test。 如果您还没有创建过任何数据库,则集合/文档将存储在test数据库中。
3.3 MongoDB删除数据库
- db.dropDatabase()方法
MongoDB中的 db.dropDatabase()命令用于删除现有的数据库。
db.dropDatabase()
这将删除当前所选数据库。如果没有选择任何数据库,那么它将删除默认的’test‘数据库。
示例
首先,使用命令show dbs检查可用数据库的列表
> show dbs;
admin 0.000GB
lizexiong 0.000GB
local 0.000GB
> use lizexiong
switched to db lizexiong
> db.dropDatabase()
{ "dropped" : "lizexiong", "ok" : 1 } #最后检查结果
> show dbs
admin 0.000GB
local 0.000GB
3.4 MongoDB创建集合
MongoDB 的db.createCollection(name,options)方法用于在MongoDB 中创建集合。
- 语法
createCollection()命令的基本语法如下
db.createCollection(name, options)
在命令中,name 是要创建的集合的名称。options是一个文档,用于指定集合的配置。
|
参数 |
类型 |
描述 |
|
name |
String |
要创建的集合的名称 |
|
options |
Document |
(可选)指定有关内存大小和索引的选项 |
options参数是可选的,因此只需要指定集合的名称。 以下是可以使用的选项列表:
|
capped |
Boolean |
(可选)如果为true,则启用封闭的集合。上限集合是固定大小的集合,它在达到其最大大小时自动覆盖其最旧的条目。 如果指定true,则还需要指定size参数。 |
|
autoIndexId |
Boolean |
(可选)如果为true,则在_id字段上自动创建索引。默认值为false。 |
|
size |
数字 |
(可选)指定上限集合的最大大小(以字节为单位)。 如果capped为true,那么还需要指定此字段的值。 |
|
max |
数字 |
(可选)指定上限集合中允许的最大文档数。 |
在插入文档时,MongoDB首先检查上限集合capped字段的大小,然后检查max字段。
例子
没有使用选项的createCollection()方法的基本语法如下
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
可以使用命令show collections检查创建的集合。
>show collections
mycollection
以下示例显示了createCollection()方法的语法,其中几个重要选项
> db.createCollection("mycol", {capped : true, autoIndexId : true, size : 6142800, max : 10000 })
{ "ok" : 1 }
在 MongoDB 中,不需要创建集合。当插入一些文档时,MongoDB 会自动创建集合。
>db.newcollection.insert({"name" : "lizexiong"})
>show collections
mycol
newcollection
mycollection
3.5 MongoDB删除集合
- drop()方法
MongoDB 的 db.collection.drop() 用于从数据库中删除集合。
语法
drop()命令的基本语法如下
db.COLLECTION_NAME.drop()
示例
首先,检查数据库 test 中可用的集合。
>use test
switched to db test
> show collections
mycol
mycollection
newcollection
现在删除名称为mycollection 的集合。
>db.mycollection.drop()
true
如果选定的集合成功删除,drop()方法将返回true,否则返回false。
3.6 MongoDB数据类型
MongoDB支持许多数据类型。 其中一些是
- 字符串 - 这是用于存储数据的最常用的数据类型。MongoDB中的字符串必须为UTF-8。
- 整型 - 此类型用于存储数值。 整数可以是32位或64位,具体取决于服务器。
- 布尔类型 - 此类型用于存储布尔值(true / false)值。
- 双精度浮点数 - 此类型用于存储浮点值。
- 最小/最大键 - 此类型用于将值与最小和最大BSON元素进行比较。
- 数组 - 此类型用于将数组或列表或多个值存储到一个键中。
- 时间戳 - ctimestamp,当文档被修改或添加时,可以方便地进行录制。
- 对象 - 此数据类型用于嵌入式文档。
- 对象 - 此数据类型用于嵌入式文档。
- Null - 此类型用于存储Null值。
- 符号 - 该数据类型与字符串相同; 但是,通常保留用于使用特定符号类型的语言。
- 日期 - 此数据类型用于以UNIX时间格式存储当前日期或时间。您可以通过创建日期对象并将日,月,年的日期进行指定自己需要的日期时间。
- 对象ID - 此数据类型用于存储文档的ID。
- 二进制数据 - 此数据类型用于存储二进制数据。
- 代码 - 此数据类型用于将JavaScript代码存储到文档中。
- 正则表达式 - 此数据类型用于存储正则表达式
3.7 MongoDB插入文档
- insert()方法
要将数据插入到 MongoDB 集合中,需要使用 MongoDB 的 insert()或save()方法。
语法
insert()命令的基本语法如下:
>db.COLLECTION_NAME.insert(document)
示例
db.mycol.insert({
_id: 100,
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'yiibai tutorials',
url: 'http://www.huawei.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
})
这里mycol是集合的名称,在前一章中所创建的。如果数据库中不存在集合,则MongoDB将创建此集合,然后将文档插入到该集合.
在插入的文档中,如果不指定_id参数,那么 MongoDB 会为此文档分配一个唯一的ObjectId。_id为集合中的每个文档唯一的12个字节的十六进制数。 12字节划分如下 -
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id,
3 bytes incrementer)
要在单个查询中插入多个文档,可以在insert()命令中传递文档数组。如下所示
> db.mycol.insert([
{
_id: 101,
title: 'MongoDB Guide',
description: 'MongoDB is no sql database',
by: 'yiibai tutorials',
url: 'http://www.huawei.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: 102,
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'yiibai tutorials',
url: 'http://www.huawei.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 210,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2017,11,10,2,35),
like: 0
}
]
},
{
_id: 104,
title: 'Python Quick Guide',
description: "Python Quick start ",
by: 'yiibai tutorials',
url: 'http://www.huawei.com',
tags: ['Python', 'database', 'NoSQL'],
likes: 30,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2018,11,10,2,35),
like: 590
}
]
}
])
成功结果为:
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 3,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
要插入文档,也可以使用db.post.save(document)。 如果不在文档中指定_id,那么save()方法将与insert()方法一样自动分配ID的值。如果指定_id,则将以save()方法的形式替换包含_id的文档的全部数据。
3.8 MongoDB其它插入文档的方法
- db.collection.insertOne()方法
db.collection.insertOne()方法将单个文档插入到集合中。以下示例将新文档插入到库存集合中。 如果文档没有指定_id字段,MongoDB会自动将_id字段与ObjectId值添加到新文档。
db.inventory.insertOne(
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
)
db.collection.insertOne()方法返回包含新插入的文档的`_id```字段值的文档。
执行结果如下
> db.inventory.insertOne(
... { item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
... )
{
"acknowledged" : true,
"insertedId" : ObjectId("5a5719d8ddd1e4ed6d858660")
- db.collection.insertMany()方法
db.collection.insertMany()方法将多个文档插入到集合中,可将一系列文档传递给db.collection.insertMany()方法。以下示例将三个新文档插入到库存集合中。如果文档没有指定_id字段,MongoDB会向每个文档添加一个ObjectId值的_id字段。
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], size: { h: 14, w: 21, uom: "cm" } },
{ item: "mat", qty: 85, tags: ["gray"], size: { h: 27.9, w: 35.5, uom: "cm" } },
{ item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h: 19, w: 22.85, uom: "cm" } }
])
insertMany()返回包含新插入的文档_id字段值的文档。执行结果如下
> db.inventory.insertMany([
... { item: "journal", qty: 25, tags: ["blank", "red"], size: { h: 14, w: 21, uom: "cm" } },
... { item: "mat", qty: 85, tags: ["gray"], size: { h: 27.9, w: 35.5, uom: "cm" } },
... { item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h: 19, w: 22.85, uom: "cm" } }
... ])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5a571a8addd1e4ed6d858661"),
ObjectId("5a571a8addd1e4ed6d858662"),
ObjectId("5a571a8addd1e4ed6d858663")
]
}
3.9 MongoDB查询文档
- find()方法
要从MongoDB集合查询数据,需要使用MongoDB的find()方法。
语法
find()命令的基本语法如下:
>db.COLLECTION_NAME.find(document)
Shell
find()方法将以非结构化的方式显示所有文档。
- pretty()方法
要以格式化的方式显示结果,可以使用pretty()方法。
语法
> db.mycol.find().pretty()
示例
>db.mycol.find().pretty()
{
"_id": 100,
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "yiibai tutorials",
"url": "http://www.huawei.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
除了find()方法外,还有一个findOne()方法,它只返回一个文档。
- MongoDB 与 RDBMS的等效 Where 子句
要在一些条件的基础上查询文档,可以使用以下操作。
|
操作 |
语法 |
示例 |
RDBMS等效语句 |
|
相等 |
{<key>:<value>} |
db.mycol.find({"by":"yiibai"}).pretty() |
where by = 'yiibai' |
|
小于 |
{<key>:{$lt:<value>}} |
db.mycol.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
|
小于等于 |
{<key>:{$lte:<value>}} |
db.mycol.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
|
大于 |
{<key>:{$gt:<value>}} |
db.mycol.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
|
大于等于 |
{<key>:{$gte:<value>}} |
db.mycol.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
|
不等于 |
{<key>:{$ne:<value>}} |
db.mycol.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
下面我们将对上表中的所有操作演示
MongoDB中的AND操作符
语法
在find()方法中,如果通过使用’,‘将它们分开传递多个键,则 MongoDB 将其视为AND条件。 以下是AND的基本语法 -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()
示例
以下示例将显示由“yiibai tutorials”编写并且标题为“MongoDB Overview”的所有教程。
> db.mycol.find({$and:[{"by":"yiibai tutorials"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id" : 100,
"title" : "MongoDB Overview",
"description" : "MongoDB is no sql database",
"by" : "yiibai tutorials",
"url" : "http://www.huawei.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
对于上面给出的例子,等效的SQL where子句是
SELECT * FROM mycol where by ='yiibai tutorials' AND title ='MongoDB Overview'
可以在find子句中传递任意数量的键值。
MongoDB中的OR操作符
语法
在要根据OR条件查询文档,需要使用$or关键字。 以下是OR条件的基本语法
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
示例
以下示例将显示由“yiibai tutorials”编写或标题为“MongoDB Overview”的所有教程。
> db.mycol.find({$or:[{"by":"yiibai tutorials"},{"title": "MongoDB Overview"}]}).pretty()
使用 AND 和 OR 条件一起
示例
以下示例将显示likes大于10以及标题是“MongoDB Overview”或者“yiibai tutorials”的所有文档。 等价SQL where子句为
SELECT * FROM mycol where likes> 10 AND(by ='yiibai tutorials' OR title ='MongoDB Overview')
db.mycol.find({"likes": {$gt:10}, $or: [{"by": "yiibai tutorials"},
{"title": "MongoDB Overview"}]}).pretty()
- 查询嵌入/嵌套文档
这里演示如何使用:db.collection.find()方法对嵌入/嵌套文档的查询操作的示例。 此页面上的示例使用inventory集合。要填充库存(inventory)集合以准备一些数据,请运行以下命令:
db.inventory.insertMany( [
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);
- 匹配嵌入/嵌套文档
要在作为嵌入/嵌套文档的字段上指定相等条件,请使用查询过滤器文档{<field>:<value>},其中<value>是要匹配的文档。
例如,以下查询选择字段size等于{ h: 14, w: 21, uom: "cm" }的所有文档:
> db.inventory.find( { size: { h: 14, w: 21, uom: "cm" } } )
{ "_id" : ObjectId("5a572a08ddd1e4ed6d858664"), "item" : "journal", "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "status" : "A" }
整个嵌入式文档中的相等匹配需要精确匹配指定的<value>文档,包括字段顺序。
例如,以下查询与库存(inventory)集合中的任何文档不匹配:
db.inventory.find( { size: { w: 21, h: 14, uom: "cm" } } )
- 使用查询运算符指定匹配
查询过滤器文档可以使用查询运算符来指定,如以下形式的条件:
{ <field1>: { <operator1>: <value1> }, ... }
以下查询使用size字段中嵌入的字段h中的小于运算符($lt):
db.inventory.find( { "size.h": { $lt: 15 } } )
- 指定AND条件
以下查询选择嵌套字段h小于15的所有文档,嵌套字段uom等于“in”,status字段等于“D”:
db.inventory.find( { "size.h": { $lt: 15 }, "size.uom": "in", status: "D" } )
3.10 MongoDB更新文档
MongoDB的update()和save()方法用于将集合中的文档更新。update()方法更新现有文档中的值,而save()方法使用save()方法中传递的文档数据替换现有文档。
- MongoDB Update()方法
语法
update()方法的基本语法如下
> db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)
示例
考虑mycol集合具有以下数据(以下数据只是一部分,并非查询出来的)
db.mycol.find({}, {'_id':1, 'title':1})
{ "_id" : 100, "title" : "MongoDB Overview" }
{ "_id" : 101, "title" : "MongoDB Guide" }
{ "_id" : 102, "title" : "NoSQL Database" }
{ "_id" : 104, "title" : "Python Quick Guide" }
以下示例将为标题为“MongoDB Overview”的文档设置为“New Update MongoDB Overview”。
> db.mycol.find({'title':'MongoDB Overview'},{'_id':1, 'title':1})
{ "_id" : 100, "title" : "MongoDB Overview" }
> # 更新操作
> db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New Update MongoDB Overview'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> # 查询更新后的结果 -
> db.mycol.find({'_id':100},{'_id':1, 'title':1})
{ "_id" : 100, "title" : "New Update MongoDB Overview" }
3.11 MongoDB删除文档
- remove()方法
MongoDB中的 remove()方法用于从集合中删除文档。 remove()方法接受两个参数。 一个是删除条件,第二个是标志:justOne。
- criteria - (可选)符合删除条件的集合将被删除。
- justOne - (可选)如果设置为true或1,则只删除一个文档。
语法
remove()方法的基本语法如下
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
示例
以下示例将删除_id为“100”的文档。
> db.mycol.remove({'_id':100})
WriteResult({ "nRemoved" : 1 })
- 只删除一条文档记录
如果有多条记录,并且只想删除第一条记录,则在remove()方法中设置justOne参数。
- 删除所有文档记录
如果不指定删除条件,MongoDB 将删除集合中的所有文档。 这相当于SQL的truncate命令。
>db.mycol.remove({})
3.12 MongoDB投影(选择字段)
在MongoDB中,投影表示仅选择所需要字段的数据,而不是选择整个文档字段的数据。如果某个文档有5个字段,但只要显示3个字段,那么就只选择3个字段吧,这样做是非常有好处的。
- find()方法
MongoDB的find()方法,在 MongoDB 查询文档中此方法接收的第二个可选参数是要检索的字段列表。 在MongoDB中,当执行find()方法时,它默认将显示文档的所有字段。为了限制显示的字段,需要将字段列表对应的值设置为1或0。1用于显示字段,而0用于隐藏字段。
具有投影的find()方法的基本语法如下:
语法
>db.COLLECTION_NAME.find({},{KEY:1})
示例
以下示例将在查询文档时只显示文档的标题。
> db.mycol.find({}, {'title':1,'_id':0})
{ "title" : "MongoDB Guide" }
{ "title" : "NoSQL Database" }
{ "title" : "Python Quick Guide" }
{ "title" : "MongoDB Overview" }
> db.mycol.find({}, {'title':1,'by':1, 'url':1})
{ "_id" : 101, "title" : "MongoDB Guide", "by" : "yiibai tutorials", "url" : "http://www.huawei.com" }
{ "_id" : 102, "title" : "NoSQL Database", "by" : "yiibai tutorials", "url" : "http://www.huawei.com" }
{ "_id" : 104, "title" : "Python Quick Guide", "by" : "yiibai tutorials", "url" : "http://www.huawei.com" }
请注意,在执行find()方法时,始终都会显示_id字段,如果不想要此字段,则需要将其设置为0。
3.13 MongoDB限制记录数
- MongoDB limit()方法
要限制 MongoDB 中返回的记录数,需要使用limit()方法。 该方法接受一个数字类型参数,它是要显示的文档数。
语法
limit()方法的基本语法如下:
> db.COLLECTION_NAME.find().limit(NUMBER)
示例
以下示例将在查询文档时仅显示两个文档。
> db.mycol.find({},{"title":1,_id:0}).limit(2)
{ "title" : "MongoDB Guide" }
{ "title" : "NoSQL Database" }
>
- MongoDB skip()方法
除了limit()方法之外,还有一个方法skip()也接受数字类型参数,用于跳过文档数量。
语法
skip()方法的基本语法如下
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
示例
以下示例将仅显示第三个文档。
> db.mycol.find({},{"title":1,_id:0}).limit(1).skip(2)
{ "title" : "Python Quick Guide" }
>
Shell
请注意,skip()方法中的默认值为0。
3.14 MongoDB排序记录
- MongoDB sort()方法
要在MongoDB中排序文档,需要使用sort()方法。 该方法接受包含字段列表及其排序顺序的文档。使用指定排序顺序1和-1。 1用于升序,而-1用于降序。
语法
sort()方法的基本语法如下
>db.COLLECTION_NAME.find().sort({KEY:1})
示例
以下示例将按标题降序排序显示文档。
> ## 按`title`降序排序
> db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{ "title" : "Python Quick Guide" }
{ "title" : "NoSQL Database" }
{ "title" : "MongoDB Overview" }
{ "title" : "MongoDB Guide" }
> ## 按`title`升序排序
> db.mycol.find({},{"title":1,_id:0}).sort({"title":1})
{ "title" : "MongoDB Guide" }
{ "title" : "MongoDB Overview" }
{ "title" : "NoSQL Database" }
{ "title" : "Python Quick Guide" }
>
3.15 MongoDB索引
- ensureIndex()方法
要创建索引,需要使用MongoDB的ensureIndex()方法。
语法
ensureIndex()方法的基本语法如下
>db.COLLECTION_NAME.ensureIndex({KEY:1})
这里的key是要在其上创建索引的字段的名称,1是升序。 要按降序创建索引,需要使用-1。
示例
>db.mycol.ensureIndex({"title":1})
在ensureIndex()方法中,可以传递多个字段,以在多个字段上创建索引。
>db.mycol.ensureIndex({"title":1,"description":-1})
3.16 MongoDB聚合
聚合操作处理数据记录并返回计算结果。 聚合操作将多个文档中的值组合在一起,并可对分组数据执行各种操作,以返回单个结果。 在SQL中的 count(*)与group by组合相当于mongodb 中的聚合功能。
- aggregate()方法
对于MongoDB中的聚合,应该使用aggregate()方法。
语法
aggregate()方法的基本语法如下
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
示例
假设在集合中,有以下数据
db.article.insert([
{
_id: 100,
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'Maxsu',
url: 'http://www.yiibai.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: 101,
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'Maxsu',
url: 'http://www.yiibai.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: 102,
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Kuber',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
{
_id: 103,
title: 'MySQL Overview',
description: 'MySQL is sql database',
by_user: 'Curry',
url: 'http://www.yiibai.com/mysql/',
tags: ['MySQL', 'database', 'SQL'],
likes: 350
}])Shell
现在从上面的集合中,如果要显示一个列表,说明每个用户写入了多少个教程,那么可使用以下aggregate()方法 -
> db.article.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{ "_id" : "Curry", "num_tutorial" : 1 }
{ "_id" : "Kuber", "num_tutorial" : 1 }
{ "_id" : "Maxsu", "num_tutorial" : 2 }
>Shell
对于上述用例的Sql等效查询是:
select by_user, count(*) as num_tutorial from `article` group by by_user
在上面的例子中,我们按字段by_user分组了文档,并且每次发生的by_user的前一个值的值都被递增。以下是可用聚合表达式的列表。
|
表达式 |
描述 |
示例 |
|
$sum |
从集合中的所有文档中求出定义的值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
|
$avg |
计算集合中所有文档的所有给定值的平均值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
|
$min |
从集合中的所有文档获取相应值的最小值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
|
$max |
从集合中的所有文档获取相应值的最大值。 |
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
|
$push |
将值插入到生成的文档中的数组中。 |
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
|
$addToSet |
将值插入生成的文档中的数组,但不会创建重复项。 |
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
|
$first |
根据分组从源文档获取第一个文档。 通常情况下,这只适用于以前应用的“$sort”阶段。 |
db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
|
$last |
根据分组从源文档获取最后一个文档。通常情况下,这只适用于以前应用的“$sort”阶段。 |
db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
3.17 MongoDB复制
复制是跨多个服务器同步数据的过程。复制提供冗余,并通过不同数据库服务器上的多个数据副本增加数据可用性。 复制保护数据库免受单个服务器的丢失。 复制还允许从硬件故障和服务中断中恢复。 使用其他数据副本,可以将其专用于灾难恢复,报告或备份。
为什么复制?
- 保持数据安全
- 数据的高可用性(24 * 7)
- 灾难恢复
- 维护无停机(如备份,索引重建,压缩)
- 读取缩放(额外的副本可读)
- 副本集对应用程序是透明的
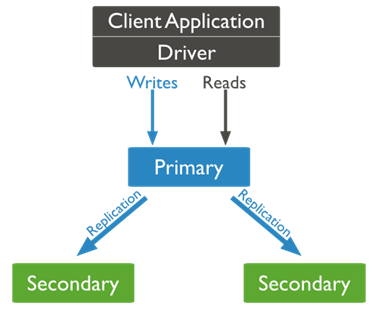
MongoDB复制的工作原理
MongoDB通过使用副本集来实现复制。副本集是托管相同数据集的一组 mongod 实例。 在一个副本中,一个节点是接收所有写操作的主节点。所有其他实例(例如辅助节点)都应用主节点的操作,以便它们具有相同的数据集。 副本集可以只有一个主节点。
- 副本集是一组两个或多个节点(通常最少需要
3个节点)。 - 在副本集中,一个节点是主节点,其余节点是次要节点。
- 所有数据从主节点复制到辅助节点。
- 在自动故障切换或维护时,选择为主节点建立,并选择新的主节点。
- 恢复故障节点后,它再次加入副本集,并作为辅助节点。
- 副本集是一组两个或多个节点(通常最少需要
显示了MongoDB复制的典型图,客户端应用程序始终与主节点进行交互,然后主节点将数据复制到辅助节点。
副本集功能
- N个节点的集群
- 任何一个节点都可以是主节点
- 所有写入操作都转到主节点操作
- 自动故障切换
- 自动恢复
- 共识一般选举
设置副本集
在本教程中,我们将独立的 MongoDB 实例转换为副本集。要转换为副本集,以下是步骤 -
- 关机正在运行 MongoDB 服务器。
- 通过指定 - replSet选项启动 MongoDB服 务器。 以下是--replSet的基本语法 -
- mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
示例
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
- 它在端口27017上启动名称为rs0的 mongod 实例。
- 现在启动命令提示符并连接到这个 mongod 实例。
- 在Mongo客户端中,发出命令rs.initiate()以启动新的副本集。
- 要检查副本集配置,可使用命令rs.conf()。 要检查复制集的状态,请使用命令rs.status()。
将会员添加到副本集
要将成员添加到副本集,请在多台计算机上启动 mongod 实例。 现在启动一个 mongo 客户端并发出一个命令rs.add()。
语法
rs.add()命令的基本语法如下:
>rs.add(HOST_NAME:PORT)
示例
假设您的 mongod 实例名称是 mongod1.net,它在端口 27017 上运行。要将此实例添加到副本集,请在 Mongo 客户端中发出命令 rs.add()。
>rs.add("mongod1.net:27017")
>
只能在连接到主节点时,将 mongod 实例添加到副本集。要检查是否连接到主服务器,请在 mongo 客户端中发出命令db.isMaster()。
rs0:PRIMARY> db.isMaster()
{
"hosts" : [
"ubuntu:27017"
],
"setName" : "rs0",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "ubuntu:27017",
"me" : "ubuntu:27017",
"electionId" : ObjectId("7fffffff0000000000000001"),
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1498896581, 1),
"t" : NumberLong(1)
},
"lastWriteDate" : ISODate("2017-07-01T08:09:41Z")
},
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2017-07-01T08:09:50.365Z"),
"maxWireVersion" : 5,
"minWireVersion" : 0,
"readOnly" : false,
"ok" : 1
}
rs0:PRIMARY>
3.18 MongoDB备份与恢复
- 备份数据
|
语法 |
描述 |
示例 |
|
mongodump —host HOST_NAME —port PORT_NUMBER |
此命令将备份指定的 mongod 实例的所有数据库。 |
mongodump --host 127.0.0.1 --port 27017 |
|
mongodump —out BACKUP_DIRECTORY |
此命令将仅在指定路径上备份数据库。 |
mongodump --out /home/yiibai/mongobak |
|
mongodump —collection COLLECTION —db DB_NAME |
此命令将仅备份指定数据库的指定集合。 |
mongodump --collection mycol --db test |
3.19 MongoDB添加用户
MongoDB采用基于角色的访问控制(RBAC)来确定用户的访问。 授予用户一个或多个角色,确定用户对MongoDB资源的访问权限和用户可以执行哪些操作。 用户应该只有最小权限集才能确保最小权限的系统。
MongoDB系统的每个应用程序和用户都应该映射到不同的用户。 这种访问隔离便于访问撤销和持续的用户维护。
- 前提条件
如果启用了部署的访问控制,则可以使用localhost异常来创建系统中的第一个用户。 此第一个用户必须具有创建其他用户的权限。 对于MongoDB 3.0,使用localhost异常只能在admin数据库上创建用户。 创建第一个用户后,必须使用该用户进行身份验证以添加后续用户。 启用Auth提供有关在启用部署访问控制时添加用户的更多详细信息。
对于常规用户创建,必须拥有以下权限:
要在数据库中创建新用户,必须在该数据库资源上具有createUser操作。
要向用户授予角色,必须对角色的数据库执行grantRole操作。
userAdmin和userAdminAnyDatabase内置角色在其各自的资源上提供createUser和grantRole操作。
- 例子
要在MongoDB部署中创建用户,请连接到部署,然后使用db.createUser()方法或createUser命令添加用户。
MongoDB是一个nosql数据库服务器。 默认安装提供使用mongo命令通过命令行访问数据库而不进行身份验证。下面我们来学习如何在具有适当身份验证的Mongodb服务器中创建用户。
创建管理员用户
可以使用以下命令在MongoDB服务器中创建具有管理员权限的用户。
$ mongo > use admin > db.createUser(
{
user:"root",
pwd:"huawei",
roles:[{role:"root",db:"admin"}]
}
) > exit
添加数据库用户
您还可以创建指定数据库的用户,该用户只能访问该数据库。也可以为此数据库上的用户指定访问级别。 例如,创建一个在mydb数据库上具有读写访问权限的用户帐户。
> use mydb > db.createUser(
{
user: "user01",
pwd: "pwd123",
roles: ["readWrite"]
}
) > exit
验证身份验证使用以下命令。 返回结果为1,表示认证成功。
> db.auth('user01','pwd123')
1
>
删除数据库用户
也可以使用以下命令从数据库中删除用户。
> use mydb
> db.dropUser('user01)
创建带角色的用户
以下操作在test数据库中创建用户:mynewuser,并向用户提供readWrite和dbAdmin角色。
Shell use test
db.createUser(
{
user: "mynewuser",
pwd: "myuser123",
roles: [ "readWrite", "dbAdmin" ]
}
);
创建没有角色的用户
以下操作在test数据库中创建一个名为mynewuser1的用户,但尚未分配角色:
use test
db.createUser(
{
user: "mynewuser1",
pwd: "myuser1123",
roles: [ ]
}
);
创建具有角色的管理用户
以下操作在管理数据库中创建一个名为 myadmin1 的用户,并给予用户对config数据库的 readWrite访问权限,这样可以让用户更改分片分区的某些设置,例如平衡器设置。
use admin
db.createUser(
{
user: "myadmin1",
pwd: "myadmin123",
roles:
[
{ role: "readWrite", db: "config" },
"clusterAdmin"
]
}
);
3.20 MongoDB管理用户和角色
本章基本用不上,因为有很多角色了,但是这里还是提一笔
- 创建用户定义的角色
角色授权用户访问MongoDB资源。 MongoDB提供了许多内置的角色,管理员可以使用它们来控制对MongoDB系统的访问。 但是,如果这些角色无法描述所需的权限集,则可以在特定数据库中创建新角色。
除了在管理数据库中创建的角色外,角色只能包含适用于其数据库的权限,并且只能继承其数据库中的其他角色。
在管理数据库中创建的角色可以包括适用于管理数据库,其他数据库或群集资源的权限,并且可以从其他数据库中的角色以及管理数据库继承。
要创建新角色,可使用db.createRole()方法,指定permissions数组中的权限和roles数组中的继承角色。
MongoDB使用数据库名称和角色名称的组合来唯一定义角色。 每个角色的范围限定在创建角色的数据库中,但MongoDB将所有角色信息存储在admin数据库的admin.system.roles集合中。
先决条件
要在数据库中创建角色,您必须具有:
- 对该数据库资源的createRole操作。
- 对该数据库的grantRole操作指定新角色的权限以及指定要继承的角色。
内置角色userAdmin和userAdminAnyDatabase在其各自的资源上提供createRole和grantRole操作。
- 创建角色来管理当前操作
以下示例创建一个名为manageOpRole的角色,该角色仅提供运行db.currentOp()和db.killOp()的权限。
第一步:使用相应的权限连接到MongoDB
使用“先决条件”部分指定的权限连接到 mongod 或 mongos 。
以下过程使用在“启用认证”中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
myUserAdmin具有在管理员以及其他数据库中创建角色的权限。
第二步:创建一个新角色来管理当前操作
manageOpRole具有对多个数据库以及群集资源的权限。 因此,您必须在管理数据库中创建该角色。
use admin
db.createRole(
{
role: "manageOpRole",
privileges: [
{ resource: { cluster: true }, actions: [ "killop", "inprog" ] },
{ resource: { db: "", collection: "" }, actions: [ "killCursors" ] }
],
roles: []
}
)
新角色授予杀死/终止任何操作的权限。
警告: 终止运行操作非常小心。只能使用db.killOp()方法或killOp命令终止客户端发起的操作,并且不会终止内部数据库操作
- 创建角色用来运行 mongostat
以下示例创建一个名为mongostatRole的角色,该角色仅提供运行mongostat的权限。
第一步:使用相应的权限连接到MongoDB
使用“先决条件”部分指定的权限连接到 mongod 或 mongos 。
以下过程使用在启用认证中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
myUserAdmin具有在管理员以及其他数据库中创建角色的权限。
第二步:创建一个新角色来管理当前的操作
mongostatRole具有作用于群集资源的权限。 因此,您必须在管理数据库中创建该角色。
use admin
db.createRole(
{
role: "mongostatRole",
privileges: [
{ resource: { cluster: true }, actions: [ "serverStatus" ] }
],
roles: []
}
)
- 修改现有用户的访问权限
先决条件
- 必须对数据库具有
grantRole操作才能在该数据库上授予角色。 - 必须在数据库上具有
revokeRole操作以撤销该数据库上的角色。 - 要查看角色的信息,必须明确授予该角色,或必须对该角色的数据库具有
viewRole操作。
执行步骤
第一步:使用相应的权限连接到MongoDB
以具有先决条件部分中指定的权限的用户身份连接到 mongod 或 mongos 。
以下过程使用在启用认证中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
第二步:识别用户的角色和权限
要显示要修改的用户的角色和权限,请使用db.getUser()和db.getRole()方法。
例如,要查看在示例中创建的 reportsUser 的角色,执行以下命令:
use reporting
db.getUser("reportsUser")
要显示在 “accounts” 数据库上由 readWrite 角色授予用户的权限,请执行以下操作:
use accounts
db.getRole( "readWrite", { showPrivileges: true } )
第三步:确定授予或撤销的权限
如果用户需要额外的权限,则向用户授予具有所需权限集的角色或角色。 如果此类角色不存在,请使用适当的权限集创建新角色。
撤销由现有角色提供的特权子集:撤销原始角色并授予仅包含所需权限的角色。如果角色不存在,您需要创建新角色。
第四步:修改用户的访问权限
撤销角色
使用db.revokeRolesFromUser()方法撤销角色。以下示例操作从account数据库上删除用户reportsUser 的 readWrite 角色:
use reporting
db.revokeRolesFromUser(
"reportsUser",
[
{ role: "readWrite", db: "accounts" }
]
)
授予角色
使用db.grantRolesToUser()方法授予角色。 例如,以下操作授予reportsUser用户account数据库上的读取角色:
use reporting
db.grantRolesToUser(
"reportsUser",
[
{ role: "read", db: "accounts" }
]
)
对于分片集群,用户的更改将在命令运行的 mongos 上即时生效。但是,对于群集中的其他mongos 实例,用户缓存可能会等待10分钟才能刷新。请参阅userCacheInvalidationIntervalSecs。
- 修改现有用户的密码
先决条件
要修改数据库上另一个用户的密码,您必须对该数据库具有changeAnyPassword操作。
操作步骤:
第一步:使用相应的权限连接到MongoDB
以具有先决条件部分中指定的权限的用户身份连接到 mongod 或 mongos 。
以下过程使用在启用认证中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
第二步:更改密码
将用户的用户名和新密码传递给db.changeUserPassword()方法。
以下操作将reporting用户的密码更改为:SOh3TbYhxuLiW8ypJPxmt1oOfL:
db.changeUserPassword("reporting", "SOh3TbYhxuLiW8ypJPxmt1oOfL")
- 查看用户的角色
先决条件
要查看其他用户的信息,您必须对其他用户的数据库具有viewUser操作。
用户可以查看自己的信息。
第一步:使用相应的权限连接到MongoDB
以具有先决条件部分中指定的权限的用户身份连接到 mongod 或 mongos 。
以下过程使用在启用认证中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
第二步:查看用户的角色
使用usersInfo命令或db.getUser()方法显示用户信息。
例如,要查看在示例中创建的 reportsUser 的角色,请发出:
use reporting
db.getUser("reportsUser") #此方式,3.X以后才有
在返回的文档中,roles字段显示reportsUser的所有角色:
...
"roles" : [
{ "role" : "readWrite", "db" : "accounts" },
{ "role" : "read", "db" : "reporting" },
{ "role" : "read", "db" : "products" },
{ "role" : "read", "db" : "sales" }
]
- 查看角色的权限
先决条件
要查看角色的信息,您必须明确授予该角色,或必须对该角色的数据库具有 viewRole 操作。
第一步:使用相应的权限连接到MongoDB
以具有先决条件部分中指定的权限的用户身份连接到 mongod 或 mongos 。
以下过程使用在启用认证中创建的用户:myUserAdmin。
$ mongo --port 27017 -u "myUserAdmin" -p "abc123" --authenticationDatabase "admin"
第二步:查看角色授予的权限
对于给定的角色,请使用db.getRole()方法或rolesInfo命令与showPrivileges选项一起执行:
例如,要查看在product数据库上由读取角色授予的权限,请使用以下操作,问题如下:
use products
db.getRole( "read", { showPrivileges: true } )
在返回的文档中,有两个数组:privileges和inheritedPrivileges。权限列出了角色指定的权限,并排除了从其他角色继承的权限。 inheritedPrivileges列出了由此角色授予的所有权限,这两个角色都是直接指定的并被继承。 如果该角色不能从其他角色继承,则两个字段是相同的。
...
"privileges" : [
{
"resource": { "db" : "products", "collection" : "" },
"actions": [ "collStats","dbHash","dbStats","find","killCursors","planCacheRead" ]
},
{
"resource" : { "db" : "products", "collection" : "system.js" },
"actions": [ "collStats","dbHash","dbStats","find","killCursors","planCacheRead" ]
10. }
11. ], 12. "inheritedPrivileges" : [ 13. {
14. "resource": { "db" : "products", "collection" : "" },
15. "actions": [ "collStats","dbHash","dbStats","find","killCursors","planCacheRead" ]
16. },
17. {
18. "resource" : { "db" : "products", "collection" : "system.js" },
19. "actions": [ "collStats","dbHash","dbStats","find","killCursors","planCacheRead" ]
20. }
21. ]
最新文章
- 常见input输入框 点击 发光白色外阴影 focus
- 黄聪:MYSQL使服务器内存CPU占用过高问题的分析及解决方法
- Java 集合系列 13 WeakHashMap
- javascript模式——Facade
- hdu4888 Redraw Beautiful Drawings
- SharePoint管理中心来配置资源限制(大名单)
- sublime text3安装、注册及常用插件
- day1(变量、常量、注释、用户输入、数据类型)
- 租户、租户管理员、部门管理员和开发者在APIGW中的角色
- pyqt5 动画学习(二) 改变控件颜色
- Vultr CentOS 7 安装 Docker
- js事件循环机制 (Event Loop)
- python基础学习(十二)变量进阶
- 最小生成树-QS Network(Prim)
- 实验二 合作:王宏财 http://www.cnblogs.com/wanghongcai/
- python 之禅 import this
- mysql库、表、索引
- 接收连接basic_socket_acceptor
- Python开发【整理笔记】
- 设置UITextField键盘上return key不可点击