Pythonweb采集
2024-09-07 14:51:30
一.访问页面
import webbrowser
webbrowser.open('http://www.baidu.com/')
pip3 install requests
import requests
res = requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
res.status_code == requests.codes.ok #返回真假
len(res.text) #变量保存
print(res.text[:250])
res.raise_for_status() #下载出错抛出异常,成功则不返回
playFile = open('a.txt', 'wb') #写入二进制文件,保存Unicode编码
for chunk in res.iter_content(100000): #指定字节数
playFile.write(chunk)
playFile.close()
pip3 install sqlalchemy
import sqlalchemy as sa
conn = sa.create_engine('sqlite://')
meta = sa.MetaData()
zoo = sa.Table('zoo', meta,
sa.Column('critter', sa.String, primary_key=True),
sa.Column('count', sa.Integer),
sa.Column('damages', sa.Float)
)
meta.create_all(conn)
conn.execute(zoo.insert(('bear', 2, 1000.0)))
conn.execute(zoo.insert(('weasel', 1, 2000.0)))
result = conn.execute(zoo.select()) #类似select *
rows = result.fetchall()
print(rows)
#web
import urllib.request as ur
url = 'http://www.iheartquotes.com/api/v1/random'
conn = ur.urlopen(url)
print(conn)
data = conn.read() #获取网页数据
print(data)
conn.status #状态码
print(conn.getheader('Content-Type')) #数据格式
for key, value in conn.getheaders(): #查看所有http头
print(key, value)
pip3 install requests
import requests
url = 'http://www.iheartquotes.com/api/v1/random'
resp = requests.get(url)
resp
<Response [200]>
print(resp.text)
二.页面过滤
pip3 install beautifulsoup4
import requests,bs4
res = requests.get('http://nostarch.com')
res.raise_for_status()
noStarchSoup = bs4.BeautifulSoup(res.text)
exampleFile = open('example.html')
exampleSoup = bs4.BeautifulSoup(exampleFile)
soup.select('p #author')
soup.select('p')[0] #只取第一个放里面
xx.get('id') #返回id的值
三.CSS选择器例子
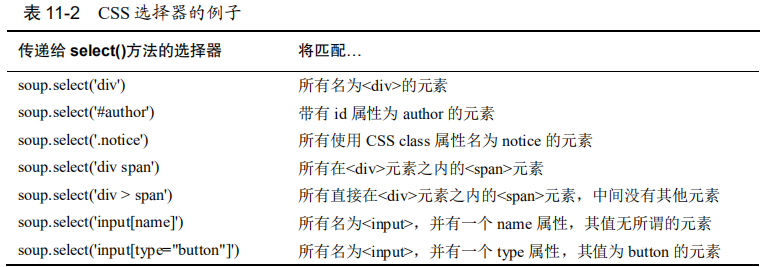
四.实际例子
example.html
<!-- This is the example.html example file. -->
<html><head><title>The Website Title</title></head>
<body>
<p>Download my <strong>Python</strong> book from <a href="http://
inventwithpython.com">my website</a>.</p>
<p class="slogan">Learn Python the easy way!</p>
<p>By <span id="author">Al Sweigart</span></p>
</body></html>
#过滤文件的id
import bs4
exampleFile = open('example.html') #打开到对象
exampleSoup = bs4.BeautifulSoup(exampleFile,features="html.parser")
elems = exampleSoup.select('#author') #找寻id元素,返回列表 tag对象到变量
print(type(elems))
print(type(elems[0]))
print(len(elems)) #看有几个匹配结果
print(elems[0].getText()) #返回第一个结果
print(str(elems[0])) #返回字符串,包含标签和文本
print(elems[0].attrs) #返回字典ID和值
#循环输出
import bs4
exampleFile = open('example.html') #打开到对象
exampleSoup = bs4.BeautifulSoup(exampleFile,features="html.parser")
elems = exampleSoup.select('p')
for i in range(len(elems)):
print(str(elems[i]))
print(elems[i].getText())
最新文章
- Python简单爬虫入门三
- HTML5 meta最全使用手册
- 用Eclipse新建一个web项目没有自动生成web.xml
- 服务器×××上的MSDTC不可用解决办法
- [CareerCup] 14.1 Private Constructor 私有构建函数
- [转]学习 WCF (6)--学习调用WCF服务的各种方法
- maven项目依赖小试牛刀
- Mapreduce中的字符串编码
- char型指针与其它指针或数组的细节
- Windows性能计数器2
- UML学习(二)-----类图
- css样式:列表
- U盘开发之安全U盘
- Scala减少代码重复
- hitTest和pointInside和CGRectContainsPoint
- 利用Fiddler抓取手机APP数据包
- 【Java】Objects 源码学习
- WebGIS开源解决方案之开发环境搭建(一)
- vue 2 仿IOS 滚轮选择器 从入门到精通 (一)
- getgpc($k, $t='GP'),怎么返回的是 NULL?