java基础篇 之 集合概述(List)
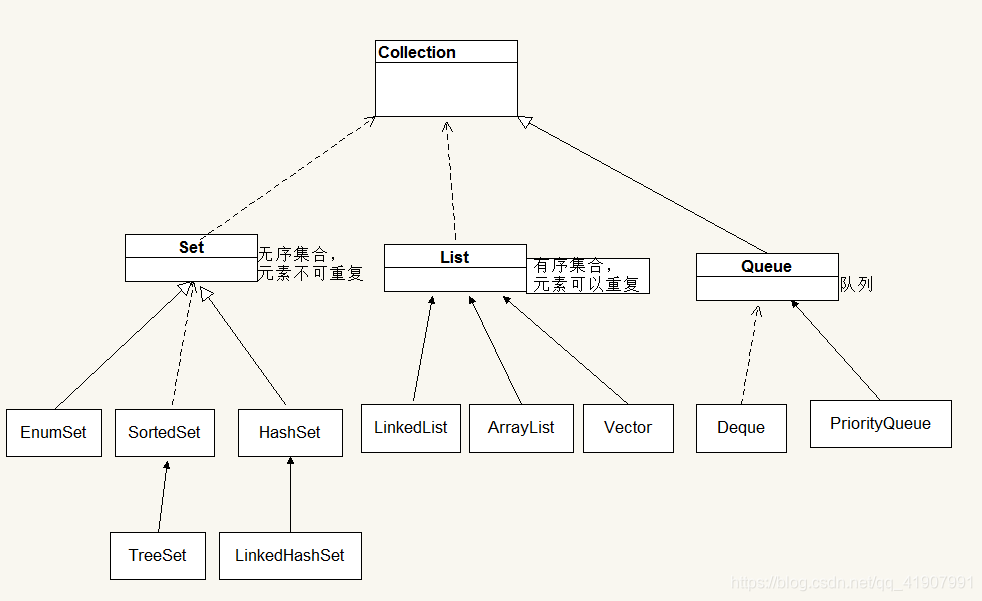
list,有序集合,元素可重复
- LinkedList:底层用链表实现,查找慢,增删快。为什么??
- ArrayList:底层用数组实现,查找看,增删慢。为什么??
- Vector:跟ArrayList一样,都是用数组做底层实现,只不过大量使用了synchronized关键字
我们现在就来分析下为什么ArrayList适合于查找,LinkedList适合于增删:
我们先看下ArrayList源码:
/**
*默认的容量为10
*/
private static final int DEFAULT_CAPACITY = 10; // 采用的是用数组来实现
transient Object[] elementData /**
*
* 容量不足时的扩容方法,从这里我们可以看到,当容量不足时,
* 会进行1.5倍的扩容,即创建一个长度是原长度1.5倍的数组,然后将数据copy过去
*
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
再看下LinedList源码:
transient int size = 0; /**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first; /**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
看完源码后,我们再来看下数组跟链表的区别:
数组的特点
在内存中,数组是一块连续的区域。 拿上面的看电影来说,这几个人在电影院必须坐在一起。
数组需要预留空间,在使用前要先申请占内存的大小,可能会浪费内存空间。 比如看电影时,为了保证10个人能坐在一起,必须提前订好10个连续的位置。这样的好处就是能保证10个人可以在一起。但是这样的缺点是,如果来的人不够10个,那么剩下的位置就浪费了。如果临时有多来了个人,那么10个就不够用了,这时可能需要将第11个位置上的人挪走,或者是他们11个人重新去找一个11连坐的位置,效率都很低。如果没有找到符合要求的作为,那么就没法坐了。
插入数据和删除数据效率低,插入数据时,这个位置后面的数据在内存中都要向后移。删除数据时,这个数据后面的数据都要往前移动。 比如原来去了5个人,然后后来又去了一个人要坐在第三个位置上,那么第三个到第五个都要往后移动一个位子,将第三个位置留给新来的人。 当这个人走了的时候,因为他们要连在一起的,所以他后面几个人要往前移动一个位置,把这个空位补上。
随机读取效率很高。因为数组是连续的,知道每一个数据的内存地址,可以直接找到给地址的数据。并且不利于扩展,数组定义的空间不够时要重新定义数组。
链表的特点
在内存中可以存在任何地方,不要求连续。 在电影院几个人可以随便坐。
每一个数据都保存了下一个数据的内存地址,通过这个地址找到下一个数据。 第一个人知道第二个人的座位号,第二个人知道第三个人的座位号……
增加数据和删除数据很容易。 再来个人可以随便坐,比如来了个人要做到第三个位置,那他只需要把自己的位置告诉第二个人,然后问第二个人拿到原来第三个人的位置就行了。其他人都不用动。
查找数据时效率低,因为不具有随机访问性,所以访问某个位置的数据都要从第一个数据开始访问,然后根据第一个数据保存的下一个数据的地址找到第二个数据,以此类推。 要找到第三个人,必须从第一个人开始问起。不指定大小,扩展方便。链表大小不用定义,数据随意增删。 看完上面的话,我相信大家不难理解为什么ArrayList适合查询,LinkedList适合增删了,但是我们需要注意的是:
LinkedList所说的增删快,实际上是指的是从头部或者尾部增删,而不是随机指定位置的增删,从之前的源码我们可以看到,指定位置的增删,是先要查找到那个元素的,这是很费时间的。
最新文章
- NFinal中增加生成页面自动带入js和css
- return和finally的执行顺序
- [课程设计]Scrum 2.6 多鱼点餐系统开发进度(下单一览页面-菜式添加功能实现)
- 从NullObject谈C#6.0改进
- UIView /  UIView的布局
- Unhandled Exxception “Unhandled exception type IOException”?
- NYOJ 372 巧克力的
- mysql 基础指令/命令
- Vue学习小结(二)
- React-Native的基本控件属性方法,对React-Native的学习,从熟悉基本控件开始。
- 自己动手写CPU——寄存器堆、数据存储器(基于FPGA与Verilog)
- mysql的varchar字段可以存储多少个中文字符
- URL diff URI
- fastjson的常用方法
- sqlalchemy根据数据库结构生成映射的实体
- XSS事件(一)
- 17个CSS知识点整理
- VIM下的可视模式的相关知识
- [LeetCode] 675. Cut Off Trees for Golf Event_Hard tag: BFS
- python: no module named bz2
热门文章
- svg如何设置中心点进行缩放
- ModuleNotFoundError: No module named 'sklearn.cross_validation'
- Salesforce元数据入门指南,管理员必看!
- 一站式WebAPI与认证授权服务
- 多线程高并发编程(4) -- ReentrantReadWriteLock读写锁源码分析
- stand up meeting 12/4/2015 -12/6/2015
- 嵌入css方式
- 开发一款图片压缩工具(二):使用 pngquant 实现图片压缩
- MySQL优化之COUNT(*)效率(部分转载与个人亲测)
- Js实现将html页面或div生成图片