python爬虫——《瓜子网》的广州二手车市场信息
2024-09-08 00:44:41
由于多线程爬取数据比单线程的效率要高,尤其对于爬取数据量大的情况,效果更好,所以这次采用多线程进行爬取。具体代码和流程如下:
import math
import re
from concurrent.futures import ThreadPoolExecutor
import requests
import lxml
import lxml.etree
# 获取网页源代码
def getHtml(url, header):
try:
response = requests.get(url, headers=header)
response.raise_for_status()
return response.content.decode('utf-8')
except:
return ''
# 获取翻页url
def getPageUrl(url, response):
mytree = lxml.etree.HTML(response)
# 页码
carNum = mytree.xpath('//*[@id="post"]/p[3]/text()')[0]
carNum = math.ceil(int(re.findall('(\d+)', carNum)[0]) / 40)
urlList = url.rsplit('/', maxsplit=1)
pageUrlList = []
if carNum != 0:
for i in range(1, carNum + 1):
pageUrl = urlList[0] + "/o" + str(i) + "/" + urlList[1]
pageUrlList.append(pageUrl)
return pageUrlList
# 获取汽车品牌
def getCarBrand(response):
mytree = lxml.etree.HTML(response)
# 汽车品牌url
carBrandUrl = mytree.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]/ul/li/p/a/@href')
# 汽车品牌名
carBrandName = mytree.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]/ul/li/p/a/text()')
carBrandDict = {}
for i in range(len(carBrandName)):
carBrandDict[carBrandName[i]] = "https://www.guazi.com" + carBrandUrl[i]
return carBrandDict
# 获取汽车信息
def getCarInfo(pageUrl, carBrandName):
response = getHtml(pageUrl, header)
mytree = lxml.etree.HTML(response)
for i in range(40):
# 汽车名称
carName = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/h2/text()')[i]
# 汽车图片
carPic = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/img/@src')[i]
carPic = carPic.rsplit("jpg", maxsplit=1)[0] + 'jpg'
# 汽车出产年份、里程数
carInfo = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[1]/text()')[i]
# 现价
carCurrentPrice = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[2]/p/text()')[i] + "万"
# 原价
carOriginPrice = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[2]/em/text()')[i]
print(carName, carPic, carInfo, carCurrentPrice, carOriginPrice)
# 写入文件
path = carBrandName + '.txt'
with open(path, 'a+') as f:
f.write(str((carName, carPic, carInfo, carCurrentPrice, carOriginPrice)) + '\n')
if __name__ == '__main__':
url = 'https://www.guazi.com/gz/buy/'
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
}
# 获得初始页源代码
html = getHtml(url, header)
# 获取汽车品牌信息字典
carBrandDict = getCarBrand(html)
# 多线程(10条的线程池)
with ThreadPoolExecutor(10) as exT:
# 程序执行流程
# 根据汽车品牌进行爬取
for carBrandName, carBrandUrl in carBrandDict.items():
# 获取不同品牌页面源代码
html = getHtml(carBrandUrl, header)
# 获取当前品牌页面的页码url
pageUrlList = getPageUrl(carBrandUrl, html)
# 翻页
for pageUrl in pageUrlList:
# 获取汽车信息并写入文件
exT.submit(getCarInfo, pageUrl, carBrandName)![]()
结果如下:
![]()
![]()
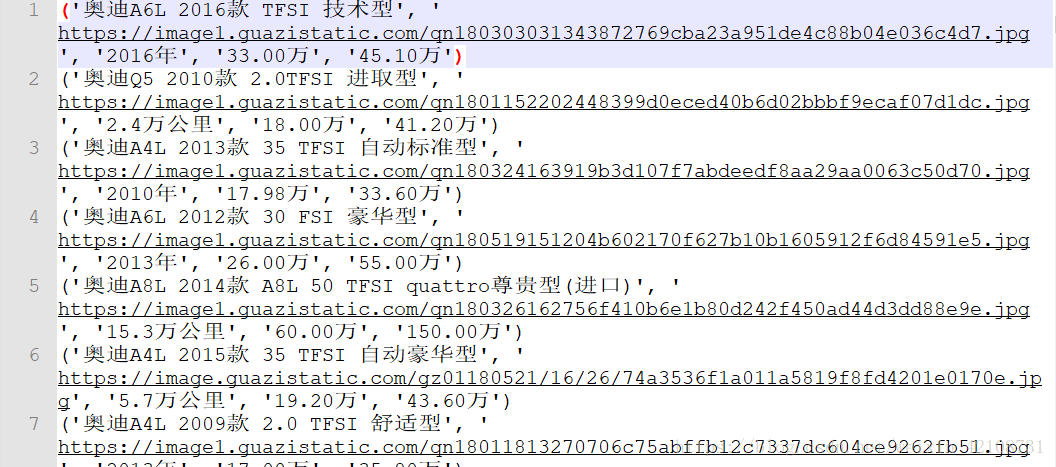
由于《瓜子网》更新过域名,所以之前有评论说网页打不开,现已做了处理,程序能正常爬取数据啦!
以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://www.cnblogs.com/qiuwuzhidi/
想获取更多数据或定制爬虫的请点击python爬虫专业定制
最新文章
- vim中添加多行注释和删除多行注释
- 深入理解python的yield和generator
- mysql innodb 数据打捞(一)innodb 页面结构特征
- nodejs学习笔记之网络编程
- MVC数据提交
- grails的controller和action那点事---远程调试groovy代码
- avalon与双缓冲技术
- docker入门【1】
- BZOJ.4009.[HNOI2015]接水果(整体二分 扫描线)
- ssh整合,hibernate查询表数量count以及批处理添加
- F1赛道 - Bahrain International Circuit | 巴林国际赛道
- 知识点:Mysql 索引原理完全手册(2)
- 灰熊:在这6个信息流和DSP平台投放后,我总结了这些血泪经验!
- How to intall and configure Haproxy on Centos
- Linux命令之查看文件夹、文件数量及其所占磁盘空间
- JDK1.5新特性,基础类库篇,扫描类(Scanner)用法
- Swift is Open Source 博客note
- OpenCV学习笔记:opencv_highgui模块
- CentOS 6.3 + Subversion + Usvn 搭建版本管理服务器
- 2017/10 冲刺NOIP集训记录:暁の水平线に胜利を刻むのです!
热门文章
- MySQL Order BY 排序过程
- MyBatis工程搭建&MyBatis实现Mapper配置查询
- 使用sysbench测试mysql及postgresql(完整版)
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
- 深入理解Java并发框架AQS系列(四):共享锁(Shared Lock)
- [素数判断]P1125 笨小猴
- ECharts地理坐标系属性介绍
- [Fundamental of Power Electronics]-PART II-7. 交流等效电路建模-7.5 状态空间平均 7.6 本章小结
- oo第四单元总结及总课程回顾
- Spring(五)Spring与Web环境集成