HashTable HashMap concurrentHashMap区别
HashTable HashMap concurrentHashMap区别
HashMap、HashTable、ConcurrentHashMap都是map接口的实现类
1.(同步性)HashTable的方法是同步的,HashMap不能同步。
Hashtable线程安全(需要排队),源码中方法都加了synchronized(同步),HashMap中方法没有同步,所以线程不安全。
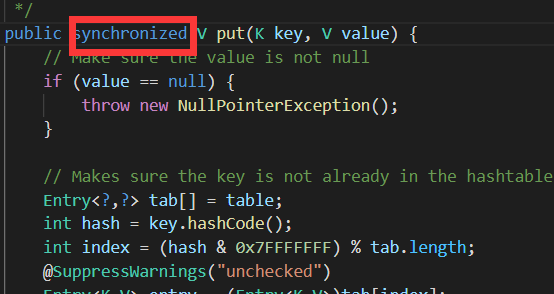
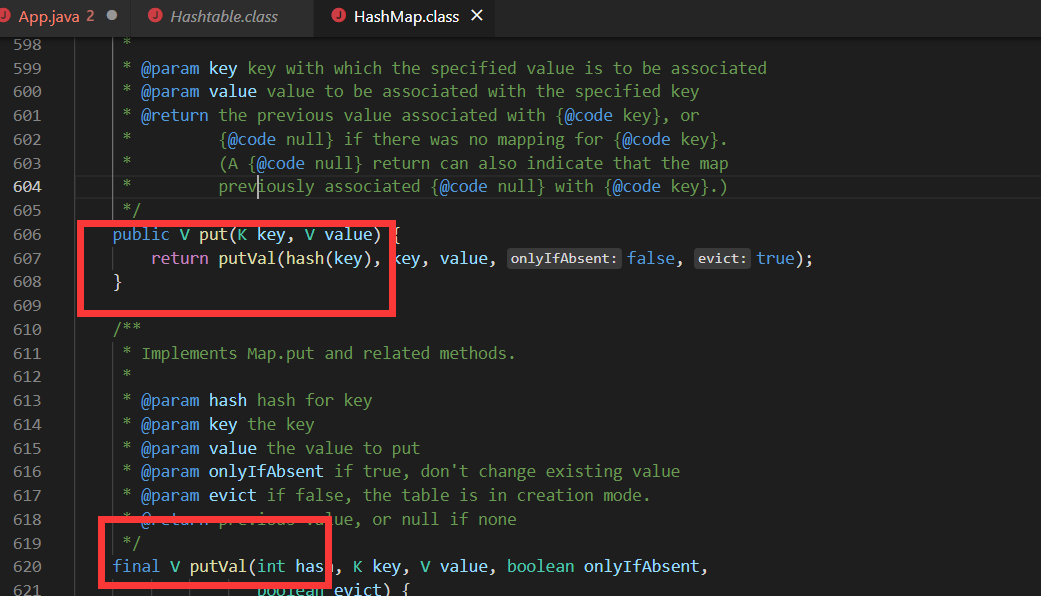
所以hashMap不安全。但是hashtable需要排队效率很低。我们需要使用concurrentHashMap,这个不会把整个方法锁住,采用分段锁的方式进行数据锁定。c+v: Hashtable和ConcurrentHashMap有什么分别呢?它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。
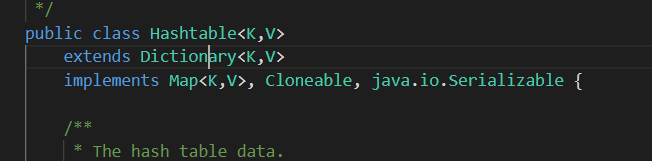
2.继承父类不同
HashTable是继承自Dictionary类,而HashMap是继承自AbstractMap类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。


3.对null key和null value的支持不同
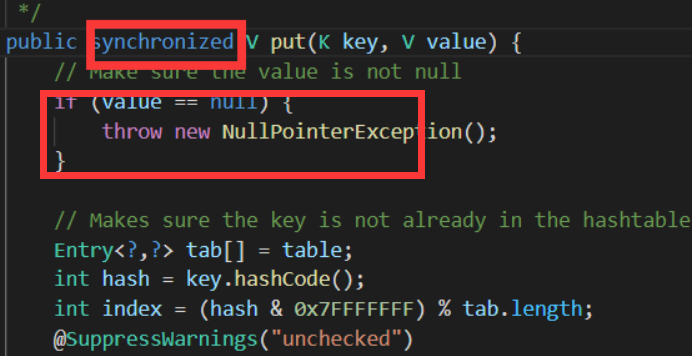
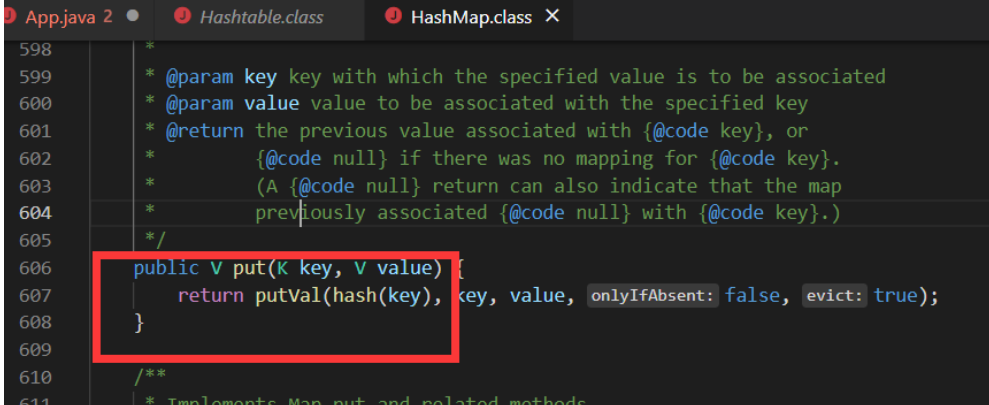
且HashTable注释中也有说明:
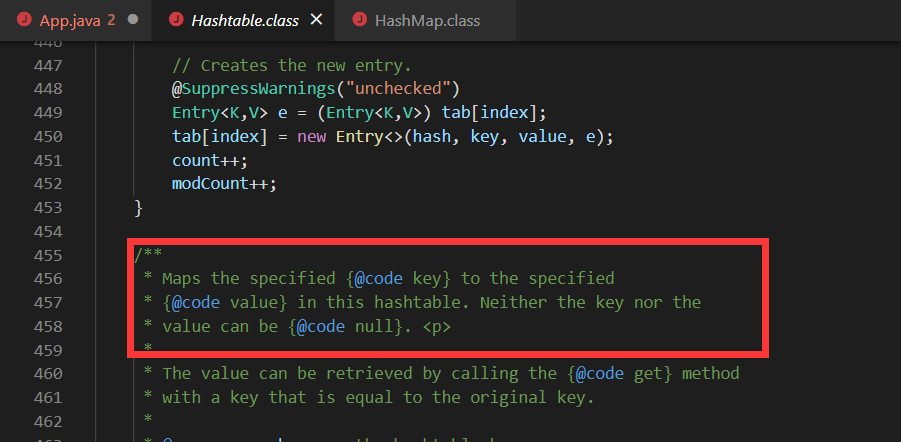
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
4.初始化和扩容方式不同)HashTable中hash数组初始化大小及扩容方式不同。
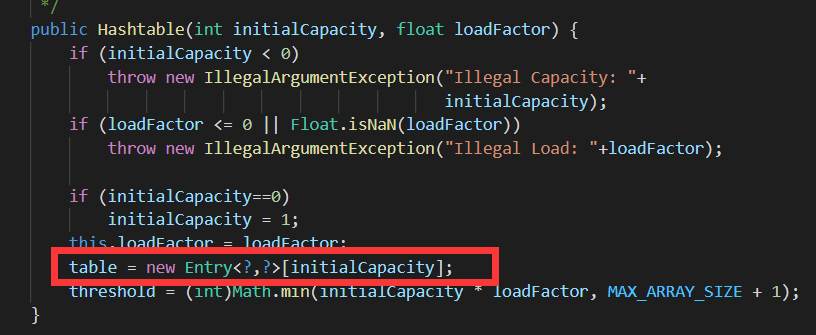
**初始化数组的时机不一样:**
hashTable:在构造方法中初始化
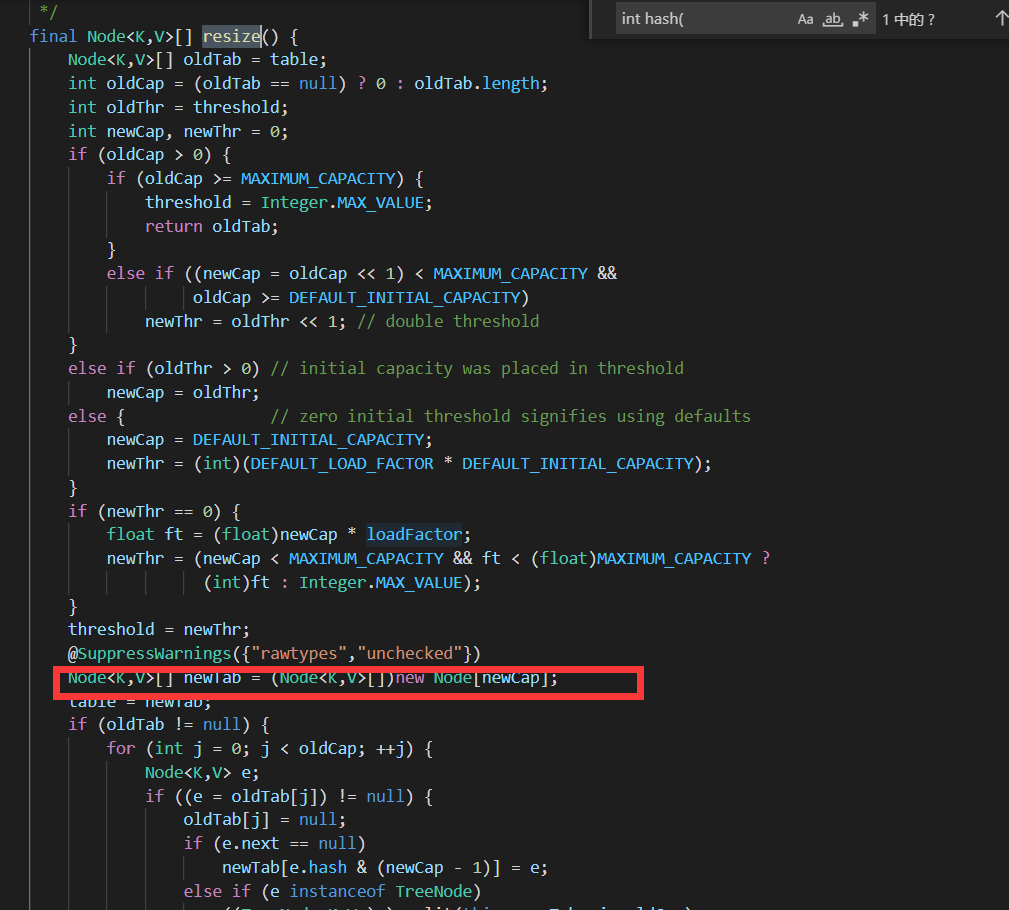
hashMap:是在第一次调用put方法的时候在resize(重新扩容的方法)(从put方法中找到putval 再找到resize方法)方法中建立这个数组
Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。要求容量必须为2的次幂。
创建时,如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小。也就是说Hashtable会尽量使用素数、奇数。而HashMap则总是使用2的幂作为哈希表的大小。
5. 计算hash值的方法不同
Hashtable直接使用key对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数法来获得最终的位置。

hashMap为了得到元素的位置,首先需要根据元素的 Key计算出一个hash值,然后再用这个hash值来计算得到最终的位置.

HashMap的效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高,而计算位运算为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理。从而不至于把使用2 的幂次方带来的效率提升给抵消掉.例如通过h^(h>>>16)无符号位右移。
6.(遍历方法不同)HashTable使用Enumeration遍历,HashMap使用Iterator进行遍历。
7.index计算
Hashtable:index = (hash & 0x7FFFFFFF) % tab.length;
HashMap:index = hash & (tab.length – 1);
8.对外提供的接口不同
Hashtable比HashMap多提供了elements() 和contains() 两个方法。
elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。
9.hash冲突
当多个键值对通过键计算出来的hashCode是相同的话就会出现hash冲突
解决此冲突常用的是链地址法,即在数组数组&spm=1001.2101.3001.7020角标上加一个链表,冲突发生的时候就将新的键值对加在链表上。进行查找的时候,先通过hashCode找到数组角标,再遍历链表通过key.equals()方法确定位置。
10.加载因子
为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
加载因子还可以通过构造函数根据实际情况由程序员指定。加载因子越小,查找的效率越快,空间成本越大(用空间换时间)
11.底层实现
HashTable:底层数组+链表实现
HashMap:底层数组+链表(红黑树)存储,键值都可以为空,线程不安全,当链表长度大于8时,将后面的数据放入红黑树存储。
ConcurrenHashMap:底层采用分段的数组+数组+链表(红黑树)实现,线程安全.
总结:
1.HashTable
任何非空对象都可作为键或值(键值都不能为空) 底层数组+链表实现 线程安全,实现线程安全的方式是在进行修改的时候锁住了整个HashTable,效率低下,ConcurrentHashMap对此进行了优化(分段所) 初始size是11,扩容2*size+1 计算hashCode的方法:直接使用key的hashcode对table数组的长度直接进行取模 index = (hash & 0x7FFFFFFF) % tab.length
2.HashMap
基于hash表的Map接口的实现类,存储形式为一组组的键值对,并且键值都允许为空,键只能最多允许有一个null(key不可重复性),
HashMap类大致相当于 Hashtable,除了它是不同步的,允许空值。
HashMap不保证任何Map的秩序,特别是不保证存储的顺序随时间保持恒定
底层数组+链表(红黑树)存储,键值都可以为空,线程不安全,当链表长度大于8时,将后面的数据放入红黑树存储。 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀 计算hashCode方法:计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸 index = hash & (tab.length – 1)
3.ConcurrentHashMap
底层采用分段的数组+数组+链表(红黑树)实现,线程安全 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。) Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容 ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
## 补充:
###为什么我们需要ConcurrentHashMap和CopyOnWriteArrayList
同步的集合类(Hashtable和Vector),同步的封装类(使用Collections.synchronizedMap()方法和Collections.synchronizedList()方法返回的对象)可以创建出线程安全的Map和List。但是有些因素使得它们不适合高并发的系统。它们仅有单个锁,对整个集合加锁,以及为了防止ConcurrentModificationException异常经常要在迭代的时候要将集合锁定一段时间,这些特性对可扩展性来说都是障碍。
ConcurrentHashMap和CopyOnWriteArrayList保留了线程安全的同时,也提供了更高的并发性。ConcurrentHashMap和CopyOnWriteArrayList并不是处处都需要用,大部分时候你只需要用到HashMap和ArrayList,它们用于应对一些普通的情况。
其他copy的:
- 底层数据结构不同:jdk1.7底层都是数组+链表,但jdk1.8 HashMap加入了红黑树
- Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
- 添加key-value的hash值算法不同:HashMap添加元素时,是使用自定义的哈希算法,而HashTable是直接采用key的hashCode()
- 实现方式不同:Hashtable 继承的是 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
- 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- 扩容机制不同:当已用容量>总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 +1。
- 支持的遍历种类不同:HashMap只支持Iterator遍历,而HashTable支持Iterator和Enumeration两种方式遍历
- 迭代器不同:HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。而Hashtable 则不会。
- 部分API不同:HashMap不支持contains(Object value)方法,没有重写toString()方法,而HashTable支持contains(Object value)方法,而且重写了toString()方法
- 同步性不同: Hashtable是同步(synchronized)的,适用于多线程环境,而hashmap不是同步的,适用于单线程环境。多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。
最新文章
- R语言内存管理
- Redis发布订阅实现原理
- 开发新产品的三个验证阶段(EVT/DVT/PVT)
- hdu----(1466)计算直线的交点数(dp)
- Java内部实现的观察者模式小记
- Google 网络库Volley简介
- 终端查询数据库sqlite(创建你自己,或者是coredata创建)那里的东西
- RGB888转RGB666
- Android’s HTTP Clients (httpClient 和 httpURLConnect 区别)
- 从壹开始微服务 [ DDD ] 之五 ║聚合:实体与值对象 (上)
- 关于字符的C++函数
- java socket / No buffer space available
- Linux 命令locate
- webpack插件去除没用到的css
- MYSQL 备份及还原数据库
- [freeCodeCamp] solution to JUGGLING ASYNC
- HTTP2.0探究
- 【codeforces 553E】 Kyoya and Train
- 转:使用Mosquitto-Auth-Plugin对mqtt客户端进行验证
- python的sorted函数对字典按value进行排序