【GUI开发案例】用python爬百度搜索结果,并开发成exe桌面软件!
一、背景介绍
你好,我是 @马哥python说 ,一名10年程序猿。
1.1 老版本
之前我开发过一个百度搜索的python爬虫代码,具体如下:
【python爬虫案例】用python爬取百度的搜索结果!
这个爬虫代码自发布以来,受到了众多小伙伴的关注:
但是,很多不懂python编程的小伙伴无法使用它,非常痛苦!
于是,我把这个程序封装成了一个桌面软件(exe文件),无需python运行环境也可以使用。
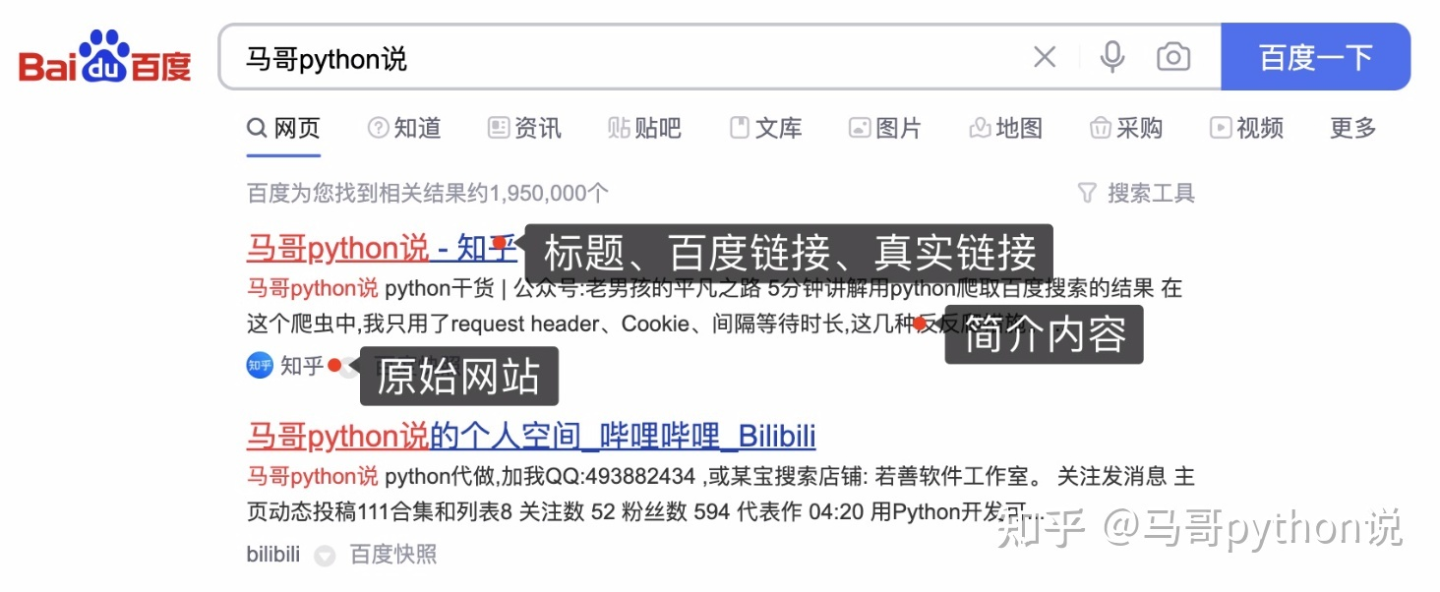
1.2 爬取目标
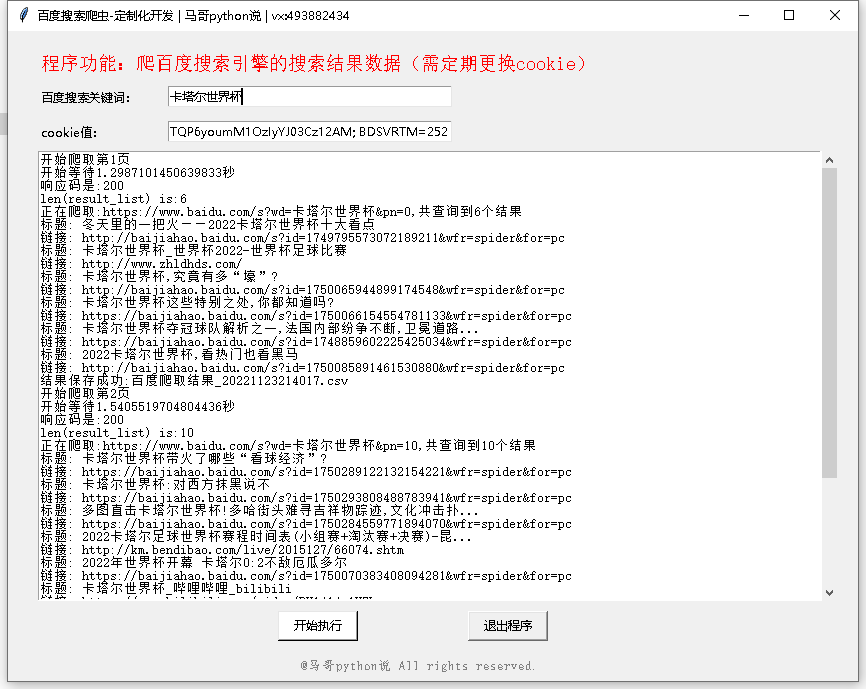
1.3 软件运行截图
1.4 爬取数据

1.5 实现思路
通过python爬虫技术,爬取百度搜索结果数据,包含字段:
页码、标题、百度链接、真实链接、简介、网站名称。
并把源码封装成exe文件,方便没有python环境,或者不懂技术的人使用它。
二、代码讲解
2.1 爬虫
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析页面
import pandas as pd # 存入csv数据
import os # 判断文件存在
from time import sleep # 等待间隔
import random # 随机
import re # 用正则表达式提取url
定义一个请求头:
# 伪装浏览器请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.baidu.com",
# 需要更换Cookie
"Cookie": "换成自己的cookie"
}
Cookie是个关键,如果不加Cookie,响应码可能不是200,获取不到数据,而且Cookie值是有有效期的,需要定期更换,如果发现返回无数据或响应码非200,尝试替换最新的Cookie。
怎么获取到Cookie呢?打开Chrome浏览器,访问百度页面,按F12进入开发者模式:
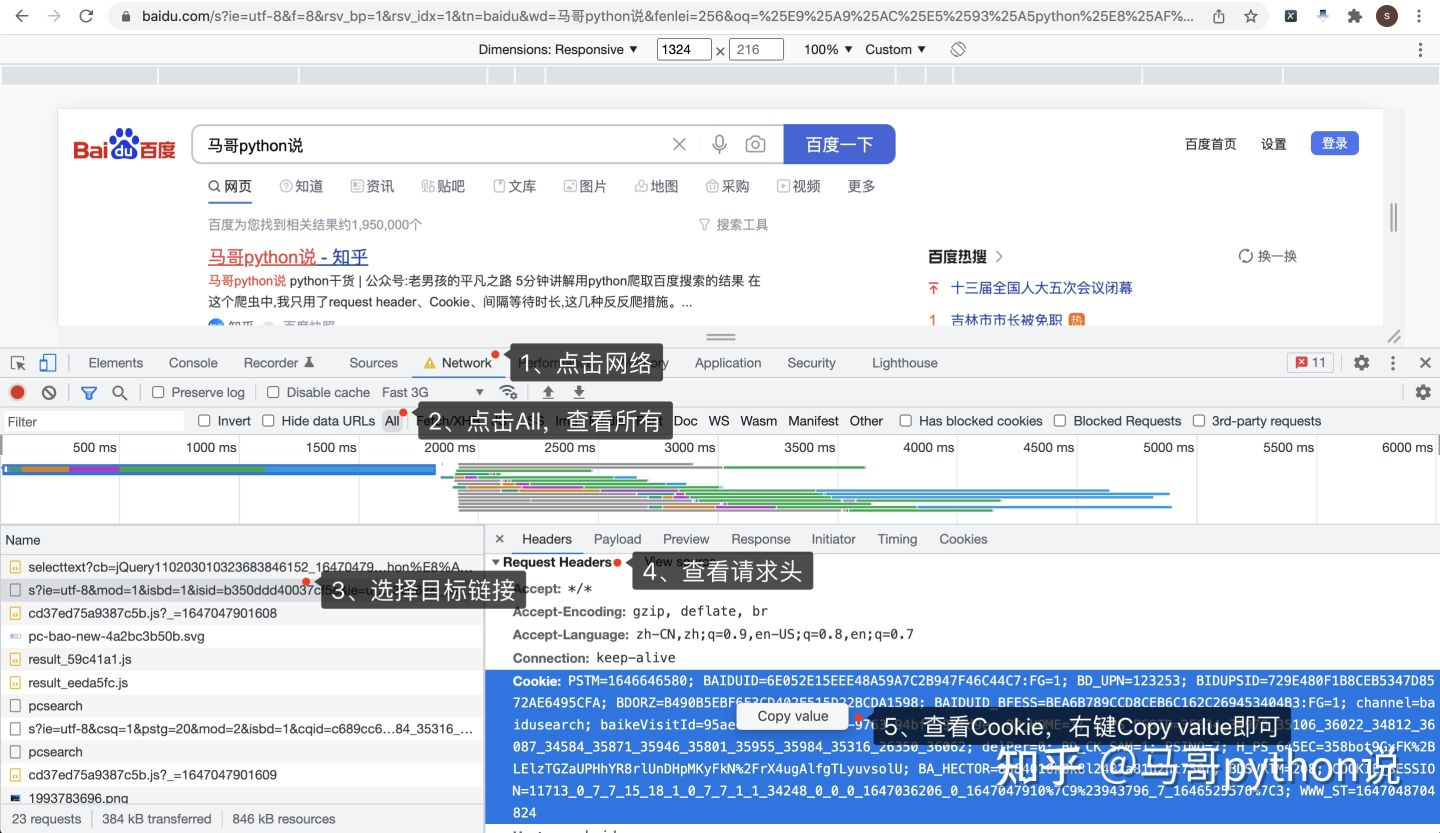
按照图示顺序,依次:
- 点击Network,进入网络页
- 点击All,查看所有网络请求
- 选择目标链接,和地址栏里的地址一致
- 查看Request Headers请求头
- 查看请求头里的Cookie,直接右键,Copy value,粘贴到代码里
然后,分析页面请求地址:

wd=后面是搜索关键字"马哥python说",pn=后面是10(规律:第一页是0,第二页是10,第三页是20,以此类推),其他URL参数可以忽略。
然后,分析页面元素,以搜索结果标题为例:
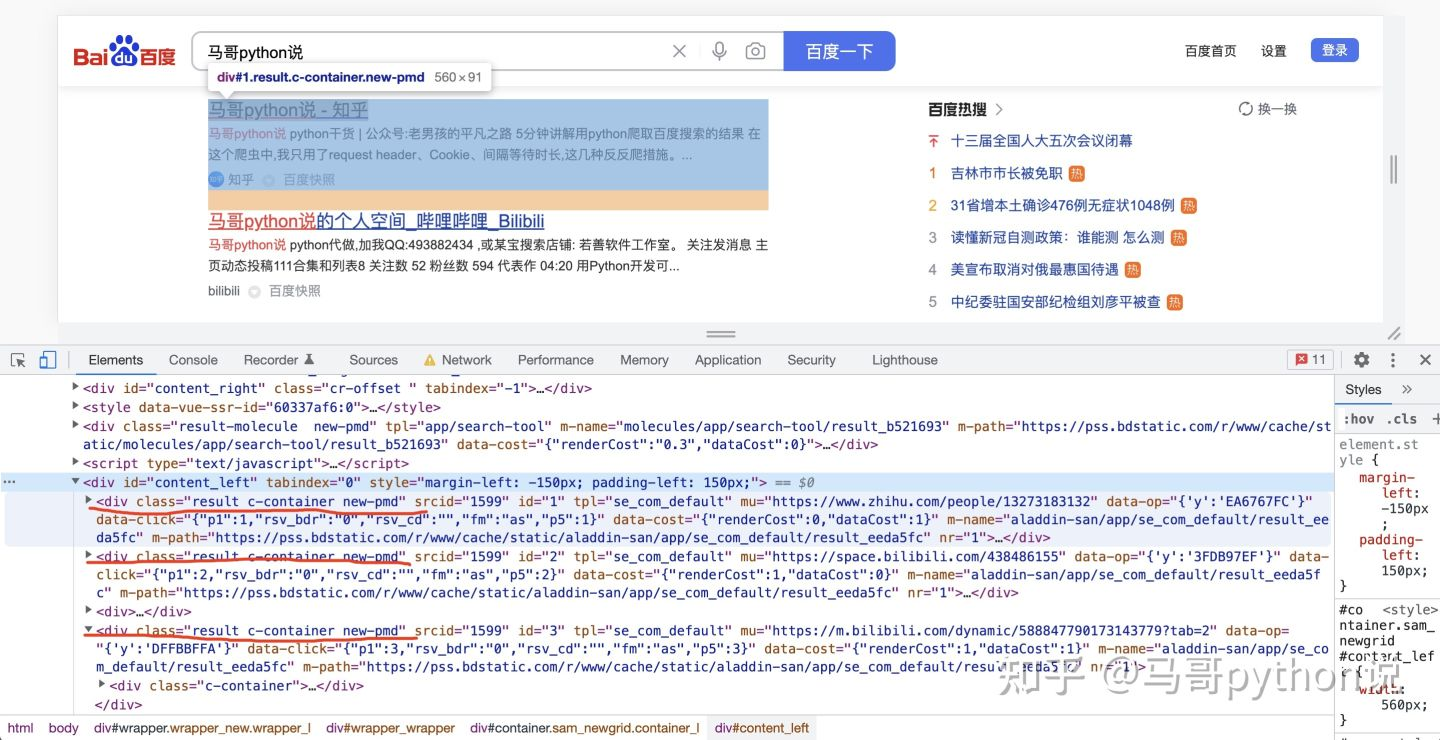
每一条搜索结果,都是class="result c-container new-pmd",下层结构里有简介、链接等内容,解析内部子元素不再赘述。
所以根据这个逻辑,开发爬虫代码。
# 获得每页搜索结果
for page in range(v_max_page):
print('开始爬取第{}页'.format(page + 1))
wait_seconds = random.uniform(1, 2) # 等待时长秒
print('开始等待{}秒'.format(wait_seconds))
sleep(wait_seconds) # 随机等待
url = 'https://www.baidu.com/s?wd=' + v_keyword + '&pn=' + str(page * 10)
r = requests.get(url, headers=headers)
html = r.text
print('响应码是:{}'.format(r.status_code))
soup = BeautifulSoup(html, 'html.parser')
result_list = soup.find_all(class_='result c-container new-pmd')
print('正在爬取:{},共查询到{}个结果'.format(url, len(result_list)))
其中,获取到的标题链接,一般是这种结构:
这显然是百度的一个跳转前的地址,不是目标地址,怎么获取它背后的真实地址呢?
向这个跳转前地址,发送一个请求,然后逻辑处理下:
def get_real_url(v_url):
"""
获取百度链接真实地址
:param v_url: 百度链接地址
:return: 真实地址
"""
r = requests.get(v_url, headers=headers, allow_redirects=False) # 不允许重定向
if r.status_code == 302: # 如果返回302,就从响应头获取真实地址
real_url = r.headers.get('Location')
else: # 否则从返回内容中用正则表达式提取出来真实地址
real_url = re.findall("URL='(.*?)'", r.text)[0]
print('real_url is:', real_url)
return real_url
如果响应码是302,就从响应头中的Location参数获取真实地址。
如果是其他响应码,就从响应内容中用正则表达式提取出URL真实地址。
把爬取到的数据,保存到csv文件:
df = pd.DataFrame(
{
'关键词': kw_list,
'页码': page_list,
'标题': title_list,
'百度链接': href_list,
'真实链接': real_url_list,
'简介': desc_list,
'网站名称': site_list,
}
)
if os.path.exists(v_result_file):
header = None
else:
header = ['关键词', '页码', '标题', '百度链接', '真实链接', '简介', '网站名称'] # csv文件标头
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_result_file))
to_csv的时候需加上选项(encoding='utf_8_sig'),否则存入数据会产生乱码,尤其是windows用户!
2.2 软件界面
界面部分代码:
# 创建主窗口
root = tk.Tk()
root.title('百度搜索爬虫-定制化开发 | 马哥python说')
# 设置窗口大小
root.minsize(width=850, height=650)
show_list_Frame = tk.Frame(width=800, height=450) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=120, anchor='nw') # 摆放位置
# 滚动条
scroll = tk.Scrollbar(show_list_Frame)
# 放到Y轴竖直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
2.3 日志模块
软件运行过程中,会在同级目录下生成logs文件夹,文件夹内会出现log文件,记录下软件在整个运行过程中的日志,方便长时间运行、无人值守,出现问题后的debug。
部分核心代码:
class Log_week():
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
self.logger.addHandler(sh)
sh.setFormatter(log_formatter)
self.logger.addHandler(info_handler)
info_handler.setFormatter(log_formatter)
return self.logger
三、软件运行演示
演示视频:
【爬虫GUI演示】用python爬百度搜索,并开发成exe桌面软件!
我是 @马哥python说,持续分享python干货!
最新文章
- ANdroid URL
- 拥有的50个CSS代码片段(上)
- SpringMVC学习--springmvc原理
- HTTPS基本原理
- 一排cell就第一个cell要点两次才响应,其他的cell都点一下就响应
- 【转】Warning: mysql_connect(): mysqlnd cannot connect to MySQL 4.1+ using the old insecure authenticat
- C# 单例模式Lazy<T>实现版本
- BZOJ 3306 树
- jquery.qrcode.min.js生成二维码 通过前端实现二维码生成
- openstack neutron debugs listss
- CCFileUtils::getFileData疑惑
- 双绞线的制作,T568A线序,T568B线序
- Python内置函数(52)——getattr
- Hdoj 2036.改革春风吹满地 题解
- 将Elasticsearch的快照备份到HDFS
- Linux内核分析 读书笔记 (第十八章)
- 并查集(Union-Find)
- ECharts动态获取后台传过来的json数据进行多个折线图的显示,折线的数据由后台传过来
- c#复习提纲
- centos7.3挂在移动硬盘(亲测)