Flink WordCount入门
2024-09-08 17:09:08
下面通过一个单词统计的案例,快速上手应用 Flink,进行流处理(Streaming)和批处理(Batch)
单词统计(批处理)
- 引入依赖
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
</dependency>
- 代码实现
public class WordCountBatch {
public static void main(String[] args) throws Exception {
String inputFile= "E:\\data\\word.txt";
String outPutFile= "E:\\data\\wordResult.txt";
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//1. 读取数据
DataSource<String> dataSource = executionEnvironment.readTextFile(inputFile);
//2. 对数据进行处理,转成word,1的格式
FlatMapOperator<String, Tuple2<String, Integer>> flatMapOperator = dataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
});
//3. 对数据分组,相同word的一个组
UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = flatMapOperator.groupBy(0);
//4. 对分组后的数据求和
AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1);
//5. 写出数据
sum.writeAsCsv(outPutFile).setParallelism(1);
//执行
executionEnvironment.execute("wordcount batch process");
}
}
执行 main 方法,得出结果。我测试的 word.txt 内容如下:
ni hao hi
wang mei mei
liu mei
ni hao
wo hen hao
this is a good idea
Apache Flink
输出的文件结果:
a,1
mei,3
Apache,1
Flink,1
good,1
hen,1
hi,1
idea,1
ni,2
is,1
liu,1
this,1
wo,1
hao,3
wang,1
单词统计(流数据)
需求:Socket 模拟实时发送单词,使用 Flink 实时接收数据,对指定时间窗口内(如 5s)的数据进行聚合统计,每隔 1s 汇总计算一次,并且把时间窗口内计算结果打印出来
public class WordCountStream {
public static void main(String[] args) throws Exception {
int port = 7000;
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> textStream = executionEnvironment.socketTextStream("192.168.56.103", port, "\n");
SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2SingleOutputStreamOperator = textStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split("\\s");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> word = tuple2SingleOutputStreamOperator.keyBy(0)
.timeWindow(Time.seconds(5),Time.seconds(1)).sum(1);
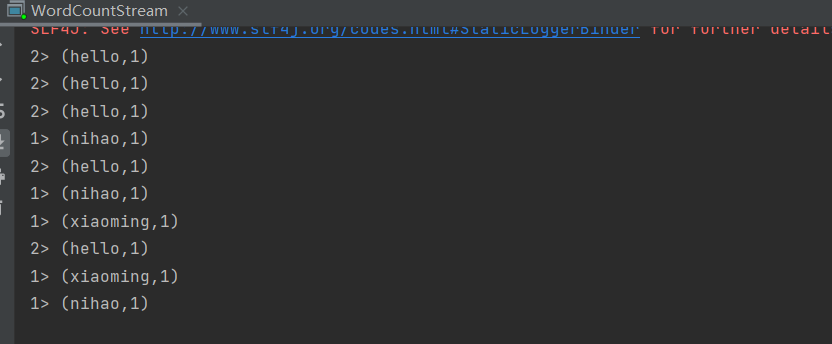
word.print();
executionEnvironment.execute("wordcount stream process");
}
}
运行起来之后,我们就可以开始发送 socket 请求过去。我们测试可以使用 netcat 工具。
在 linux 上安装好后,使用下面的命令:
nc -lk 7000
然后发送数据即可。

最新文章
- NodeJS写个爬虫,把文章放到kindle中阅读
- git 常用命令粗略总结
- 【学习笔记】在原生javascript中使用ActiveX和插件
- 使用Carthage管理iOS依赖库
- 如何实现侧边栏菜单之间的分割线——不用border-bottom
- linux服务之tuned
- 关于Depth Bounds Test (DBT)和在CE3的运用
- java7新特性 java8新特性
- 用JavaScript获取页面上被选中的文字的技巧
- tomcat集群部署
- 如何为你的初创应用App开发公司建立战略计划(商业战略竞争五力学)
- SAX解析xml浅析
- redis的密码设置(windows与linux相同)
- Erlang edoc 多级目录出错
- 在VB中动态执行VBS代码,可操控窗体控件
- iOS Button添加阴影 和 圆角
- tensorflow中的Supervisor
- Linux文件系统命令 split
- php格式化数字:位数不足前面加0补足
- 课程一(Neural Networks and Deep Learning),第二周(Basics of Neural Network programming)—— 1、10个测验题(Neural Network Basics)