去哪儿是如何做到大规模故障演练的?|TakinTalks
# 一分钟精华速览 #
混沌工程作为一种提高技术架构弹性能力和容错能力的复杂技术手段,近年来讨论声音不断,相比在分布式系统上进行随机的故障注入实验,基于混沌工程的大规模自动化故障演练,不仅能将“作战演习”常态化,还能通过提高覆盖面而获得更高的产出价值,帮助更全面地完善故障应急预案和处理体系。此前 TakinTalks 分享了去哪儿在过去 3 年里 4 个阶段的混沌工程能力建设(破坏系统是为了更稳定?混沌工程在去哪儿的4个阶段实践)。
如果说能力建设是从 0-1,那么从 1-100 的大规模自动化演练又是怎么进行的?

作者介绍

去哪儿网高级技术总监 - 朱仕智
TakinTalks 社区特聘专家,2013 年加入去哪儿网,负责过公共业务、国际机票、基础架构等团队,擅长高并发高可用高性能的系统设计和落地,多年的技术管理经验。目前负责基础架构部门,包含基础平台、中间件架构、大前端、质量保障等团队,近期专注公司整体技术演进和云原生、数字化技术落地。
温馨提醒:本文约 4000 字,预计花费 7 分钟阅读。
「TakinTalks 稳定性社区」公众号后台回复 “交流” 进入读者交流群;回复“1151”获取讲师课件;回复“混沌”获取《混沌工程实践指南》。
背景
过去 3 年的混沌工程实践中,我们对基础设施、应用、依赖、攻防等做了 4 个阶段的能力建设,搭建了能力相对完善的混沌工程平台。那么,在有这些基础能力的前提下,我们怎么确保它们能够得到执行、能最大限度发挥价值?
可能你经常能看到,业界有这样一种声音,既然线上的随机性演练能力已经具备了,那么在公司内培养混沌工程文化,让团队主动去执行这些演练,就能达到大规模演练的目的了。
而从我的实践经验来看,这样做会导致时效非常慢。因为完全靠文化驱动,其实很难保证覆盖面——很多时候可能只有 20% 的同学是喜欢尝试新技术的,他们自身热衷参与到这些创新的事情中来,但剩下的大部分同学,有的因为开发和日常任务多,并不会非常主动地、自发地去做。所以,完全依靠“文化建设”这个软性条件约束,很难达到大规模的演练效果。
在去哪儿的实践中,我们保障落地效果最核心的动作,是建立了一套大规模演练的机制,接下来我会具体介绍这套机制,以及大规模故障演练的落地效果。
一、大规模演练前遇到了哪些问题?
1.1 覆盖面的问题
应用数量和系统现状,很大程度限制了我们的人工演练覆盖面。在去哪儿网,我们的应用数量高达 3000 多个,同时提供超过 18000 个 dubbo 服务接口,在网关上注册的 HTTP 域名也超过 3500 个,在 MQ 上注册的消息主题也有超过 13000 个,公司内部大概有 5 种语言技术栈(以 Java 为主)。

在这样情况下,我们要去发动所有人进行人工演练,来保证大规模故障演练的覆盖面,其实是不太现实的——我们可以做一个假设性的尝试,对每一个应用发起人工演练,假设每个应用只需要 0.2 人日做完(这是一个非常短的时间),在 3000 +应用的规模情况下,则至少需要大几百人日才能完成。
而且,稳定性的保障并不是运动式的做一次就能够一劳永逸了,系统一直在演进、一直在变化,就需要我们跟随着不断去演练,才能发现新增的问题。如果是以这么高的人力付出来看,演练很难达到非常大的覆盖面,也就无法达成很好的演练效果。
1.2 人工成本问题
我们上面说的 0.2 人日,其实已经是非常小的数据,真正的人力成本会比它高很多,因为在演练过程中,很多地方需要人工参与,比如,演练之前的准备、计划的制定、演练过程中的观察、人工触发恢复,然后还有复盘、改进计划等等,这些都需要有人工的参与。
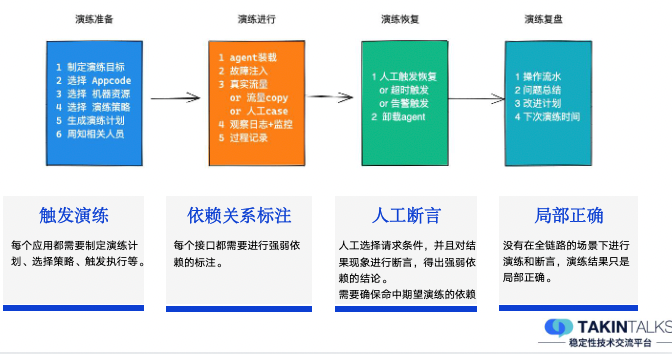
人力成本这部分,从去哪儿的实践来看,主要集中在以下这几个核心点上:
触发演练:这里一定需要有人工的参与,因为虽然有可能是定时的,但是在那个时间点,是必须要有人工盯着的,去观察和触发执行。
依赖关系标注:演练中,每个接口都需要强弱依赖的关系标注,也会消耗掉一部分的人力成本。
人工断言:演练的结果出来后,需要人工断言这个结论到底对不对、是强弱依赖的里面的哪一种、要确保演练的流量经过了这次注入的这个问题点等等。
局部正确:在没有全链路的情况下,需要对局部演练产生的断言结论,进行全局性的正确性修正。
以上这些,都需要人力投入,而且这部分人工的成本想要清除,其实是比较难的。
1.3 大规模演练技术难点
之前我们大概抽象出来大规模的非人工自动演练,它会有几个难点。
线上环境需要隔离
当我们要进行非常大规模的演练时,线上环境中的数据,比如,产生的无用订单、各类计费的数据、日志的污染、其他的存储等等,一系列的数据都需要隔离出来,不然大规模的演练流量会影响线上正常业务数据的保存。
演练流量从何而来
从人工的随机演练变成了自动的大规模演练后,人工触发就不现实了,此时就需要考虑流量从哪来的问题。
如何自动断言结果
需要做到自动断言强弱依赖的结果,演练过程中到底有没有产生影响,这个断言如何做?
如何确保命中率
命中率是指对依赖进行演练时,流量是否真的经过了依赖。从去哪儿的实践来看,正常情况下,只有大概 40% 的命中率。
二、问题是如何逐个解决的?
2.1 全链路演练流量和隔离
为了解决前两个问题——线上环境隔离和演练流量,我们使用了全链路压测平台(这个平台也是我们团队在负责)来支持。
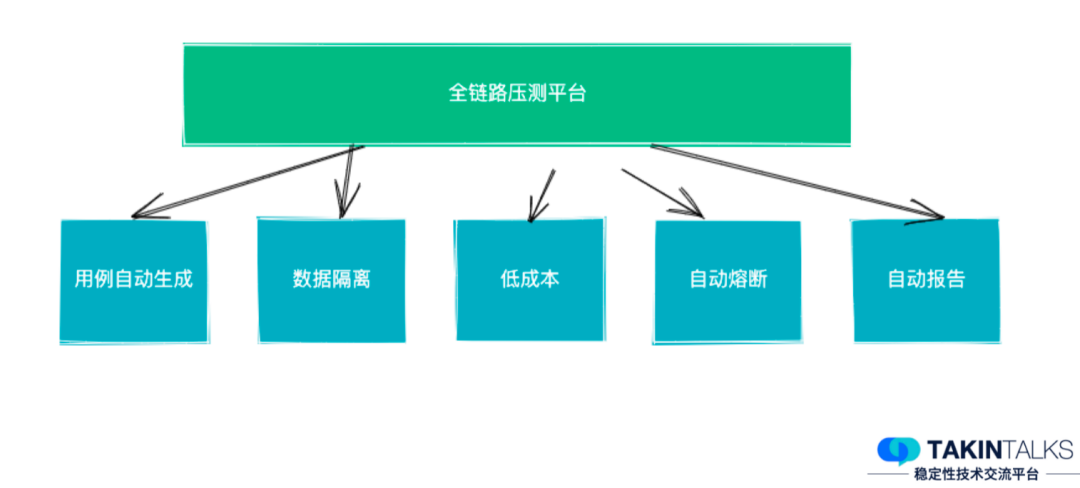
去哪儿的全链路压测平台能够做到用例自动生成,线上数据、日志数据都能通过它做隔离,而且它的成本非常低——去哪儿现在基本上全公司的核心场景压测,大概只需要 3 人日就能全部压测一遍,而且它能够进行自动熔断、自动报告。
有了这个压测的平台后,我们就可以把它和混沌工程的过程组合起来,实现线上环境隔离和演练流量的生成。
2.2 全链路演练断言
对于全链路演练的断言,我们做了一个比较有效的实践——把所有的断言逻辑挪回到入口级别。我们系统的拓扑是非常复杂的,但判断当下演练的下游依赖有没有产生故障,最终的判断标准无非就是那么几个——
第一个:对于 C 端的用户,这个功能真正的用户有没有受影响。
第二个:有没有金额上的损失,有没有数据上的问题。
第三个:一些核心的数据,比如用户或者订单会不会受干扰。
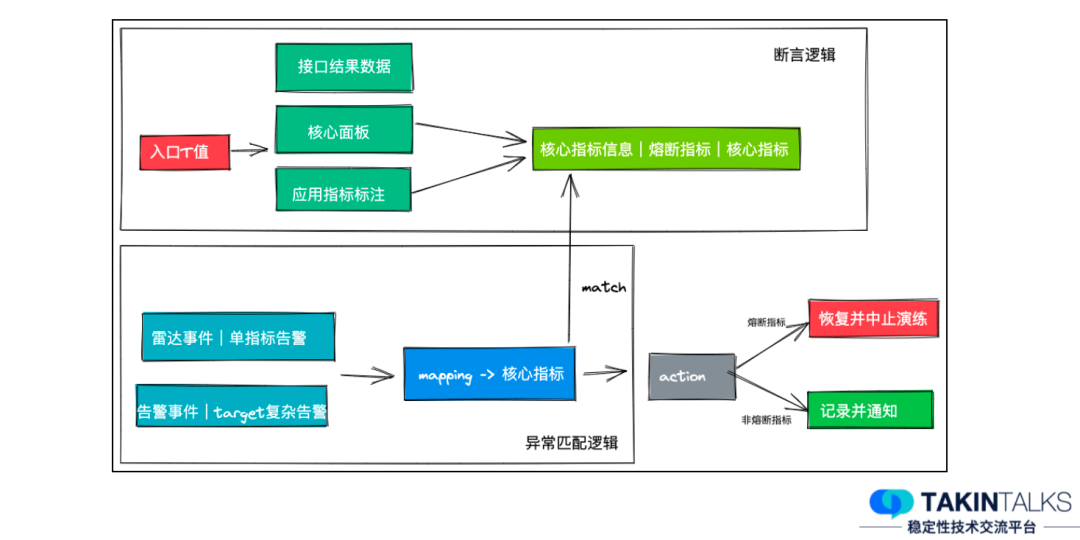
基于此,我们就可以做这样的收敛。
第一,对入口的结果数据进行结果对比,核心的业务字段对比产生断言结论。
第二,统一监控告警平台的核心面板,方便演练过程中监控告警信息,用于熔断演练过程和断言结论。
第三,在每个应用上对核心指标进行标注,去看它有没有产生大的抖动,进而用于断言结论。
我们基于一套比较完善的断言逻辑构建了断言平台,这个平台主要依赖上图中的这几类指标,特别是告警的指标,除了有人工设置的告警之外,还有雷达系统对相应的告警监控走势图进行智能分析,我们就能收集到非常完善的告警和结果信息。
对这份指标进行分析,就能得到当下这个演练被命中的时候,它对入口的影响是强依赖还是弱依赖。而且在这个过程之中,我们可以随时恢复或者终止演练。如果演练过程中没有问题,我们最终会给它标注上断言结果,这样就能达到自动断言的效果。
2.3 自动化演练流程
我们全链路演练的流程大概是这样的。
第 1 步:从应用的信息平台上获取各类依赖信息,比如 HTTP 接口、RPC 接口。
第 2 步:从自动化测试平台获取入口对应应用的流量。
第 3 步:对应用线上环境进行故障注入。
第 4 步:发起两份请求。为什么要发起两份请求?主要是对比被注入了故障的机器实例和没被注入故障的机械实例,对同样的请求产生的结果到底是什么样的。图中的基准环境和测试环境,实际上都是线上环境。
第 5 步:进行故障恢复。
第 6 步:对各类数据进行分析,产生断言结论。
第 7 步:把这个强弱依赖的结果自动记录下来。
这样我们就几乎可以无人力成本地去完成一次演练,在这个过程中需要人工介入的只有制定演练计划,而且这个演练计划在常态化演练中是可以复用的。
2.4 提升命中率
从去哪儿的演练效果来看,如果选取的入口压测流量是非常随机的策略,那么大概只有 40% 的下游依赖的命中率。
比如下图 F -> N 的流量,它只属于 trace 1 ,trace 2 和 trace 3 这两个请求虽然都是同样的功能同样的入口,但它们不会经过 F -> N 这个接口依赖。这个 40% 的命中率显然是不符合我们要求的,为了演练效率,我们期望命中率高于 90%。
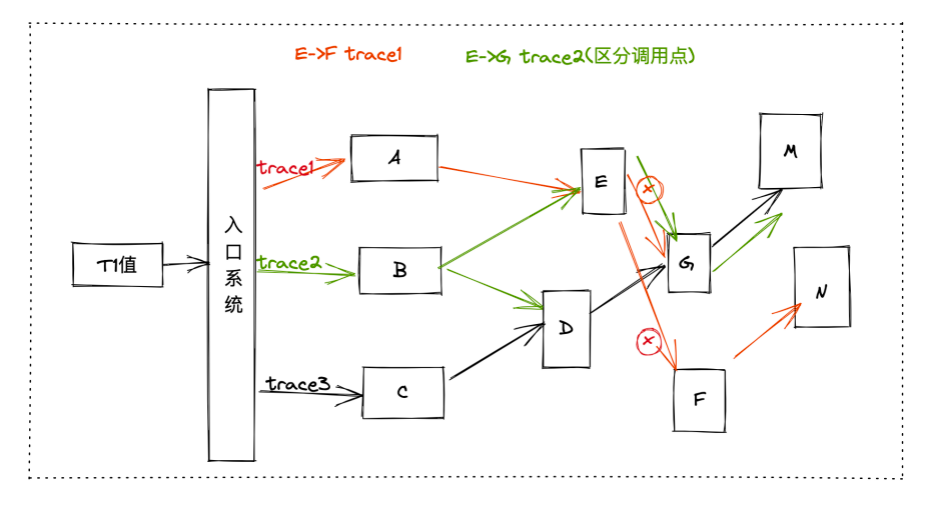
对于命中率的提升,我们比较有效的一个实践点,是利用 trace 的拓扑信息反查,即当我们需要演练时,如演练 E -> F 的这个依赖时,通过 trace 信息就能提前反查出来 trace1 的这个入口条件,即 trace1 这个请求对应的请求参数,能够命中 E -> F 的这个流程。
如果是 E -> G 的这个流程,可能会有不同的调用点,因为 trace1 和 trace2 都经过了这里,此时如果想要演练 trace2 的链路对应的接口调用点,需要以同样的方式去反查,它才会经过这个调用点,然后产生 E -> G 的这个依赖。
通过这样的方式实践之后,我们命中率已经提升到 90% 以上,是一个比较可以接受的量级。剩下不到 10%非命中的情况到底是什么呢?其实是系统缓存,缓存被命中之后,它就不会接着往下走,也就不会再产生下游的访问依赖。
所以只需要去按照 APM 系统 trace 的信息去进行反查,就能获得是比较高的命中率。
三、大规模演练落地效果如何?
从这个大规模演练的这些效果来看,我们现在覆盖了公司 55 个核心场景链路和 269 个接口的入口,基本上覆盖了所有业务场景。
这些场景链路里,比如机票报价或者是酒店生单这样的场景里面,我们基本上覆盖了 80% 以上的应用依赖,即全公司 3000 多个应用,我们覆盖了八成左右。
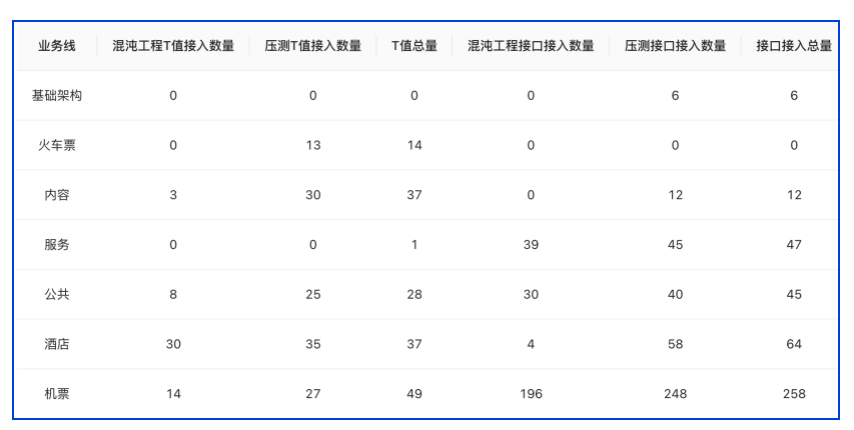
从这个自动化机制落地之后,去哪儿就可以做非常大规模的演练了,我们现在做这种大规模的演练,人工的成本已经非常低了。现在遗留下来的人工成本,主要是分析最后的依赖结论是否和预想一致即可。
Q&A
1、稳定性投入类指标和结果类指标如何衡量?
2、去哪儿目前在稳定性投入上,哪些手段是比较有效的?
欢迎关注「TakinTalks 稳定性社区」公众号及视频号!
了解更多去哪儿网大规模演练细节,欢迎扫码进入「读者交流群」,和老师实时互动。

回复【1151】获取讲师课件
回复【交流】进入读者交流群
更多内容欢迎点击“阅读原文”,进入「TakinTalks 稳定性社区」,观看完整版视频内容。
声明:本文由公众号「TakinTalks 稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
最新文章
- MySQL5.7不停业务将传统复制变更为GTID复制
- qt越来越好了
- SQLServer安装正常服务启动正常却无法连接
- win7运行sqlplus报错“SP2-1503: 无法初始化 Oracle 调用界面”
- Ubuntu 12.04环境下配置Postgresql和phppgadmin
- Button MouseEvent颜色变化
- Java中byte与16进制字符串的互换原理
- NOI2006 郁闷的出纳员
- centos7环境下apache2.2.34的编译安装
- (转) java 通过 jdbc 链接 ms sql server 中出现 "no suitable driver for ..."
- 【Java每日一题】20170217
- dom定位的三种元素
- 使用pyinstaller打包python小程序(没有使用第三方模块)
- Python 再次改进版通过队列实现一个生产者消费者模型
- LeetCode OJ 143. Reorder List(两种方法,快慢指针,堆栈)
- ui设计用什么软件
- 根据twitter的snowflake算法生成唯一ID
- markdown table语法
- CASE:DB shutdown/open 过程中发生异常导致JOB不能自动执行
- 【CF913G】Power Substring 数论+原根