[Oracle] 关系型数据库排序算法和数据结构以及关联查询
关系型数据库排序算法和数据结构以及关联查询
1. Merge sort
理解merge sort算法将有助于更好地理解数据库join操作 - merge join
算法逻辑
将2个有序的大小为N/2的队列合并为N元素的有序队列

上面是排序最后的8元素数组, 仅仅需要重复一次2个4元素的数据排序(4元素已经是有序的了):
- 比较2个数组中的第一个元素
- 将较小的一个元素放在有序的8元素队列中
- 然后再从较小的元素所在的4元素数组中拿到下一个元素
- 将第三步中拿到的元素与第一步比较中较大的元素再比较, 将较小的一个元素放在有序的8元素队列中
- 重复上面的步骤, 直到其中一个数据比较完成
下面是实现的伪代码:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if //递归调用
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array); //将2个小的有序的数组合并为一个大的
array result := merge(new_left_array,new_right_array);
return result;
Merge sort将一个问题分为小的问题, 然后找到小问题的结果, 最终得到原始问题的结果. 其实是一个两阶段的算法:
- 分裂阶段: 大数组被分裂为小数组
- 排序阶段: 小数组合并为有序的大数组
分裂阶段

在分裂阶段, 数组被分裂为单一的数组需要3步, 这里的复杂度是log(N) (N=8, log(N)=3)
排序阶段

排序阶段, 成本是N=8的操作.
- 第一步需要4次merge, 每次花费2个操作
- 第二步需要2次merge, 每次花费4个操作
- 第三步需要2次merge, 每次花费8个操作
log(N)步merge, 总的花费N*log(N)个操作.
2. Arrary
现在流行的数据库都提供用数组来存储表, 例如: 堆组织表(Heap-organized tables), 索引组织表(Index-organized tables), 但这并不解决快通过多列来速搜索特定的条件;
3. Tree
B-Tree
在二叉搜索树中,
- 所有的节点键值都大于左边子树的节点键值
- 所有的节点键值都小于右边子树的节点键值
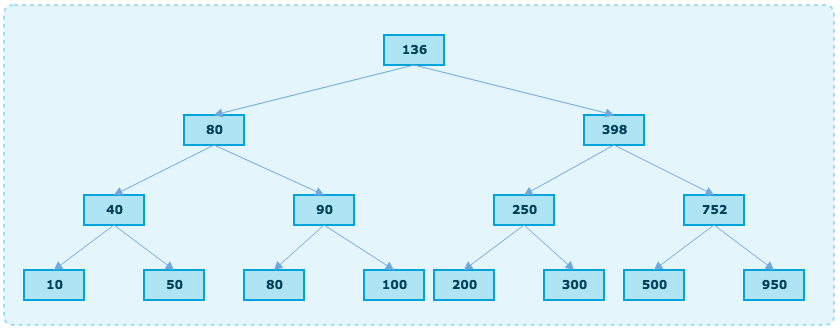
这个树有N=15个元素, 如果搜索208的过程是:
- 从根节点开始(key=136), 由于136<208, 因此应该搜索跟节点右侧的子树
- 由于398>208, 因此应该搜索节点398左侧的子树
- 由于250>208, 因此应该搜索节点250左侧的子树
- 由于200<208, 因此应该搜索节点200右侧的子树, 但是节点200没有右侧子树, 因此值208不存在
搜索的算法复杂度是log(N)
B+Tree Index
B-Tree最大的问题是无法做range query(范围搜索), 另外如果搜索2个值, 就需要进行完成的2次跟节点开始扫描的过程.
在B+Tree搜索中,
- 只有叶子节点存储数据信息
- 其他非叶子节点只是搜索中的一个路由信息
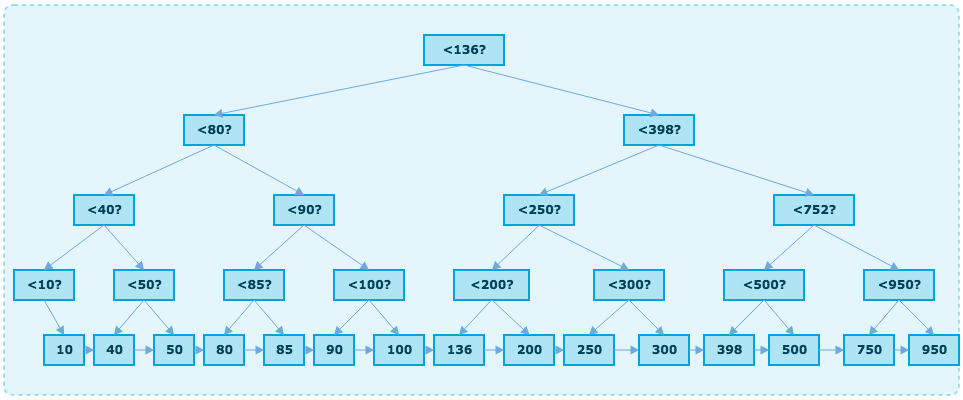
B+Tree的节点是有序的以及平衡的, 这也引来了一个问题: B+Tree的分裂
4. Hash table
用hash table来快速查找一个值是非常有效的, 一个好的hash函数可以做到搜索复杂度是O(1); 理解hash table可以更好的理解数据库表链接操作 - hash join; 这个数据结构在数据库中被用来存储内部的东西(譬如: lock table或者buffer pool);
构建一个hash table需要定义:
元素的key值
key的hash function (计算hash key的函数, 可以得到元素的位置信息, 一般叫做桶(buckets))
key的比较函数 (当找到对应的bucket后, 需要在bucket中查找元素)

最大的挑战是定义一个好的hash function, 得到包含尽可能少元素的buckets串;
Arrary vs hash table
- hash table可以**half loaded in memory, 剩下的buckets可以在disk上
- 而数组则需要在内存中使用连续的空间, 如果需要加载一个large table, 那么很难做到有足够的内存空间
- hash table可以选择所需要的key
5. 关联查询
传统的关系型数据数据有3种常见的关联操作: Merge Join, Hash Join, Nested Loop Join.
Nested loop join
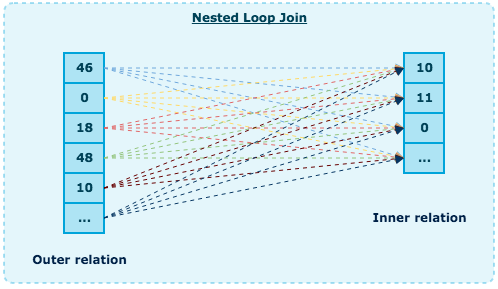
- Outer relation的每一行都会去扫描Inner relation, 输出匹配的记录
伪代码如下:
nested_loop_join(array outer, array inner)
for each row a in outer
for each row b in inner
if (match_join_condition(a,b))
writer_result_in_output(a,b)
end if
end for
end for
因此这是一个嵌套迭代, 时间复杂度是O(N*M) //加入outer relation有N行, inner relation有M行
在磁盘I/O上, outer relation里N行中的每一行, inner loop都需要读取inner relation里M行, 这个算法需要从磁盘读取N+N*M行, 如果inner relation足够小, 可以cache在buffer里, 那么只需要读取磁盘M+N行.
上面这个算法是最基本的, 但是如果inner relation过大而无法cache到memory, 下面这个是对磁盘更友好的算法:
- 代替一行一行的读取
- 每次批量读取并且cache到memory
- 在内存cache的批量数据里比较outer bunch的每一行是否匹配inner bunch, 输出匹配纪录
- 再从disk load新的批量数据进入memory
- 直到disk上没有数据
伪代码如下:
// improved version to reduce the disk I/O.
nested_loop_join_v2(file outer, file inner)
for each bunch ba in outer
// ba is now in memory
for each bunch bb in inner
// bb is now in memory
for each row a in ba
for each row b in bb
if (match_join_condition(a,b))
writer_result_in_output(a,b)
end if
end for
end for
end for
end for
这个版本的时间复杂度没变, 但是减少了磁盘操作.
Hash join
Hash join将会更复杂一些, 但是在很多情况下比Nested Loop Join有更少的成本开销
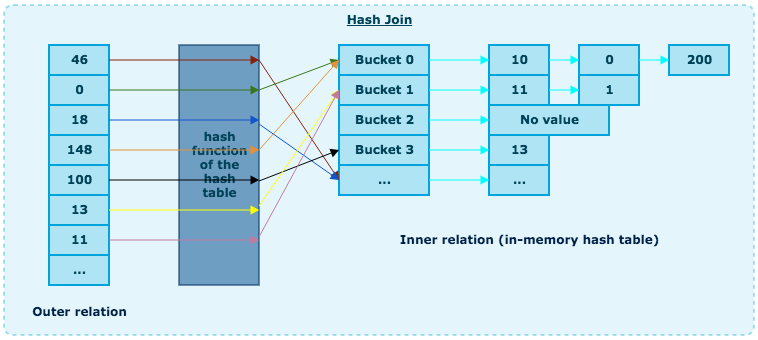
- 得到所有inner relation的元素
- 在内存中构建hash table
- 一个一个得到outer relation的元素
- 用hash funcation计算每一个outer relation的元素, 找到关联的inner relation bucket
- 比较bucket中的元素是否与outer relation中的匹配, 匹配则输出
时间复杂度: (M/X)*N + cost_to_create_hash_table(M) + cost_of_hash_function(N), 如果hash function足够好, 得到足够小的buckets, 那么时间复杂度是: O(M+N)
Merge join
Merge Join是唯一会产生排序操作的链接操作
- Sort Join Operation: 根据join key来排序
- Merge Join Operation: 将排序的结果merge在一起
Sort
前面已经描述过sort过的过程了, 在Merge Join中往往很多时候数据结果集已经是有序的, 譬如:
- 如果表本身就是有序的, 譬如IOT表(index-organized table)的join列
- join条件是有索引的
- 基于有序的中间结果的join
Merge Join
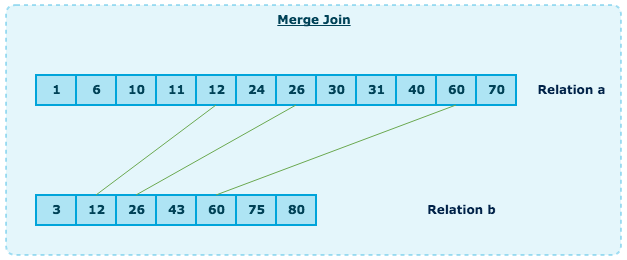
Merge Join本身和前面的Merge Sort是很类似的, 但这次, 只是在2个集合中挑选相等的元素出来, 而不是从2个集合中拿所有的元素.
- 比较2个集合中当前的元素(当前指的是首次, 第一次)
- 如果相等, 结果中输出元素, 下来比较2个集合中下一个元素
- 如果不相等, 在较小的元素的集合中去下一个元素来比较(由于集合都是有序的)
- 重复上述, 直到任一集合中到最后一个元素
如果2个集合都是有序的, 那么时间复杂度是: O(M+N);
如果集合需要排序, 那么时间复杂度是: O(N*Log(N) + M*Log(M));
mergeJoin(relation a, relation b)
relation output
integer a_key:=0;
integer b_key:=0; while (a[a_key]!=null or b[b_key]!=null)
if (a[a_key] < b[b_key])
a_key++;
else if (a[a_key] > b[b_key])
b_key++;
else //Join predicate satisfied
//i.e. a[a_key] == b[b_key]
//count the number of duplicates in relation a integer nb_dup_in_a = 1;
while (a[a_key]==a[a_key+nb_dup_in_a])
nb_dup_in_a++ integer nb_dup_in_b = 1;
while (a[a_key]==a[a_key+nb_dup_in_b])
nb_dup_in_b++ //write the duplicates in output for (int i = 0; i<nb_dup_a; i++)
for (int j = 0;i<nb_dup_a; i++)
write_result_in_output(a[a_key+i], b[b_key+j])
a_key=a_key + nb_dup_in_a-1;
b_key=b_key + nb_dup_in_b-1; end if
end while
哪一种Join算法是最好的呢?
几个关键因素:
- 空闲内存大小: 没有足够的内存基本可以和强大的hash join说再见了(hash join至少需要full in-memory)
- 2个数据集合的大小: 如果是一个大表和一个小表, nested loop join将会比hash join快(hash join会有更大代价的构建hash table); 如果是2个大表, nested loop join将是非常耗cpu的
- join条件是否存在index: 如果2个集合均有B+Tree, 那么merge join将会是更好的选择
- 结果集是否需要排序: 即使处理的是乱序的数据集合, 由于结果集需要有序, 可能也会使用成本更高的merge join
- 数据集是否有有序的: 如果是, 那么merge join将是最佳的选择
- 数据分布: join条件的列是否是倾斜的(譬如join条件是last name, 但是很多人拥有相同的last name), 那么使用hash join将是很有效的
最新文章
- iOS的主要框架介绍
- Windows64 系统下Python、NumPy与matplotlib 安装方法
- 开发成功-cpu-mem监控动态折线图--dom esayui js java
- 蓝桥杯--- 历届试题 大臣的旅费 (DFS & Vector)
- UVA 10892 - LCM Cardinality
- debian root用户在shell下如何能够使用颜色
- AWVS介绍
- [GDKOI2016]小学生数学题
- Android - ContentProvider机制
- gitweb随记
- linux vi编辑常用命令
- java输出日期时间
- python实战===使用smtp发送邮件的源代码,解决554错误码的问题,更新版!
- 潜谈IT从业人员在传统IT和互联网之间的择业问题(上)-传统乙方形公司
- Element表格嵌入复选框以及单选框
- 2. VIM 系列 - 初探vim配置文件
- 【Android Studio安装部署系列】三十、从Android studio2.2.2升级到Android studio3.0之路
- hdu-4612(无向图缩点+树的直径)
- LeetCode 20. Valid Parentheses(c++)
- 布局优化之ViewStub源码分析