kafka topic制定规则
2024-08-28 14:22:19
kafka topic的制定,我们要考虑的问题有很多,比如生产环境中用几备份、partition数目多少合适、用几台机器支撑数据量,这些方面如何去考量?笔者根据实际的维护经验,写一些思考,希望大家指正。
1.replicas数目
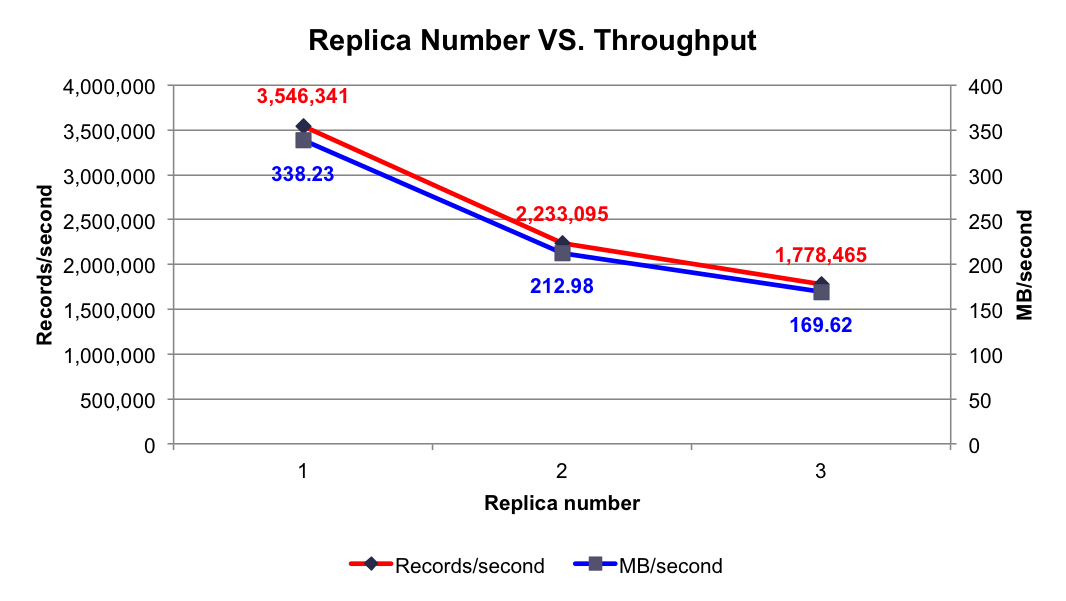
可以从上图看到,备份越多,性能越低,因为kafka的写入只写入主分区,备份相当于消费者从主分区pull数据,这样势必会造成性能的损耗,故建议在生产环境中使用一主一备即可。
2. partition数量
(1)设置partition数量的时候我们需要注意:kafka的partition可以在创建时候指定,也可以alter(kafka-topic.sh里面的参数),但是,这个修改只能增加partition数目,并不能减少。这带来的直接影响就是我们在设置按照日志数量回滚数据的时候(即:设置log.retention.bytes控制日志清除),需要考虑大小,因为log.retention.bytes设置的是partition的日志大小。
(2)partition的数目并不是越多越好,以下是笔者所做的性能测试。
//todo
可以看到,当partition数目是broker数目的整数倍的时候,它的TPS较高,非整数倍的时候,由于数据不均衡,所以TPS会有不同程度的影响。
3.消费速度
消费速度需要进行性能测试做相应评估,消费者/生产者加机器,都可以带来性能的线性增加。
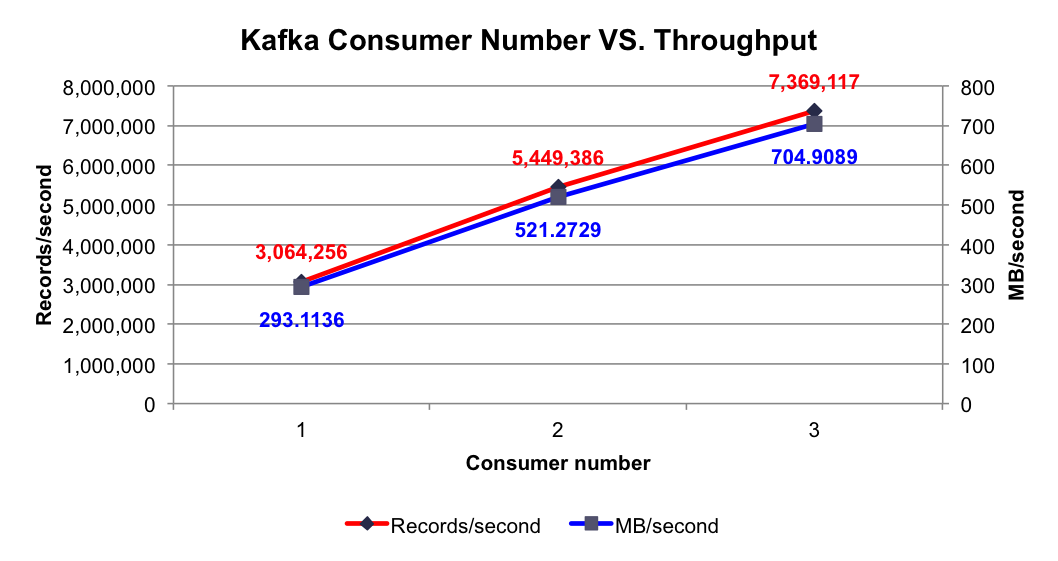
4.制定规则
综上考虑,笔者在生产环境中的实践规则如下:
- Partition数量=broker数量*2[这个作为预先设置,设置小一点,如果线上机器不够,增加机器的话,同时topic也会增加2,增量不要设置太大]
- partition数量需要大于consumer数量
- partition数量过多会给consumer带来额外的开销,建议consumer线程数(消费者个数)设置为partition数目,或略小于即可。
- broker数量 =目标吞吐量/max(producer吞吐量,consumer吞吐量)
5.reference
How to choose the number of topics/partitions in a Kafka cluster?
关注我的技术公众号,第一时间获取新鲜技术文章:

最新文章
- 【集合框架】JDK1.8源码分析之HashMap & LinkedHashMap迭代器(三)
- 分享我基于NPOI+ExcelReport实现的导入与导出EXCEL类库:ExcelUtility (续3篇-导出时动态生成多Sheet EXCEL)
- Python之路【第四篇补充】:面向对象初识和总结回顾
- 【转】flash不建议设置wmode及wmode解释
- JAVA-语法-运算符
- Android Scrollview 内部组件android:layout_height="fill_parent"无效的解决办法
- 矩形类定义【C++】
- [Unity3D]Unity3D游戏开发Lua随着游戏的债券(于)
- zabbix_server---微信报警
- hdu1570(排列和组合公式的应用)
- 一次thinkphp框架 success跳转卡顿问题的解决
- ubuntu16.04下latex环境搭建
- Jquery 选择器 特殊字符 转义字符
- ECharts注释
- tfs团队项目删除原来连接的默认账户
- PAT 1010 一元多项式求导 (25)(STL-map+思路)
- ibatIs中的isNotNull、isEqual、isEmpty
- vue项目在IE下报 [vuex] vuex requires a Promise polyfill in this browser问题
- 最短路 dijkstra 优先队列
- php学习五:数组操作