Impala储存与分区
不多说,直接上干货!



hive的元数据存储在/user/hadoop/warehouse
Impala的内部表也在/user/hadoop/warehouse。
那两者怎么区分,看前面的第一列。
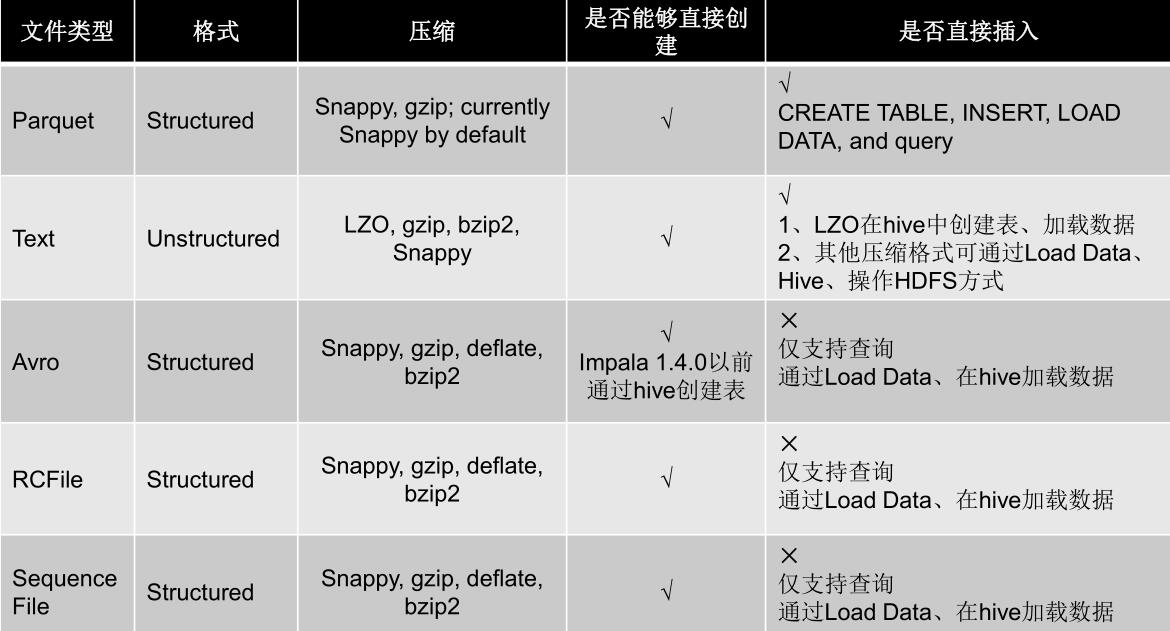
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);
• 分区内添加数据
insert into t_person partition (type='boss') values (,’zhangsan’,),(,’lisi’,)
insert into t_person partition (type='coder') values(,wangwu’,),(,’zhaoliu’,),(,’tianqi’,)
• 查询指定分区数据
select id,name from t_person where type=‘coder
进行数据分区将会极大的提高数据查询的效率,尤其是对于当下大数据的运用,是一门不可或缺的知识。那数据怎么创建分区呢?数据怎样加载到分区
一、 Impala/Hive按State分区Accounts
(1)示例:accounts是非分区表

通过以上方式创建的话,数据就存放在accounts目录里面。那么,如果Loudacre大部分对customer表的分析是按state来完成的?比如:

这种情况下如果数据量很大,为了避免全表扫描的发生,我们可以去创建分区。如果不创建分区的话,它会默认所有查询不得不扫描目录的所有文件。创建分区按state将数据存储到不同的子目录,当按照“NY”的条件进行查询的时候,它只会扫描到子目录,下面我具体来看一下分区创建。
二、分区创建
(1)使用PARTITIONED BY来创建分区表

在这里注意state是被删除掉的,因为它作为分区字段,我们知道分区数据是不会出现在实际的文件当中的,所以state作为分区字段是不会出现在列当中的。换句话说,分区键就是一个虚列,它是不会存在列当中的。那么,如何去查看我们分区的列呢?它会出现在我们的结构当中吗?会的。
三、查看分区列
使用DESCRIBE显示分区列,它会出现在结构最后一列,它是一个虚列,并不是真实在数据中存在的列。

我们创建单个分区,但有时候会有嵌套分区,如何来处理呢?
四、创建嵌套分区:

创建好了分区,我们怎么加载数据到分区呢?有两种方式动态分区和静态分区。动态分区是指Impala/Hive在加载的时候自动添加新的分区,数据基于列值存储到正确的分区(子目录)。而静态分区需要我们通过ADD PARTITION提前去定义分区的名称,当加载数据的时候,指定存储数据到哪个分区。那么动态分区和静态分区各有什么特征呢?后续为大家接着分享。
最新文章
- 手动安装m4, autoconf, automake, libtool
- Android 通过 Wifi 调试 Debug (Android Studio)
- JavaWeb基础: Tomcat
- The C10K problem
- fatal: Not a git repository (or any of the parent directories): .git
- 文件I/O操作(1)
- javascript中部分不能使用call apply调用来重写的构造函数
- OS X: Keyboard shortcuts
- GemFire
- 15.vue使用element-ui的el-input监听不了回车事件
- Tableau的简单数据可视化操作
- CSS中垂直居中的方法
- BZOJ 1968: [Ahoi2005]COMMON 约数研究(新生必做的水题)
- FreeNas搭建踩坑指南(三)
- Navicat再次激活
- python常用程序算法
- 查找mac下腾讯视频下载地址
- 一、集合框架(关于ArrayList,LinkedList,HashSet,LinkedHashSet,TreeSet)
- unity, Collider2D.attachedRigidbody
- openfire聊天记录插件