darknet是如何对数据集做resize的?
在准备数据集时,darknet并不要求我们预先对图片resize到固定的size. darknet自动帮我们做了图像的resize.
darknet训练前处理
本文所指的darknet版本:https://github.com/AlexeyAB/darknet
./darknet detector train data/trafficlights.data yolov3-tiny_trafficlights.cfg yolov3-tiny.conv.15
main函数位于darknet.c
训练时的入口函数为detector.c里
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show, int calc_map, int mjpeg_port, int show_imgs)
{
load_args args = { 0 };
args.type = DETECTION_DATA;
args.letter_box = net.letter_box;
load_thread = load_data(args);
loss = train_network(net, train);
}
函数太长,只贴了几句关键的.注意args.type = DETECTION_DATA;
data.c中
void *load_thread(void *ptr)
{
//srand(time(0));
//printf("Loading data: %d\n", random_gen());
load_args a = *(struct load_args*)ptr;
if(a.exposure == 0) a.exposure = 1;
if(a.saturation == 0) a.saturation = 1;
if(a.aspect == 0) a.aspect = 1;
if (a.type == OLD_CLASSIFICATION_DATA){
*a.d = load_data_old(a.paths, a.n, a.m, a.labels, a.classes, a.w, a.h);
} else if (a.type == CLASSIFICATION_DATA){
*a.d = load_data_augment(a.paths, a.n, a.m, a.labels, a.classes, a.hierarchy, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
} else if (a.type == SUPER_DATA){
*a.d = load_data_super(a.paths, a.n, a.m, a.w, a.h, a.scale);
} else if (a.type == WRITING_DATA){
*a.d = load_data_writing(a.paths, a.n, a.m, a.w, a.h, a.out_w, a.out_h);
} else if (a.type == REGION_DATA){
*a.d = load_data_region(a.n, a.paths, a.m, a.w, a.h, a.num_boxes, a.classes, a.jitter, a.hue, a.saturation, a.exposure);
} else if (a.type == DETECTION_DATA){
*a.d = load_data_detection(a.n, a.paths, a.m, a.w, a.h, a.c, a.num_boxes, a.classes, a.flip, a.blur, a.mixup, a.jitter,
a.hue, a.saturation, a.exposure, a.mini_batch, a.track, a.augment_speed, a.letter_box, a.show_imgs);
} else if (a.type == SWAG_DATA){
*a.d = load_data_swag(a.paths, a.n, a.classes, a.jitter);
} else if (a.type == COMPARE_DATA){
*a.d = load_data_compare(a.n, a.paths, a.m, a.classes, a.w, a.h);
} else if (a.type == IMAGE_DATA){
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = resize_image(*(a.im), a.w, a.h);
}else if (a.type == LETTERBOX_DATA) {
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = letterbox_image(*(a.im), a.w, a.h);
} else if (a.type == TAG_DATA){
*a.d = load_data_tag(a.paths, a.n, a.m, a.classes, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
}
free(ptr);
return 0;
}
根据a.type不同,有不同的加载逻辑.在训练时,args.type = DETECTION_DATA,接着去看load_data_detection().
load_data_detection()有两套实现,用宏#ifdef OPENCV区别开来.我们看opencv版本
load_data_detection()
{
src = load_image_mat_cv(filename, flag);
image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, jitter, dhue, dsat, dexp);
}
注意load_image_mat_cv()中imread读入的是bgr顺序的,用cv::cvtColor做了bgr-->rgb的转换.
if (mat.channels() == 3) cv::cvtColor(mat, mat, cv::COLOR_RGB2BGR);
这里有个让人困惑的地方,为什么是cv::COLOR_RGB2BGR而不是cv::COLOR_BGR2RGB,实际上这两个enum值是一样的,都是4.
见https://docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html
https://github.com/pjreddie/darknet/issues/427
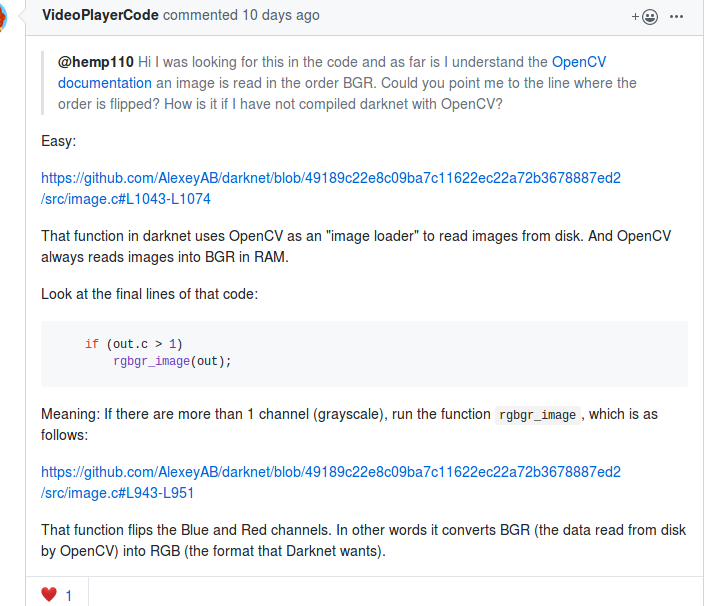
所以在做推理的时候,也应该转换到rgb的顺序.
image_data_argmentation()的主要逻辑
cv::Mat cropped(src_rect.size(), img.type());
//cropped.setTo(cv::Scalar::all(0));
cropped.setTo(cv::mean(img));
img(new_src_rect).copyTo(cropped(dst_rect));
// resize
cv::resize(cropped, sized, cv::Size(w, h), 0, 0, cv::INTER_LINEAR);
其实主要就是cv::resize. 这里cropped的img是在原图上随机截取出来的一块区域(当然是有范围的).
在load_data_detection()中有这样一段逻辑,生成pleft,pright,ptop,pbot. 这些参数被传递给image_data_argmentation(),用以截取出cropped image.
int oh = get_height_mat(src);
int ow = get_width_mat(src);
int dw = (ow*jitter);
int dh = (oh*jitter);
if(!augmentation_calculated || !track)
{
augmentation_calculated = 1;
r1 = random_float();
r2 = random_float();
r3 = random_float();
r4 = random_float();
dhue = rand_uniform_strong(-hue, hue);
dsat = rand_scale(saturation);
dexp = rand_scale(exposure);
flip = use_flip ? random_gen() % 2 : 0;
}
int pleft = rand_precalc_random(-dw, dw, r1);
int pright = rand_precalc_random(-dw, dw, r2);
int ptop = rand_precalc_random(-dh, dh, r3);
int pbot = rand_precalc_random(-dh, dh, r4);
int swidth = ow - pleft - pright;
int sheight = oh - ptop - pbot;
float sx = (float)swidth / ow;
float sy = (float)sheight / oh;
float dx = ((float)pleft/ow)/sx;
float dy = ((float)ptop /oh)/sy;
这么做的目的是,参考作者AlexeyAB大神的回复:
https://github.com/AlexeyAB/darknet/issues/3703
Your test images will not be the same as training images, so you should change training images as many times as possible. So maybe one of the modified training images of the object coincides with the test image.
这里,我此前一直有个错误的理解,在train和test时对image的preprocess应该是完全一致的.大神的回复意思是,并非如此,在train的时候应该尽可能多地使训练图片产生一些变化,因为测试图片不可能与训练图片是完全一致的,这样的话,才更有可能使测试图片与某个随机变化后的训练图片吻合.
但是之前,我在issue里有看到有人训练出来的模型效果并不好,改变了image的preprocess以后,效果就好了.这一点还有待研究.
原始的darknet里图像的preprocess用的是letterbox_image(),AlexeyAB的版本里用的是resize.据作者说这一改变使得对小目标的检测效果更好.
参考https://github.com/AlexeyAB/darknet/issues/1907 https://github.com/AlexeyAB/darknet/issues/232#issuecomment-336955485
resize()并不会保持宽高比,letterbox_image()会保持宽高比.作者认为如果你的dataset的train和test中图像分辨率一致的话,是没有必要保持宽高比的.
darknet 推导前处理
detector.c中
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh,
float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile)
{
image im = load_image(input, 0, 0, net.c);
image sized = resize_image(im, net.w, net.h);
}
这里的resize_image是用C实现的,和cv::resize功能相同
/update 20190821***************/
darknet数据预处理
- 数据加载入口函数void *load_thread(void *ptr)
根据args.type不同有不同加载逻辑 - 喂给模型的输入并不是你训练图片的原始矩阵,darknet自己会做一些数据增强的操作,比如调整对比度,色相,饱和度,对图片旋转角度,翻转图像等等.
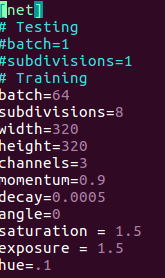
这些是配置在配置文件中的.
具体做了哪些数据增强,要自己看源代码,args.type不同,加载逻辑也略有差异
以./darknet detector train ....,即做目标检测的训练为例的话,对色相/饱和度/对比度的调整代码如下,位于image.c中

基本上前处理的代码都位于data.c,image.c中,image.c里是对图像矩阵的具体操作函数,data.c里是一些调用这些函数的控制流程.
当训练图片特别小时,不同的preprocess对喂给模型的代表图片的矩阵的影响就很大.所以最好先手动resize到模型的input size.
最新文章
- google closure--继承模块二:goog.base()demo分析
- XML是什么东西
- LIS (最长上升子序列)
- Java [Leetcode 112]Path Sum
- K2 Blackpearl 4.6.8 安装步骤详解
- ECMall模板开发文档
- 致终将火爆的NFC——ISO14443 TypeA
- POJ 3619 Speed Reading(简单题)
- broadcom6838开发环境实现函数栈追踪
- 数字IC设计-15-DPI(延续)
- RabbitMQ Cluster群集安装配置
- linux下 ls -l 命令显示结果每一列代表什么意思
- python入门(8)数据类型和变量
- 《python for data analysis》第五章,pandas的基本使用
- ElasticSearch是如何实现分布式的?
- php获取用户真实IP和防刷机制
- Dubbo学习笔记4:服务消费端泛化调用与异步调用
- ios开发之--随机背景颜色
- 【LOJ】#2430. 「POI2014」沙拉餐厅 Salad Bar
- lor框架代码分析