Python豆瓣书籍信息爬虫
2024-08-27 12:18:16
练习下BeautifulSoup,requests库,用python3.3 写了一个简易的豆瓣小爬虫,将爬取的信息在控制台输出并且写入文件中。
上源码:
# coding = utf-8
'''my words
基于python3 需要的库 requests BeautifulSoup
这个爬虫很基本,没有采用任何的爬虫框架,用requests,BeautifulSoup,re等库。
这个爬虫的基本功能是爬取豆瓣各个类型的书籍的信息:作者,出版社,豆瓣评分,评分人数,出版时间等信息。
不能保证爬取到的信息都是正确的,可能有误。
也可以把爬取到的书籍信息存放在数据库中,这里只是输出到控制台。
爬取到的信息存储在文本txt中。
''' import requests
from bs4 import BeautifulSoup
import re #爬取豆瓣所有的标签分类页面,并且提供每一个标签页面的URL
def provide_url():
# 以http的get方式请求豆瓣页面(豆瓣的分类标签页面)
responds = requests.get("https://book.douban.com/tag/?icn=index-nav")
# html为获得响应的页面内容
html = responds.text
# 解析页面
soup = BeautifulSoup(html, "lxml")
# 选取页面中的需要的a标签,从而提取出其中的所有链接
book_table = soup.select("#content > div > .article > div > div > .tagCol > tbody > tr > td > a")
# 新建一个列表来存放爬取到的所有链接
book_url_list = []
for book in book_table:
book_url_list.append('https://book.douban.com/tag/' + str(book.string))
return book_url_list #获得评分人数的函数
def get_person(person):
person = person.get_text().split()[0]
person = re.findall(r'[0-9]+',person)
return person #当detail分为四段时候的获得价格函数
def get_rmb_price1(detail):
price = detail.get_text().split('/',4)[-1].split()
if re.match("USD", price[0]):
price = float(price[1]) * 6
elif re.match("CNY", price[0]):
price = price[1]
elif re.match("\A$", price[0]):
price = float(price[1:len(price)]) * 6
else:
price = price[0]
return price #当detail分为三段时候的获得价格函数
def get_rmb_price2(detail):
price = detail.get_text().split('/',3)[-1].split()
if re.match("USD", price[0]):
price = float(price[1]) * 6
elif re.match("CNY", price[0]):
price = price[1]
elif re.match("\A$", price[0]):
price = float(price[1:len(price)]) * 6
else:
price = price[0]
return price #测试输出函数
def test_print(name,author,intepretor,publish,time,price,score,person):
print('name: ',name)
print('author:', author)
print('intepretor: ',intepretor)
print('publish: ',publish)
print('time: ',time)
print('price: ',price)
print('score: ',score)
print('person: ',person) #解析每个页面获得其中需要信息的函数
def get_url_content(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html.encode('utf-8'),"lxml")
tag = url.split("?")[0].split("/")[-1] #页面标签,就是页面链接中'tag/'后面的字符串
titles = soup.select(".subject-list > .subject-item > .info > h2 > a") #包含书名的a标签
details = soup.select(".subject-list > .subject-item > .info > .pub") #包含书的作者,出版社等信息的div标签
scores = soup.select(".subject-list > .subject-item > .info > div > .rating_nums") #包含评分的span标签
persons = soup.select(".subject-list > .subject-item > .info > div > .pl") #包含评价人数的span标签 print("*******************这是 %s 类的书籍**********************" %tag) #打开文件,将信息写入文件
file = open("C:/Users/lenovo/Desktop/book_info.txt",'a') #可以更改为你自己的文件地址
file.write("*******************这是 %s 类的书籍**********************" % tag) #用zip函数将相应的信息以元祖的形式组织在一起,以供后面遍历
for title,detail,score,person in zip(titles,details,scores,persons):
try:#detail可以分成四段
name = title.get_text().split()[0] #书名
author = detail.get_text().split('/',4)[0].split()[0] #作者
intepretor = detail.get_text().split('/',4)[1] #译者
publish = detail.get_text().split('/',4)[2] #出版社
time = detail.get_text().split('/',4)[3].split()[0].split('-')[0] #出版年份,只输出年
price = get_rmb_price1(detail) #获取价格
score = score.get_text() if True else "" #如果没有评分就置空
person = get_person(person) #获得评分人数
#在控制台测试打印
test_print(name,author,intepretor,publish,time,price,score,person)
#将书籍信息写入txt文件
try:
file.write('name: %s ' % name)
file.write('author: %s ' % author)
file.write('intepretor: %s ' % intepretor)
file.write('publish: %s ' % publish)
file.write('time: %s ' % time)
file.write('price: %s ' % price)
file.write('score: %s ' % score)
file.write('person: %s ' % person)
file.write('\n')
except (IndentationError,UnicodeEncodeError):
continue except IndexError:
try:#detail可以分成三段
name = title.get_text().split()[0] # 书名
author = detail.get_text().split('/', 3)[0].split()[0] # 作者
intepretor = "" # 译者
publish = detail.get_text().split('/', 3)[1] # 出版社
time = detail.get_text().split('/', 3)[2].split()[0].split('-')[0] # 出版年份,只输出年
price = get_rmb_price2(detail) # 获取价格
score = score.get_text() if True else "" # 如果没有评分就置空
person = get_person(person) # 获得评分人数
#在控制台测试打印
test_print(name, author, intepretor, publish, time, price, score, person)
#将书籍信息写入txt文件
try:
file.write('name: %s ' % name)
file.write('author: %s ' % author)
file.write('intepretor: %s ' % intepretor)
file.write('publish: %s ' % publish)
file.write('time: %s ' % time)
file.write('price: %s ' % price)
file.write('score: %s ' % score)
file.write('person: %s ' % person)
file.write('\n')
except (IndentationError, UnicodeEncodeError):
continue except (IndexError,TypeError):
continue except TypeError:
continue
file file.write('\n')
file.close() #关闭文件 #程序执行入口
if __name__ == '__main__':
#url = "https://book.douban.com/tag/程序"
book_url_list = provide_url() #存放豆瓣所有分类标签页URL的列表
for url in book_url_list:
get_url_content(url) #解析每一个URL的内容
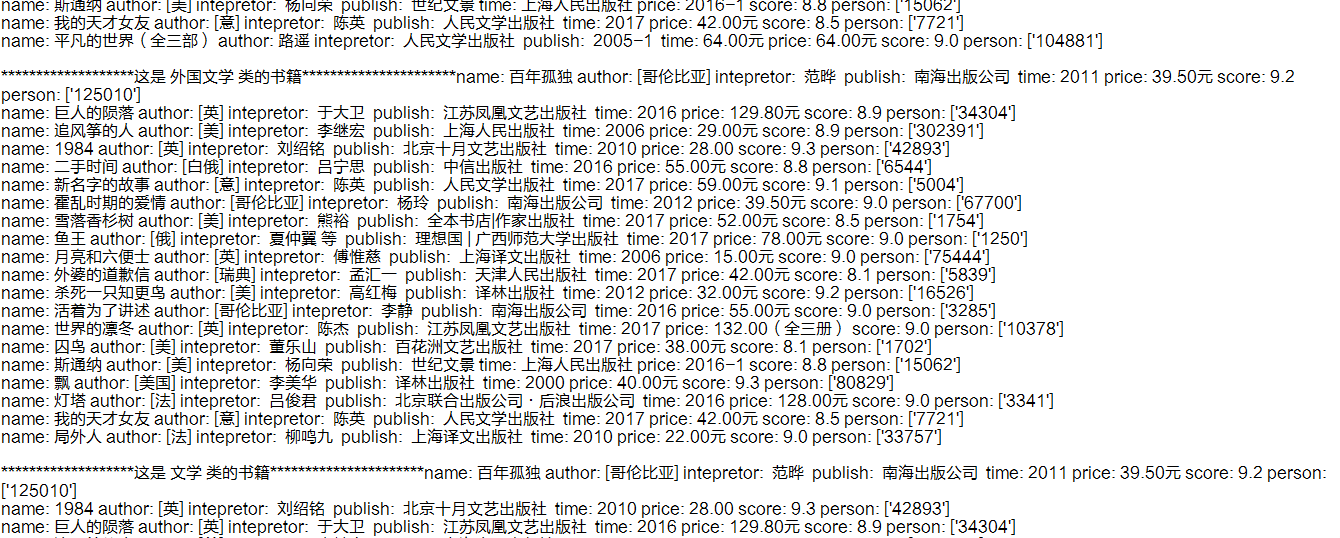
下面是效果图:
最新文章
- CSS强制性换行
- java中jdk和jre的区别
- 《Linux内核设计与实现》读书笔记(十四)- 块I/O层
- UML2
- poj 1050 To the Max (简单dp)
- 10个加速Table Views开发的Tips(转)
- 小学生之Java中的异常
- iBatis的一个问题
- 小白的Python之路 day4 生成器并行运算
- 敦泰FT6X06单层自容调屏
- (NO.00001)iOS游戏SpeedBoy Lite成形记(十六)
- 第六章——决策树(Decision Trees)
- Python linux多版本共存以及虚拟环境管理(转摘)
- usermod - linux修改用户帐户信息
- day051 django第二天 django初识\代码
- python: ImportError:DLL load failed 解决方法。
- (第1篇)什么是hadoop大数据?我又为什么要写这篇文章?
- Day10 Python网络编程 Socket编程
- NOI.AC NOIP2018 全国热身赛 第四场
- 函数和常用模块【day04】:内置函数分类总结(十一)