关于hive on spark会话的共享状态
spark sql中有一个类:
org.apache.spark.sql.internal.SharedState
它是用来做:
1、元数据地址管理(warehousePath)
2、查询结果缓存管理(cacheManager)
3、程序中的执行状态和metrics的监控(statusStore)
4、默认元数据库的目录管理(externalCatalog)
5、全局视图管理(主要是防止元数据库中存在重复)(globalTempViewManager)
1:首先介绍元数据地址管理(warehousePath)
这块儿主要是获取spark sql元数据库的路径地址,那么一般情况,我们都是默认把hive默认作为spark sql的元数据库,因为
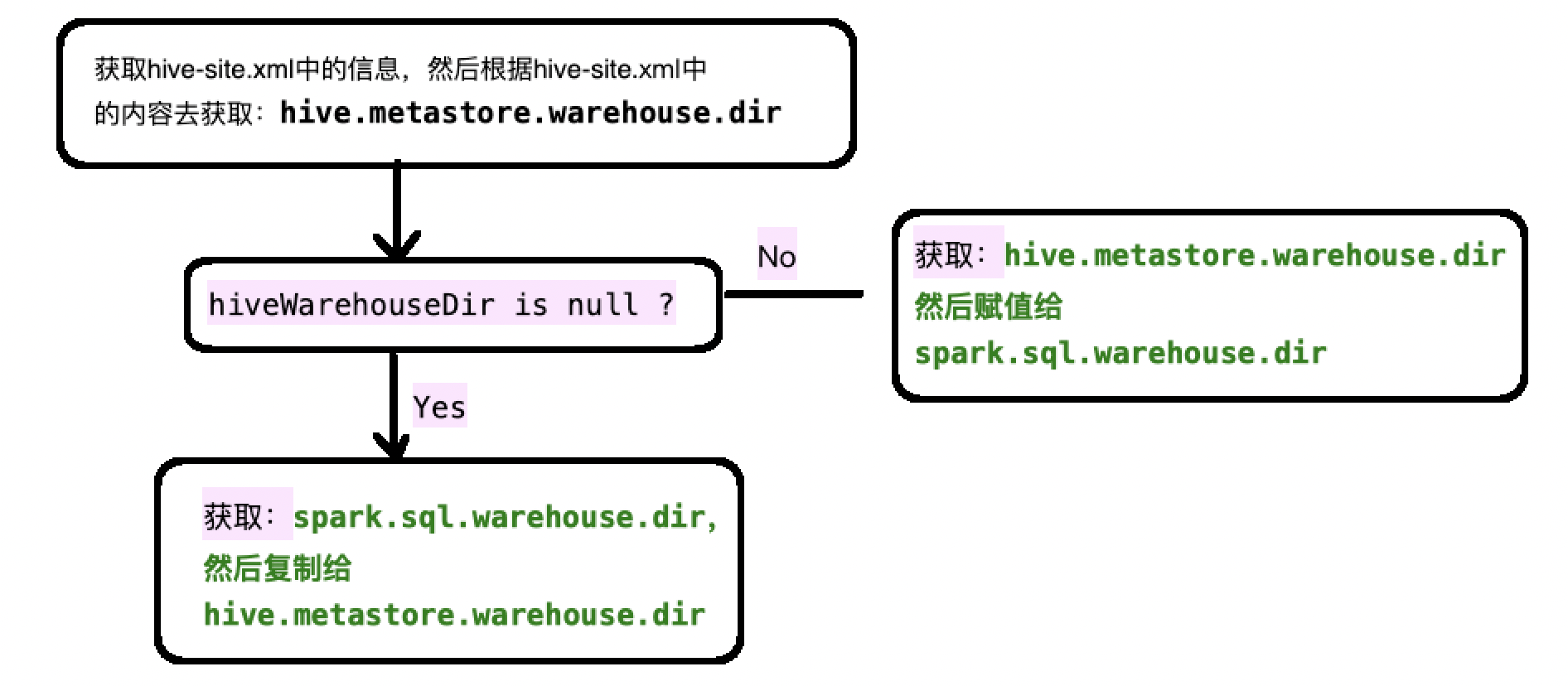
它首先去加载hive的配置文件"hive-site.xml" , 然后根据hive-site.xml中获取的信息来获取到hive元数据库的路径:
hive.metastore.warehouse.dir
那么有时候,我们不使用hive作为spark sql的元数据库,那么这个时候我们加载的hive元数据路径应该是null
val hiveWarehouseDir = sparkContext.hadoopConfiguration.get("hive.metastore.warehouse.dir")
如果hiveWarehouseDir是null,那么就去加载spark sql的自带的元数据管理地址(spark.sql.warehouse.dir),然后把这个地址的值赋予给hive.metastore.warehouse.dir
因此大概流程就是获取hiveWarehouseDir:
具体代码:
val warehousePath: String = {
val configFile = Utils.getContextOrSparkClassLoader.getResource("hive-site.xml")
if (configFile != null) {
logInfo(s"loading hive config file: $configFile")
sparkContext.hadoopConfiguration.addResource(configFile)
}
// hive.metastore.warehouse.dir only stay in hadoopConf
sparkContext.conf.remove("hive.metastore.warehouse.dir")
// Set the Hive metastore warehouse path to the one we use
val hiveWarehouseDir = sparkContext.hadoopConfiguration.get("hive.metastore.warehouse.dir")
if (hiveWarehouseDir != null && !sparkContext.conf.contains(WAREHOUSE_PATH.key)) {
// If hive.metastore.warehouse.dir is set and spark.sql.warehouse.dir is not set,
// we will respect the value of hive.metastore.warehouse.dir.
sparkContext.conf.set(WAREHOUSE_PATH.key, hiveWarehouseDir)
logInfo(s"${WAREHOUSE_PATH.key} is not set, but hive.metastore.warehouse.dir " +
s"is set. Setting ${WAREHOUSE_PATH.key} to the value of " +
s"hive.metastore.warehouse.dir ('$hiveWarehouseDir').")
hiveWarehouseDir
} else {
// If spark.sql.warehouse.dir is set, we will override hive.metastore.warehouse.dir using
// the value of spark.sql.warehouse.dir.
// When neither spark.sql.warehouse.dir nor hive.metastore.warehouse.dir is set,
// we will set hive.metastore.warehouse.dir to the default value of spark.sql.warehouse.dir.
val sparkWarehouseDir = sparkContext.conf.get(WAREHOUSE_PATH)
logInfo(s"Setting hive.metastore.warehouse.dir ('$hiveWarehouseDir') to the value of " +
s"${WAREHOUSE_PATH.key} ('$sparkWarehouseDir').")
sparkContext.hadoopConfiguration.set("hive.metastore.warehouse.dir", sparkWarehouseDir)
sparkWarehouseDir
}
}
logInfo(s"Warehouse path is '$warehousePath'.")
warehousePath
2:CacheManager
将查询结果缓存起来 ; 这样的好处就是,如果后面还需要本次查询出来的内容,就不需要在查询一遍数据源了(这块儿有时间单独写篇文章记录)
具体代码:
/**
* Class for caching query results reused in future executions.
*/
val cacheManager: CacheManager = new CacheManager
cacheManager
3:statusStore
代码:
/**
* A status store to query SQL status/metrics of this Spark application, based on SQL-specific
* [[org.apache.spark.scheduler.SparkListenerEvent]]s.
*/
val statusStore: SQLAppStatusStore = {
val kvStore = sparkContext.statusStore.store.asInstanceOf[ElementTrackingStore]
val listener = new SQLAppStatusListener(sparkContext.conf, kvStore, live = true)
sparkContext.listenerBus.addToStatusQueue(listener)
val statusStore = new SQLAppStatusStore(kvStore, Some(listener))
sparkContext.ui.foreach(new SQLTab(statusStore, _))
statusStore
}
statusStore
这段代码其实说白了就是将sql的状态和一些metrics指标写入到监听器中。
那么问题来了,监听器一定是实时的去监听的(读取的),然后spark sql还要不断的往监听器中写入,那么按照传统的list,map这种结构,在读取数据的时候还要在修改结构,会出现错误的;
因此spark sql采用了写时复制容器:
private[this] val listenersPlusTimers = new CopyOnWriteArrayList[(L, Option[Timer])]
将信息不断的写入同时,还不影响读取;
4、externalCatalog
获取spark 会话的内部目录(就是hiveWarehouseDir),如果不存在的话,就按照hiveWarehouseDir创建一个 , 当然,spark会通过回调函数的方式去监控当前目录中的事件:
externalCatalog.addListener(new ExternalCatalogEventListener {
override def onEvent(event: ExternalCatalogEvent): Unit = {
sparkContext.listenerBus.post(event)
}
})
此处代码:
/**
* A catalog that interacts with external systems.
*/
lazy val externalCatalog: ExternalCatalog = {
val externalCatalog = SharedState.reflect[ExternalCatalog, SparkConf, Configuration](
SharedState.externalCatalogClassName(sparkContext.conf),
sparkContext.conf,
sparkContext.hadoopConfiguration) val defaultDbDefinition = CatalogDatabase(
SessionCatalog.DEFAULT_DATABASE,
"default database",
CatalogUtils.stringToURI(warehousePath),
Map())
// Create default database if it doesn't exist
if (!externalCatalog.databaseExists(SessionCatalog.DEFAULT_DATABASE)) {
// There may be another Spark application creating default database at the same time, here we
// set `ignoreIfExists = true` to avoid `DatabaseAlreadyExists` exception.
externalCatalog.createDatabase(defaultDbDefinition, ignoreIfExists = true)
} // Make sure we propagate external catalog events to the spark listener bus
externalCatalog.addListener(new ExternalCatalogEventListener {
override def onEvent(event: ExternalCatalogEvent): Unit = {
sparkContext.listenerBus.post(event)
}
}) externalCatalog
}
externalCatalog
5、
此处就是防止spark执行过程中的临时数据库出现在externalCatalog中,因为如果spark的GLOBAL_TEMP_DATABASE出现在externalCatalog中的话。那么随着程序的执行,下一个线程想要获取元数据库地址的时候,就没法在里面创建hiveWarehouseDir。因此,如果在externalCatalog中存在GLOBAL_TEMP_DATABASE,那么就抛异常
/**
* A manager for global temporary views.
*/
lazy val globalTempViewManager: GlobalTempViewManager = {
// System preserved database should not exists in metastore. However it's hard to guarantee it
// for every session, because case-sensitivity differs. Here we always lowercase it to make our
// life easier.
val globalTempDB = sparkContext.conf.get(GLOBAL_TEMP_DATABASE).toLowerCase(Locale.ROOT)
if (externalCatalog.databaseExists(globalTempDB)) {
throw new SparkException(
s"$globalTempDB is a system preserved database, please rename your existing database " +
"to resolve the name conflict, or set a different value for " +
s"${GLOBAL_TEMP_DATABASE.key}, and launch your Spark application again.")
}
new GlobalTempViewManager(globalTempDB)
}
globalTempViewManager
最新文章
- Objective-C中NSInvocation的使用
- 变通实现微服务的per request以提高IO效率(二)
- 计算LDA模型困惑度
- javascript event(事件对象)详解
- dataGrid转换dataTable
- drupal module 自定义
- IIS 7.5 配置10W高并发
- [分享]运维分享一一阿里云linux系统mysql密码修改脚本
- nssm在windows服务器上部署nodejs,coffee启动方式
- CentOS如何挂载硬盘
- LabVIEW的错误簇以及错误处理函数
- Maven3(笔记一)
- [Ext JS 4] 实战之Grid, Tree Gird编辑Cell
- MySQL用户管理语句001
- SOCKET网络编程细节问题(4)
- ArrayList原理解析
- 一款PHP环境整合工具—VertrigoServ介绍
- 源码编译vim
- aircrack-ng后台跑包, 成功后自动发送邮件通知
- Dom操作注意事项