pandas之数据处理操作
1、pandas对缺失数据的处理
我们的数据缺失通常有两种情况:
1、一种就是空,None等,在pandas是NaN(和np.nan一样)
解决方法:
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
2、另一种是我们让其为0,蓝色框中
解决方法:
step1、处理为0的数据:t[t==0]=np.nan 当然并不是每次为0的数据都需要处理 计算平均值等情况,nan是不参与计算的,但是0会
step2、然后在对nan进行操作
注意:fiillna(t.mean())填充只针对该nan的列的平均值进行填充
2、常用的统计方法
df["name"].unique()#获取不重复的列表数据
df["name"].mean()#取平均值
df["name"].max()#取最大值
df["name"].min()#取最小值
df["name"].argmin()#取最小值位置
df["name"].argman()#取最大值位置
df["name"].median()#取中位数
3、pandas 实现one hot编码方式
1、重新构造一个全为0的数组,行名为分类,长度为原数据长度
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
2、如果某一条数据中分类出现过,就让它由0变为1
方式1:
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)]=1

方式2:
for i in range(df.shape[0]):
zeros_df.loc[i][temp_list[i][0]] = 1
方式3:
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
4、数据合并Join和Merge
Join :默认情况下它是把行索引相同的数据合并在一起
print '使用默认的左连接\r\n',data.join(data1) #这里可以看出自动屏蔽了data中没有的index=e 那一行的数据
print '使用右连接\r\n',data.join(data1,how="right") #这里出自动屏蔽了data1中没有index=c,d的那行数据;等价于data1.join(data)
print '使用内连接\r\n',data.join(data1,how='inner')
print '使用全外连接\r\n',data.join(data1,how='outer') Merge:按照指定的列把数据按照一定方式合并在一起
print "单个列名做为内链接的连接键\r\n",merge(data,data1,on="name",suffixes=('_a','_b'))
print "多列名做为内链接的连接键\r\n",merge(data,data2,on=("name","id"))
print '不指定on则以两个DataFrame的列名交集做为连接键\r\n',merge(data,data2) #这里使用了id与name #使用右边的DataFrame的行索引做为连接键
##设置行索引名称
indexed_data1=data1.set_index("name")
print "使用右边的DataFrame的行索引做为连接键\r\n",merge(data,indexed_data1,left_on='name',right_index=True)
print '左外连接\r\n',merge(data,data1,on="name",how="left",suffixes=('_a','_b'))
print '左外连接1\r\n',merge(data1,data,on="name",how="left")
print '右外连接\r\n',merge(data,data1,on="name",how="right")
data3=DataFrame([{"mid":0,"mname":'lxh','cs':10},{"mid":101,"mname":'xiao','cs':40},{"mid":102,"mname":'hua2','cs':50}]) #当左右两个DataFrame的列名不同,当又想做为连接键时可以使用left_on与right_on来指定连接键
print "使用left_on与right_on来指定列名字不同的连接键\r\n",merge(data,data3,left_on=["name","id"],right_on=["mname","mid"])
example :
# coding=utf-8
import numpy as np
import pandas as pd def merge():
"""
merge使用
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("avwxyz"))
data1.iloc[2,0] = 100
print(data1)
print(data2) #inner连接 ,选取两边都存在的值,即取交集
print(pd.merge(data1,data2,on=["a","a"])) # 右连接,以data2为主表,如果data1表中没有data2对应的数据,则置为NaN
print(pd.merge(data1,data2,on=["a","a"],how="right")) data1 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(24).reshape(4,6),columns=list("qvwxyz"))
data1.iloc[2,0] = 100
print(data1)
print(data2) #如果两个表的列名称不对应,则使用left_on 与right_on一起使用,两个必须一起使用,反之,如果列名对应,则使用on
print(pd.merge(data1,data2,left_on=["a"],right_on=["q"])) #左表以"a"作为连接主键,右表以"q"连接 return None def join():
"""
join使用:行合并
如果存在相同的列名,则不能使用,只能使用merge
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4, 6), columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list("wxyz"))
data1.iloc[3,0]=100
print(data1)
print(data2)
print(data1.join(data2)) #直接将两个数据进行行添加
print(data1.join(data2,how="right")) #以右表为主连接表
print(data1.join(data2, how="left")) #以左表为主连接表
return None def concat():
"""
concat使用:全连接方式
:return:
"""
data1 = pd.DataFrame(np.arange(24).reshape(4, 6), columns=list("abcdef"))
data2 = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list("wxyz"))
data1.iloc[3, 0] = 100
print(data1)
print(data2)
frame = [data1,data2]
print(pd.concat(frame)) #全连接 print(pd.concat(frame,keys=["h","i"])) #指定行索引 return None if __name__ == '__main__':
#merge()
#join()
concat()
5、分组与聚合
grouped = df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组,元组里面是(索引(分组的值),分组之后的DataFrame)
获取分组之后的某一部分数据:
df.groupby(by=["Country","State/Province"])["Country"].count()
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
分组方式(t1,t2结果一样):
t1 = df[["Country"]].groupby(by=[df["Country"],df["State/Province"]]).count()
t2 = df.groupby(by=["Country","State/Province"])[["Country"]].count()
DataFrameGroupBy对象方法:

6、索引与复合索引
a)简单的索引操作:
获取index:df.index
指定index :df.index = ['x','y']
重新设置index : df.reindex(list("abcedf"))
指定某一列作为index :df.set_index("Country",drop=False)
返回index的唯一值:df.set_index("Country").index.unique() b)Series复合索引

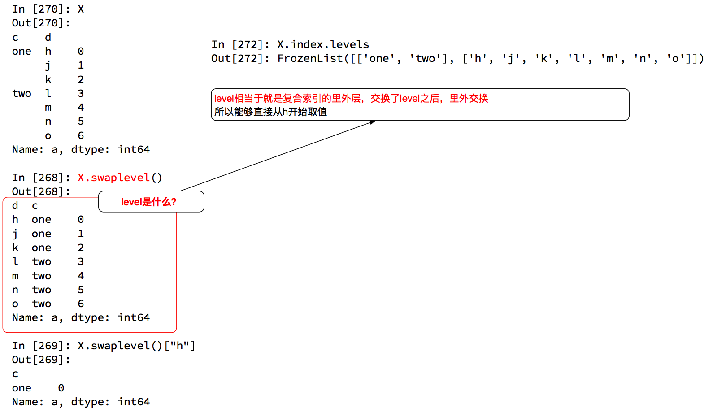
c)DataFrame复合索引

最新文章
- zepto区别于jquery获取select表单选中的值
- MongoDB 文档的删除操作
- bzoj1208
- 379. Design Phone Directory
- 关于在DataGrid.RowDetailsTemplate中的控件查找不到的问题
- 数论 - Funny scales(SPOJ - SCALE)
- 利用反射和ResultSetMetaData实现DBUtils的基本功能
- Python模块——bisect
- 使用eclipse JDT compile class,解决 无法确定 X 的类型参数;对于上限为 X,java.lang.Object 的类型变量 X,不存在唯一最大实例
- iOS上传应用过程中出现的错误"images contain alpha channels or transparencies"以及解决方案
- MVC4中下拉菜单和单选框的简单设计方法
- Pair project(刘昊岩11061156 黄明源11061186)
- js局部变量与全局变量
- Bitmap 与Drawable相互转换
- 九度oj 1482:玛雅人的密码
- #565. 「LibreOJ Round #10」mathematican 的二进制(期望 + 分治NTT)
- (网页)javascript该如何学习?怎么样才能学好?
- 1 byte 8 bit 1 sh 1 bit 2. 字符与编码在程序中的实现
- golang 的 buffered channel 及 unbuffered channel
- cookie 简单用法