关于pandas增加行时,索引名称的一些问题
2024-09-02 20:46:12
学习pandas两天了,关于这个增加行的问题一直困扰着我,测试了几个代码,终于搞通了一点(昨天是因为代码敲错了。。。)
直接上代码:
dates = pd.date_range('',periods=6)
df1 = pd.DataFrame(np.arange(24).reshape((6,4)),index = dates,columns=['A','B','C','D'])
创建了一个名为df1的DataFrame,其中数据为24为排列数,关键是index的取值,我这里用的pandas自带的日期序列函数生成的dates
生成的df1如图:
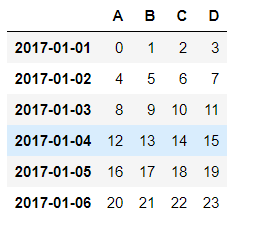
这里可以看到index的名称为date_time格式的
需要加入新的一行时,我采用了loc函数:
df1.loc[pd.to_datetime(''),['A','B','C','D','E']] = [1,2,3,4,5]
按照之前的index的格式添加,显然增加的新行和之前行的形式是相同的:
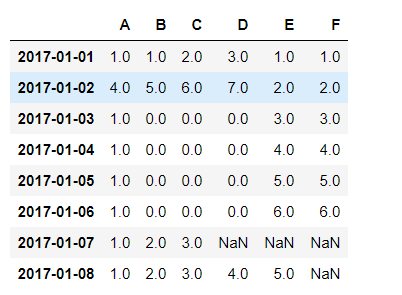
(这里图片多添加了一行,不牵扯)
但是如果,添加的index和之前的数据类型不同时,会报错么?
试一试:
df1.loc['',['D','E']]=[1,2]
这里我将一个字符串’20180108‘,添加到新行的index,本以为会报错,结果:
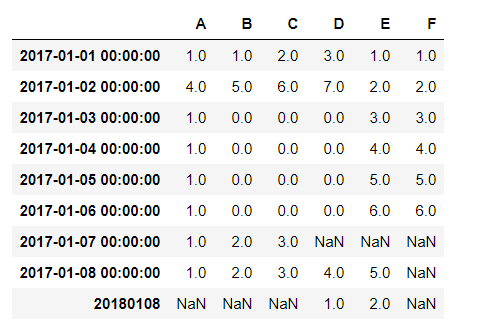
添加成功了,不过表格的格式也发生更改了,date_time原本隐藏的时间00:00:00显示出来。接着我添加相同名称的int32位变量试试:
df1.loc[20180108,['E','C']] = [1,3]
同样添加成功,神奇的一幕发生了:
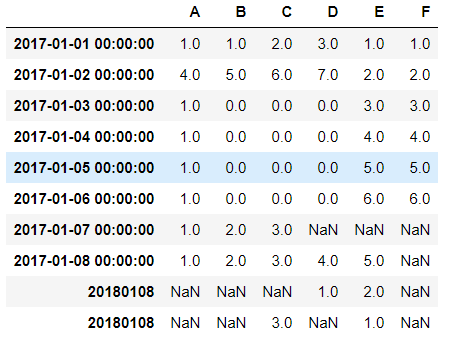
出现了两个完全相同的index:20180108
这是为什么呢?原来是因为,上面那行的20180108的数据类型是str,而下面那行的20180108数据类型是int32,系统判断是两个完全不同的数据,所以会出现两个完全相同的index在表格中
接着,再添加一个date_time格式的’20180108‘吧:
df1.loc[pd.to_datetime(''),['A','B']] = [3,4]
结果不出所料:
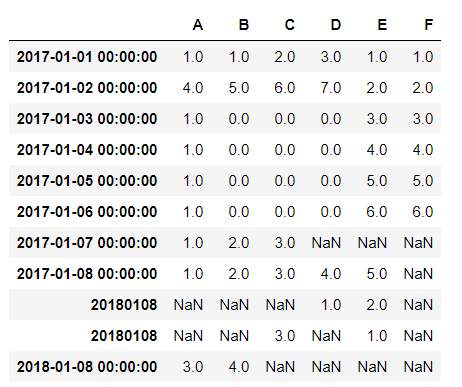
成功添加。
至此,pandas的添加行操作原理基本搞明白了,keep learning。
最新文章
- python cmd下运行中文乱码 策略
- DHTMLX-Grid
- Centos5.8 安装 ImageMagick 6.8.9-3
- Codeforces Round #158 (Div. 2) C. Balls and Boxes 模拟
- Cassandra + Eclipse + Hadoop
- Altium Designer6打印PCB转印纸设置方法
- CentOS 安装 Mogodb(在线 && 离线)
- a标签包含块级元素问题
- VS中,Ctrl+Shift+F无法在文件中查找
- 用API给用户添加职责
- 《通过C#学Proto.Actor模型》之Behaviors
- JSON库的使用研究(二)
- ftp服务器搭建及简单操作
- Conscription [POJ3723] [最小生成树]
- TCP/IP 笔记 - 传输控制协议
- Xshell中vim退出内容仍停留在屏幕的问题
- MySQL清理慢查询日志slow_log的方法
- LINQ 查询
- 【Python】TCP Socket的粘包和分包的处理
- 【贪心】【堆】Gym - 101775B - Scapegoat
热门文章
- 源代码管理工具(1)——SVN(1)——SVN 的使用新手指南,具体到步骤详细介绍----TortoiseSVN
- svn检出两种方式的区别
- C++11常用特性介绍——for循环新用法
- 【Python矩阵及其基础操作】【numpy matrix】
- java编译问题之Description Resource Path Location Type Java compiler level does not match the version of
- windows下mysql 8.0.12安装步骤及基本使用教程
- Mysql基本用法-存储引擎-04
- PAT T1017 The Best Peak Shape
- Codeforces #617 (Div. 3)B. Food Buying
- Tarjan算法与割点割边