java面试记录三:hashmap、hashtable、concurrentHashmap、ArrayList、linkedList、linkedHashmap、Object类的12个成员方法、消息队列MQ的种类
口述题
1、HashMap的原理?(数组+单向链表、put、get、size方法)
非线程安全:(1)hash冲突:多线程某一时刻同时操作hashmap并执行put操作时,可能会产两个key的hash值相同,两线程在插入时,肯定会有一个丢失值(put方法不是同步的,put内部调用的addEntry方法也是不同步的)
(2)hashmap的扩容方法resize(不是同步的):当hashmap大小不够,两个线程同时进行扩容时,最后一个线程生成的新数组赋予了resize方法中的table,其他线程的均丢失。
HashMap采用链地址法,即数组+单向链表。主干是数组,长度是2的次幂,链表是为了解决哈希冲突(对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了)而存在的。
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算 +构造方法}
如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;
如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),先根据key的hashCode重新计算hash值,再根据hash值得到元素在数组中的位置,若数组该位置上已存放其他元素,则该位置上的元素以链表形式存放,新加入的元素放在链头Entry中存放的next指向原先的元素,因为最新的Entry会插入链表头部,即需要简单改变引用链即可,
而对于查找操作来讲,此时就需要通过计算key的hashCode,找到数组中对应位置的元素,然后通过key对象的equals方法逐一比对查找,遍历链表。
所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
注:hashMap数组扩容,当数组中元素个数超过数组大小(默认16)*负载因子(默认0.75)时,数组大小要扩大一倍,在重新计算元素在数组中的位置(非常消耗性能,预设元素个数能够提高HashMap的性能)
高效遍历HashMap的方式:
Map m = new HashMap();
Iterator it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry en = (Map.Entry) it.next();
Object key = en.getKey();
Object value = en.getValue();
}
1.1、hashTable
线程安全:使用synchronized来锁住整张hash表来实现线程安全
通过“拉链法”实现的哈希表,成员变量table是一个Entry[ ] 数组类型,而 Entry(在 HashMap 中有讲解过)实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的
hashTable与hashMap的结构是类似的,只不过它俩继承、实现的类不同。
hashMap与hashTable的比较:线程安全性、同步、速度
(1)hashMap的key和value都允许为null(遇到key为空的时候调用putForNullKey方法进行处理,存储在table数组的第一个节点上),而hashTable的key和value都不允许为null(遇到null直接返回nullPointerException)
(2)hashTable是线程安全的,方法是同步的,几乎所有的public方法都是synchronized的。hashMap是非线程安全的。涉及到多线程同步就用hashTable,反之用hashMap
(3)hashTable基于Dictionary类,hashmap继承了AbstractMap(它们都实现了Map接口)
(4)hashtable在单线程环境下比hashmap慢
(5)hashMap扩容是当前容量翻倍,而hashTable是当前容量翻倍+1
(6)计算hash的方法不同:hashTable是直接使用key的hashCode对table数组的长度直接进行取模;hashMap对key的hashCode进行了二次hash,已获得更好的散列值,然后对table数组长度取模;
2、Concurrenthashmap原理和技术,size方法的实现?
线程安全
Concurrenthashmap是hashmap的实现
Concurrenthashmap结构:主干是一个segment数组,segment(继承ReentrantLock)里面是一个hashEntry数组,segment跟hashmap差不多
Concurrenthashmap的put方法:(1)定位segment并确保segment已初始化,(2)调用segment的put方法
concurrentHashmap的get方法:
对于一个key,需要经过三次(为什么要hash三次下文会详细讲解)hash操作,才能最终定位这个元素的位置,这三次hash分别为:
- 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key);
- 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment;
- 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在哪个HashEntry
concurrentHashmap的size方法:size方法需要遍历所有的segment才能算出整个map的大小,而在遍历的过程中,之前遍历的segment可能会改变,所以最后size出来的可能并不是map真正的大小
3、Arraylist和linkedlist原理结构,以及linkedhashmap底层结构?
数组在内存中都是以一段连续的地址空间来存储元素的,由于它直接操作内存,所以性能要比集合类更好一些
ArrayList基于数组实现,所有方法都没有进行同步,是线程不安全的,查找修改快(根据索引直接查询或修改,不涉及数组复制)而插入删除慢(插入、删除都涉及到数组元素的移位、以及复制)。源码中有成员变量final int default_CAPACITY初始容量,一个空对象数组Object[] enpty_elementdata = {},一个对象数组Object[] elementdata,一个集合元素个数size
增加add():单纯的添加元素,直接插入数组末尾,快速
增加add(index,value):指定位置的添加,需要将index后的元素后移并复制数组,操作慢
删除remove(index):需要将删除位置后的元素前移,也会涉及到数组复制,操作慢
修改set(index,value):直接对指定位置的元素进行修改,不涉及元素移动和数组复制,操作快
查询get(index):直接返回指定下标的数组元素,操作快
arraylist的扩容,就是增加原来数组长度的一半(实际上是新建一个容量更大的数组,将原先数组的元素全部复制到新的数组上)
linkedlist底层是基于双向链表实现的,不管是增删改查方法还是队列和栈的实现,都是可以通过操作结点实现的,所有方法没有进行同步,是线程不安全的,插入删除快(时间复杂度O(1))而查找修改慢(要遍历链表进行元素定位,时间复杂度O(n/2))
增加add(e):在链表尾部添加
增加add(index,e):index等于集合元素个数时,在链表尾部添加;否则在链表中部插入
删除remove(index):将要删除的元素的上一个结点的后继结点引用指向要删除的结点的下一个结点的前继结点引用
删除remove(object):同上,删除元素后集合占用的内存自动缩小
修改set(index,element):获取指定下标结点的引用,获取指定下标结点的值,将结点元素设置为新的值
查找get(index):先检查下标是否合法,再返回指定下标的结点的值
HashMap和双向链表合二为一即是LinkedHashMap,它是一个将所有Entry节点链入一个双向链表的HashMap,LinkedHashMap是HashMap的子类
LinkedHashMap的Entry结构,在hashmap的基础上,增加了before和after: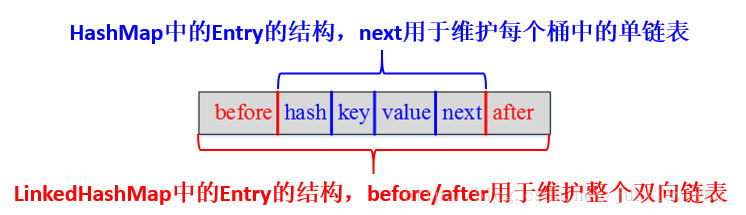
4、Arraylist的elementdata属性为什么用了transient修饰后,依然可以序列化,这样的好处?
transient是类型修饰符,只能用来修饰字段。在对象序列化的过程中,标记为transient的变量不会被序列化
好处:Arraylist的两个方法writeObject和readObject,
ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。
为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
5、Object类有哪些方法,分别讲解一下
有12个成员方法:
构造函数Object()
hashCode()和equals()函数用来判断对象是否相同
wait(),wait(long),wait(long,int),notify(),notifyAll() ,线程相关
toString()和getClass()
clone() :另存当前对象
finalize()用于在垃圾回收
6、Redis有哪些数据结构(新版本redis不止五种)?每种结构的使用场景,redis分布式锁的实现
7、Redis参数配置,哪些可以优化?
8、Redis主从、哨兵、集群的原理?如何扩容
9、线上redis遇到的问题,如何排查(主从模式下主宕机后重启遇到的问题以及解决思路)
10、Redis如何保证缓存的是热点数据(6中内存淘汰机制)
11、分布式session一致性如何保证
12、怎么做前后端分离?好处是?
13、Nginx负载均衡算法?Nginx反向代理?
14、http1.1
为了缓解服务器压力,每次Request/Response后连接(TCP连接)继续保持,以及对同一个TCP连接,多次复用Request/Response的方法(也称为Pipeline)也提了出来。这就是HTTP/1.1协议中长连接的主要内容
15、Jvm命令:jstat、jmap,生产上如何处理OOM?
16、排查CPU百分百的思路?
17、Dubbo如何分组?Zookeeper也可以做分布式锁?
18、用过什么MQ?activeMQ、rocketMQ、rabbitMQ
一、消息队列MQ,应用场景:
(1)异步处理:场景说明:用户注册后,需要发注册邮件和注册短信
(2)应用解耦:场景说明:用户下单后,订单系统需要通知库存系统
(3)流量削锋:应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列
(4)日志处理:指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题
(5)消息通讯:消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等
二、常用消息队列
(1)ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
ActiveMQ特性如下:
⒈ 多种语言和协议编写客户端。语言: Java,C,C++,C#,Ruby,Perl,Python,PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
⒉ 完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
⒊ 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性
⒋ 通过了常见J2EE服务器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
⒌ 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
⒍ 支持通过JDBC和journal提供高速的消息持久化
⒎ 从设计上保证了高性能的集群,客户端-服务器,点对点
⒏ 支持Ajax
⒐ 支持与Axis的整合
⒑ 可以很容易得调用内嵌JMS provider,进行测试
(2)RabbitMQ
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是AMQP(高级消息队列协议)的标准实现。支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
几个重要概念:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程,如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
19、ES是什么?ELK分布式日志框架
20、Mysql操作、sql优化、两种引擎的区别
21、微服务拆分,以及不同服务区间使用同一个库是否合理?(其实就是伪微服务,违背了微服务理念的数据独立性)
22、Linux的一些特性和操作命令,开发中常用的命令
最新文章
- (Interface)接口特点
- CURL常用命令
- nodejs获取客户端IP Address
- java.lang.NullPointerException
- 在表单(input)中id和name的区别
- CentOS 搭建LNMP服务器和LAMP服务器
- JSON对象与JSON数组
- SGU 186.The Chain
- Android 即时语音聊天工具 开发
- JavaScript设计模式之构造函数模式
- Android 开源库
- call_grant_exec.sql
- 团队作业1--团队展示&选题(SNS)
- Latex 去掉行号
- SpringMVC中url-pattern /和/*的区别
- 一种公认提供toString的方法_JAVA核心技术卷轴Ⅰ
- Shell编程(四)Shell变量
- php上传多张图片
- jquery轮播图片(无插件简单版)
- [Web 前端] mockjs让前端开发独立于后端