Day4-Python3基础-装饰器、迭代器
今日内容:
1、高阶函数
2、嵌套函数
3、装饰器
4、生成器
5、迭代器
1、高阶函数
定义:
a:把一个函数名当作实参传给函数
a:返回值包含函数名(不修改函数的调用方式)
import time
def test1():
time.sleep(3)
print('in the test1') def func(fun):
start_time=time.time()
fun()
stop_time=time.time()
print("fun use time:%s" %(stop_time-start_time)) func(test1)
2、嵌套函数
def foo():
print('in the foo')
def bar():
print('in the bar') bar()
foo()
函数调用
import time
def test1():
time.sleep(3)
print('in the test1') def func():
test1() func()
3、装饰器
定义:本质是函数,(装饰其他函数)就是为其它函数添加附加功能。
原则:1、不能修改被装饰器函数的源代码
2、不能修改被装饰函数的调用方式
函数即“变量”
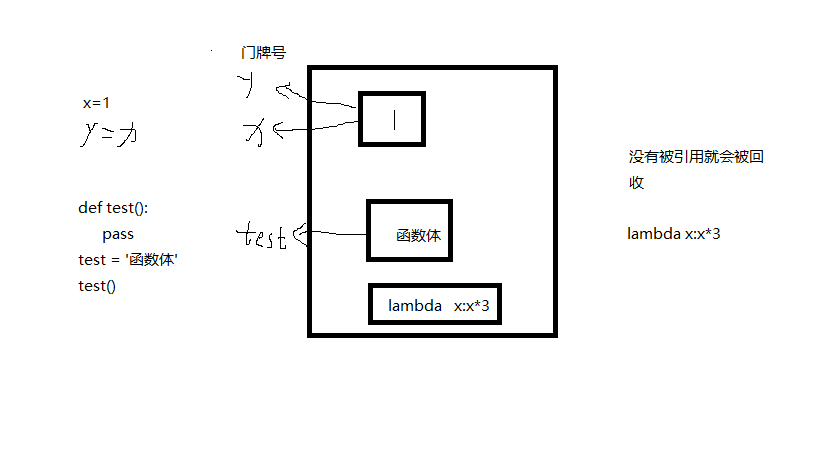
高阶函数 + 嵌套函数 ----》装饰器
3、生成器
列表生成式
>>> a = [i+1 for i in range(10)]
>>> a
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
>>> next(g)
36
>>> next(g)
49
>>> next(g)
64
>>> next(g)
81
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
上面的函数可以输出斐波那契数列的前N个数:
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
done
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n,a,b = 0,0,1 while n < max:
#print(b)
yield b
a,b = b,a+b n += 1 return 'done'
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,
再次执行时从上次返回的yield语句处继续执行。
data = fib(10)
print(data) print(data.__next__())
print(data.__next__())
print("干点别的事")
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__()) #输出
<generator object fib at 0x101be02b0>
1
1
干点别的事
2
3
5
8
13
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6):
... print(n)
...
1
1
2
3
5
8
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
还可通过yield实现在单线程的情况下实现并发运算的效果
'''
吃包子
最简单的协程
单线程下的并行效果 '''
import time
def consumer(name):
print("%s 准备来吃包子啦!"%name)
while True:
baozi=yield
print("[%s]包子来了,被[%s]吃了"%(baozi,name)) # c=consumer('鲁班')
# c.__next__()
# b='酸菜陷'
# c.send(b)
def product(name):
c1=consumer('A')
c2=consumer('B')
c1.__next__()
c2.__next__()
print("\033[31;1m开始做包子了!\033[0m")
for i in range(10):
time.sleep(1)
print("\033[44;1m做了一个包子,分成两半!\033[0m")
c1.send(i)
c2.send(i) product("厨神--程咬金")
4、迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
最新文章
- PCWIFI--无线网络共享软件
- WPF 基础到企业应用系列索引
- com学习(四)——用 ATL 写第一个组件
- rails 学习笔记
- Java NIO类库Selector机制解析(下)
- log4net 配置
- HierarchicalDataBoundControl 错误
- JS 对象、HTML事件处理、JS 类型转换、Date
- poj 3692 Kindergarten (最大独立集之逆匹配)
- OpenCV学习(3)--Mat矩阵的操作
- libmysql.dll 找不到
- 转载 twisted(1)--何为异步
- 201521123050 《Java程序设计》第10周学习总结
- 自己总结的C#编码规范--4.注释篇
- 将代码从 spark 1.x 移植到 spark 2.x
- Spark学习笔记——读写MySQL
- PPT文件分析摘记
- leetcode-algorithms-15 3Sum
- pthread mutex
- Nginx Rewrite正则表达式案例
热门文章
- JMeter JMS测试计划
- java xml的读取与写入(dom)
- 利用Python实现高度定制专属RSS
- [工具] Git版本管理(一)(基本操作)
- __FILE__,__LINE__,__DATE__,__TIME__,__FUNCTION__的使用
- The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone错误的解决办法【已解决】
- 编译GLib C程序
- [Oracle]Oracle的闪回归档
- 洛谷训练新手村之“BOSS战-入门综合练习1”题解
- 利用自编码(Autoencoder)来提取输入数据的特征