[REDIS 读书笔记]第一部分 数据结构与对象 跳跃表
下面是跳跃表的基本原理,REDIS的实现大致相同
跳跃表的一个特点是,插入NODE是通过随机的方式来决定level的,比较奇特
下面是skipList的一个介绍,转载来的,源地址:http://kenby.iteye.com/blog/1187303,为防止源地址丢失,故拷贝一份放在这里,望作者原谅。
———————————————转载开始—————————————————
为什么选择跳表
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。
想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树
出来吗? 很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,
还要参考网上的代码,相当麻烦。
用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,
它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,
就能轻松实现一个 SkipList。
有序表的搜索
考虑一个有序表:

从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数
为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉
搜索树,我们把一些节点提取出来,作为索引。得到如下结构:
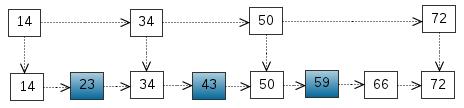
这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:
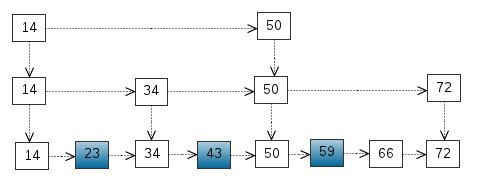
这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。
跳表
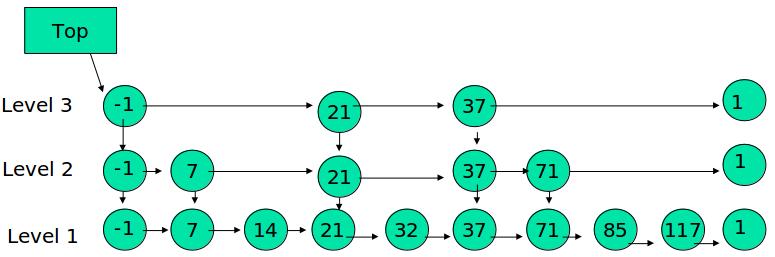
下面的结构是就是跳表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的搜索
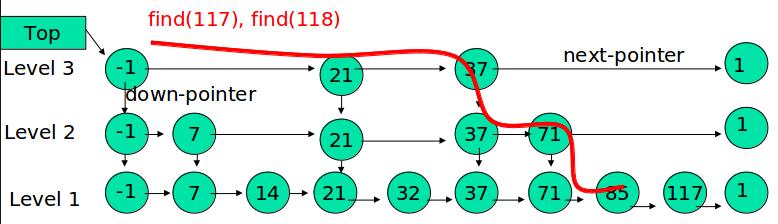
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
具体的搜索算法如下:
- /* 如果存在 x, 返回 x 所在的节点,
- * 否则返回 x 的后继节点 */
- find(x)
- {
- p = top;
- while (1) {
- while (p->next->key < x)
- p = p->next;
- if (p->down == NULL)
- return p->next;
- p = p->down;
- }
- }
跳表的插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)
然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
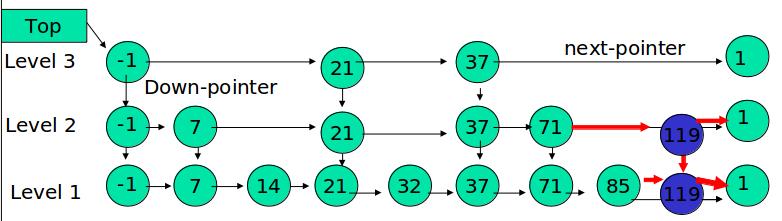
如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4
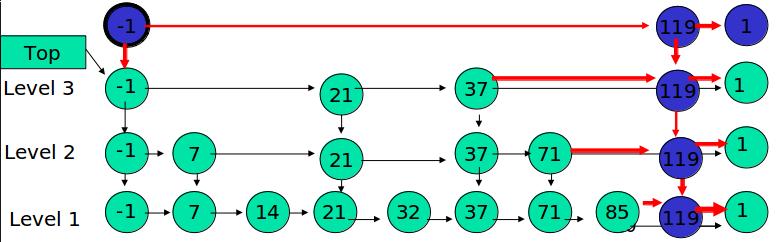
丢硬币决定 K
插入元素的时候,元素所占有的层数完全是随机的,通过一下随机算法产生:
- int random_level()
- {
- K = 1;
- while (random(0,1))
- K++;
- return K;
- }
相当与做一次丢硬币的实验,如果遇到正面,继续丢,遇到反面,则停止,
用实验中丢硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,
K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
跳表的高度。
n 个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数 K,
跳表的高度等于这 n 次实验中产生的最大 K,待续。。。
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的
期望值是 2n。
跳表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
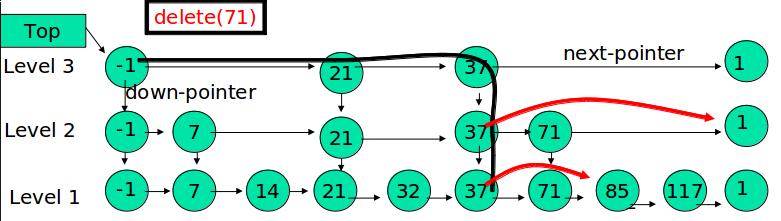
————————————————————转载结束—————————————————————
随机的层高level-相关资料
http://blog.csdn.net/kisimple/article/details/38706729
http://blog.csdn.net/unix21/article/details/10197115
最新文章
- JavaScript中使用typeof运算符需要注意的几个坑
- Unity3D 面试题汇总
- php获取远程文件大小
- php 笔试面试 总结
- 推荐一个国外的vps
- 算法 python实现(二) 冒泡排序
- NOIP2010-普及组复赛模拟试题-第二题-数字积木
- html的基本标记符号
- REdis命令处理流程处理分析
- Android--多线程之进程与线程
- Java-Method类常用方法详解
- Educational Codeforces Round 55 (Rated for Div. 2) B. Vova and Trophies
- Xamarin.Android 使用 Encoding.GetEncoding("GB2312") 报错解决方案
- [编程] TCP协议概述
- Java string.valueof的用法以及与parseint的区别
- Android开发(七)——判断网络状态
- Python Scrapy 自动爬虫注意细节(2)
- vue打包(npm run build)时错误记录
- 虚拟机拷贝之后,发现系统内的开机自启动的nginx,不能自启动了
- 2017 ACM/ICPC Asia Regional Shenyang Online card card card
热门文章
- 使用docker增加部署速度的一次实践
- vue的param和query两种传参方式及URL的显示
- Greedy Gift Givers 贪婪的送礼者 USACO 模拟
- PTA - 堆栈模拟队列
- excel 转换成pdf 总结
- 曹工说Spring Boot源码(11)-- context:component-scan,你真的会用吗(这次来说说它的奇技淫巧)
- crawler碎碎念5 豆瓣爬取操作之登录练习
- Creating Custom Helper Methods 创建自定义辅助器方法----辅助器方法 ------ 精通ASP.NET MVC 5
- c#数字图像处理(八)图像平移
- python之set集合操作