Dependency Parsing
句子的依赖结构表现在哪些单词依赖哪些单词。单词之间的这种关系及可以表示为优先级之间的关系等。
Dependency Parsing
通常情况下,对于一个输入句子:\(S=w_{0} w_{1} \dots w_{n}\)。 我们用 \(w_{0}\) 来表示 ROOT,我们将这个句子转换成一个图 G。
依赖性解析通常分为训练与预测两步:
- 使用已经解析的注释库训练模型 M
- 得到模型 M之后,对于句子 S,通过模型解析出图 G。
基于转换的依赖性解析
该方法就是通过训练数据训练一个状态机,通过状态机转换对源语句进行解析。
基于贪心确定性过渡的解析
这个转换的系统本质也是一个状态机,但是不同的是,对于一个初始状态,会有多个终止状态。
对于每一个源语句 \(S=w_{0} w_{1} \dots w_{n}\) 每个状态可以表示成三部分 \(c=(\sigma, \beta, A)\) 。
- 第一部分 \(\sigma\) 用来存储来自 S 的 \(w_i\) ,使用栈存储
- \(\beta\) 表示一个来自 S 的缓冲
- A 表示 \(\left(w_{i}, r, w_{j}\right)\) 的集合,其中 \(w_{i}, w_{j}\) 来自 S,然后 r 表示 \(w_{i}, w_{j}\)之间的关系。
状态初始化:
- 初始状态是 \(C_0\) 可以表示为 \(\left[w_{0}\right]_{\sigma},\left[w_{1}, \ldots, w_{n}\right]_{\beta}, \varnothing\)。可以看到只有 \(w_0\) 在 \(\sigma\) 中,其它的 \(w_i\) 都在 \(\beta\) 中。还没有任何关系。
- 终止状态就是 \(\sigma,[ ]_{\beta}, A\) 形式。
状态转换的方法:
- 从缓存中移除一个单词兵放在 \(\sigma\) 栈顶,
- \(\mathrm{L} \mathrm{EFT}-\mathrm{A} \mathrm{RC}_{r}(l)\):将 \(\left(w_{j}, r, w_{i}\right)\) 添加至集合 A,\(w_{i}\) 是栈 \(\sigma\) 的第二个数据,\(w_{j}\) 是栈顶的单词,将 \(w_{i}\) 从栈中移除,这个 ARC 关系用 \(l\) 表示。
- \(\mathrm{RIGHT}-\mathrm{ARC}_{r}(l)\):将 \(\left(w_{i}, r, w_{j}\right)\) 添加到集合 A, \(w_{i}\)是栈的第二个单词,
神经依赖性解析
神经以来解析的效果要好于传统的方法。主要区别是神经依赖解析的特征表示。
我们描述的模型使用 arc 系统作为变换,我们的目的就是将原序列变成一个目的序列。就是完成解析树。这个过程可以看作是一个 encode 的过程。
Feature Selection:
第一步就是要进行特征的选择,对于神经网络的输入,我们需要定义一些特征,一般有以下这些:
\(S_{w o r d}\):S 中一些单词的向量表示
\(S_{\text {tag}}\):S 中一些单词的 Part-of-Speech (POS) 标签,POS 标签包含一个小的离散的集合:\(\mathcal{P}=\{N N, N N P, N N S, D T, J J, \dots\}\)
\(S_{l a b el}\):S 中一些单词的 arc-labels ,这个标签包含一个小的离散集合,描述依赖关系:\(\mathcal{L}=\{\) $amod, tmod $, \(n s u b j, c s u b j, d o b j\), \(\ldots\}\)
在神经网络中,我们还是首先会对这个输入处理,将这些编码从 one-hot 编码变成稠密的向量编码
对于单词的表示我们使用 \(e_{i}^{w} \in \mathbb{R}^{d}\)。使用的转换矩阵就是 \(E^{w} \in \mathbb{R}^{d \times N_{w}}\)。其中 \(N_w\) 表示字典的大小。\(e_{i}^{t}, e_{j}^{l} \in \mathbb{R}^{d}\) 分别表示第 \(i\) 个POS标签与第 \(j\) 个ARC 标签。对应的矩阵就是 \(E^{t} \in \mathbb{R}^{d \times N_{t}}\) and \(E^{l} \in \mathbb{R}^{d \times N_{l}}\)。其中 \(N_t\) 和 \(N_L\) 分别表示所有的 POS标签 与 ARC标签的个数。我们用 \(S^{w}, S^{t}, S^{l}\) 来表示 word, POS,ARC 的信息。
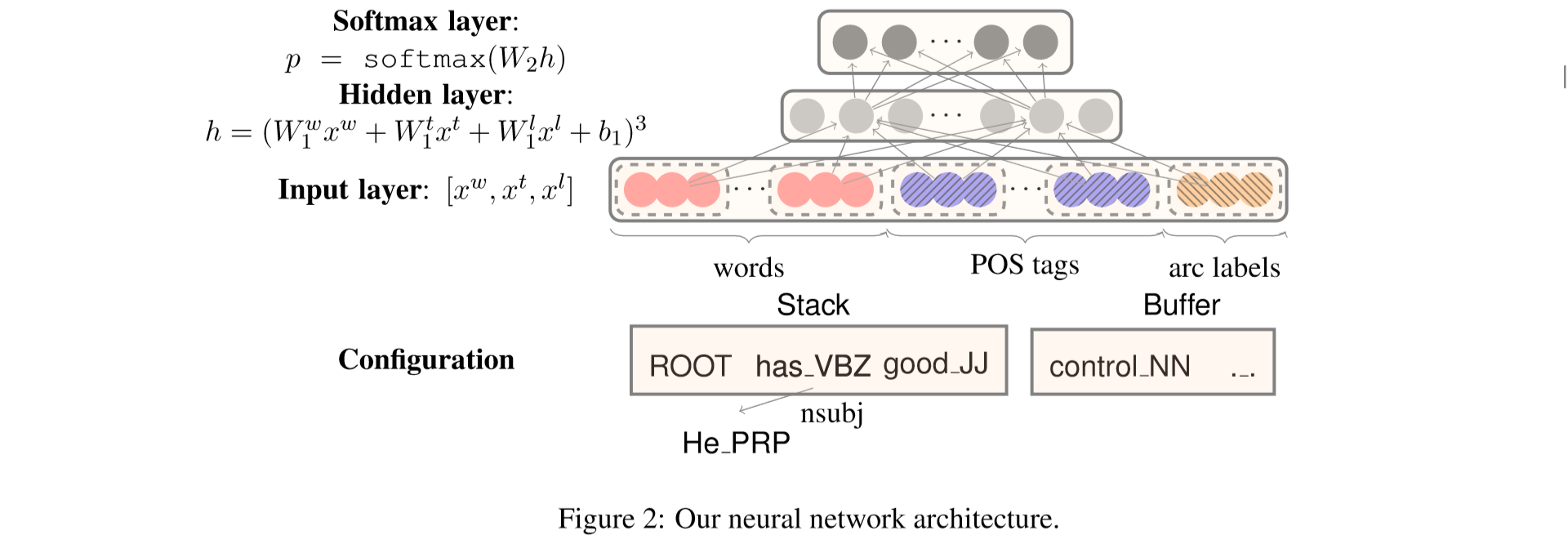
例如对于上面的这个图:
\(S_{tag}= \left\{l c_{1}\left(s_{2}\right) . t, s_{2} .t, r c_{1}\left(s_{2}\right) . t, s_{1} .t\right\}\)。然后我们将这些信息变成输入层的向量,比如对于单词来说,\(x^{w}=\left[e_{w_{1}}^{w} ; e_{w_{2}}^{w} ; \ldots e_{w_{n} w}^{w}\right]\)。其中 \(S_{word}=\left\{w_{1}, \ldots, w_{n_w}\right\}\),表示输入层的信息。同样的方式,我们可以获取到 \(x^t\) 与 \(x^l\)。然后我们经过一个隐含层,这个比较好理解:
\[
h=\left(W_{1}^{w} x^{w}+W_{1}^{t} x^{t}+W_{1}^{l} x^{l}+b_{1}\right)^{3}
\]
然后再经过一个 \(softmax\) 的输出层 \(p=\operatorname{softmax}\left(W_{2} h\right)\), 其中 \(W_2\) 是一个输出的矩阵,\(W_{2} \in \mathbb{R}|\mathcal{T}| \times d_{h}\)。
POS and label embeddings
就像单词的词典一样,我们对 POS 与 ARC 也有一个集合,其中 \(\mathcal{P}=\{\mathrm{NN}, \mathrm{NNP} ,\mathrm{NNS}, \mathrm{DT}, J J, \ldots \}\) 表示单词的一些性质, 例如 \(NN\) 表示单数名词。对于 \(\mathcal{L}=\{\)$ amod, tmod, nsubj, csubj, dobj$, \(\ldots\}\)表示单词间的关系。
最新文章
- CSS VS JS动画,哪个更快[译]
- PIC32MZ tutorial -- OC Interrupt
- 在Android中自定义捕获Application全局异常,可以替换掉系统的强制退出对话框(很有参考价值与实用价值)
- 从Mono 4.0观C# 6.0部分新特性
- Xshell中文乱码问题
- So easy Webservice 1.Socket建设web服务
- Unity3d NGUI的使用(九)(UIScrollView制作滑动列表)
- 使用POI导入Excel异常Cannot get a text value from a numeric cell 解决
- SQL做日历
- bzoj 1927 [Sdoi2010]星际竞速(最小费用最大流)
- 《Ruby语言入门教程v1.0》学习笔记-03
- VMware下设置CentOS虚拟机与主机同一网段
- Java使用javax.mail.jar发送邮件并同意发送附件
- System.Runtime.Serialization.SerializationException”类型的未经处理的异常在 System.Runtime.Serialization.dll 中发生
- Razor语法问题(foreach里面嵌套if)
- 如何让低版本IE浏览器支持HTML5标签并为其设置样式
- C语言常用的编程规范
- 20165306 Exp2 后门原理与实践
- Source Insight 4.0安装使用教程
- js 返回小数点后几位