hibernate(一) 第一个hibernate工程
序言
其实hibernate已经学过一遍,不过因为太糊弄,急于求成,导致现在需要重新来学习,通过亲自去敲每一行代码,来去理解每一个知识点。
---WH
一、什么是Hibernate?
轻量级JavaEE应用的持久层框架,是一个完全的ORM框架。(说完这句话,肯定有很多人懵圈了,下面我来一个个解释)
持久化:将我们想要保存的数据保存到硬盘上,也就是我们电脑的磁盘上,为什么叫持久化呢,就是数据能够保存的很久,所以叫持久化,现在对持久化的实现过程大多通过各种关系型数据库完成,所以我们常说的,将数据保存到数据库中,其实是数据库帮我们帮数据保存到硬盘中了。
持久层:既然知道了什么是持久化,那么持久化层也就应该有点思路了,这里吧数据库看成是内存的一部分,我们就当做将数据保存到数据库中,就保存到了硬盘中一样,所以在操作数据库的或者跟数据库打交道的那一层就是就持久层,比如我们之前知道了三层架构,不就有专门跟数据库打交道的一层叫做持久化层吗
ORM:Object Relational Mapping,对象关系映射,这个是一个思想,模型,或者说是规范。关系数据库中的记录映射成为程序语言中的对象实例,然后通过操作对象,来达到操作数据库的这样一种思想。如果没有ORM思想,我们之前就是直接操作数据库中的记录字段,来达到存储数据的目的。
持久化类:通过上面解释的,持久化类就是可以将类保存到数据库中,并还可以从数据库中拿到该类,这就叫持久化类,也就是下面说到的POJO类
持久化对象:持久化类的实例对象,能保存到数据库中,也能从数据库中取出来。
JPA的概念:Java Persistence API java持久化API,也就是java持久化的规范,ORM就是这JPA中所定义的,它还规定了其它很多规范,JPA维护一个Persistence Context(持久化上下文),这就是这个持久化上下文来事。那些ORM框架都要依据JPA规范来设计,那么各个ORM框架也就度有这么个持久化上下文。持久化上下文大体内容:1、ORM元数据,JPA支持annotion(注解)或xml两种形式描述对象/关系映射 2、实体操作API,实现对实体对象的CRUD操作 3、查询语言,约定了面向对象的查询语言JPQL(javaPersistence Query Language)
知道了一些大概的名词解释,现在来看看hibernate在一个工程中到底处于一个什么样的地位
简要体系架构结构
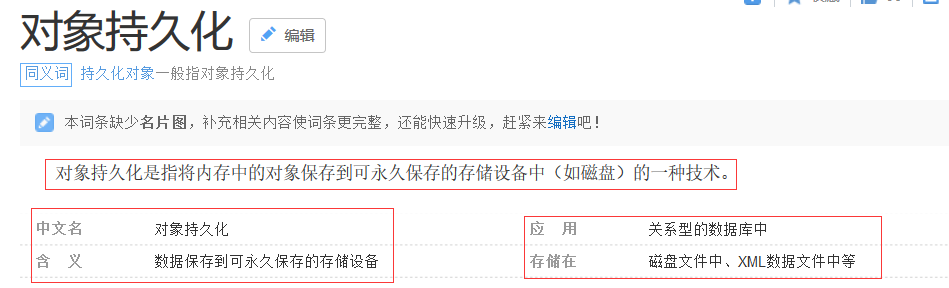
简要的hibernate体系架构就如上图所示,就如我们说的那样,hibernate在Application和Database之间,所以我们使用hibernate来实现对Database的操作。
我们配置xxx.hbm.xml:目的就是为了hibernate与我们的application想关联
我们配置hibernate.cfg.xml:与数据库相关的服务,例如:用户名和密码等。还有自身hibernate的服务。
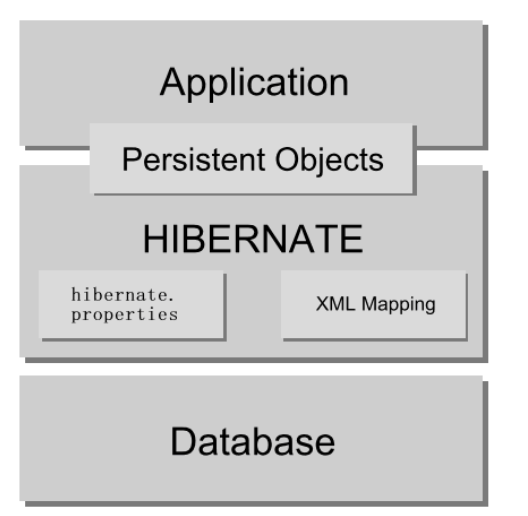
Hibernate全面解决方案体系架构
二、hibernate有什么作用?
前面知道了什么事hibernate,其实也就是知道hibernate的一些特性,很虚的东西,但是我们用它到底来做什么呢?
1、通过hibernate,完成POJO类到数据库表的映射关系
2、通过hibernate,只需要操作对象,hibernate就帮我们生成数据库语句去操作数据库,我们不必管下面的语句是怎么样的。
3、大概就是上面说的这两个,就是让用户来对对象的增加、删除、修改操作,来达到对数据库表中数据的这种增删改的操作。
三、使用hibernate需要导的jar包和jar包的意思?
虽然不知道jar包的里面怎么实现的,但是还是有那个好奇心,必须知道这个jar包是干什么的,不然就像个傻子一样就知道复制黏贴,我相信,学完这个hibernate,我就会知道jar包里面都有什么的。
通过xxx.hbm.xml配置文件来反应pojo类和数据库表的映射关系。

基本的,只需要导入这上面11个jar包,如果需要别的功能,可能会导入额外的jar包
antlr.jar:Another Tool for Language Recognition 可以构造语言识别器,为解析HQL(后面会讲到,hibernate Query language)时使用
commons-conllections.jar:就是加强版的collections。 比java.util.* 更强大的集合类
dom4j.jar:解析xml用的,
hibernate-jpa.jar 使用hibernate所依赖的jar包,jpa是一种规范,而hibernate是它的一种实现。
hibernate3.jar:hibernate的核心jar包
javassist.jar:操作字节码文件,跟cglib有关(cglib应该是动态代理的一种,有jdk动态代理)
jta.jar:java transaction api,就是跟事务有关的
log4j.jar:log4j日志
mysql-connector.jar:mysql的连接驱动包
slf4j-api.jar:整合其它日志的规范接口,也就是如果要将其它日志的jar包整合进来就要符合该规范
slf4j-log4j.jar:用来整合log4j和规范接口,让log4j符合规范,这样才能使用
四、如何实现POJO类到数据库表的映射关系,xxx.hbm.xml配置文件发威了
因为有这个配置文件,pojo类具有操作的能力了。

1、dtd文件:在hibernate3.jar下的org.hibernate/hibernate-mapping-3.0.dtd中找到。
2、基本的就只需要加<hibernate-mapping></hibernate-mapping>,在这对标签下写代码,来映射。
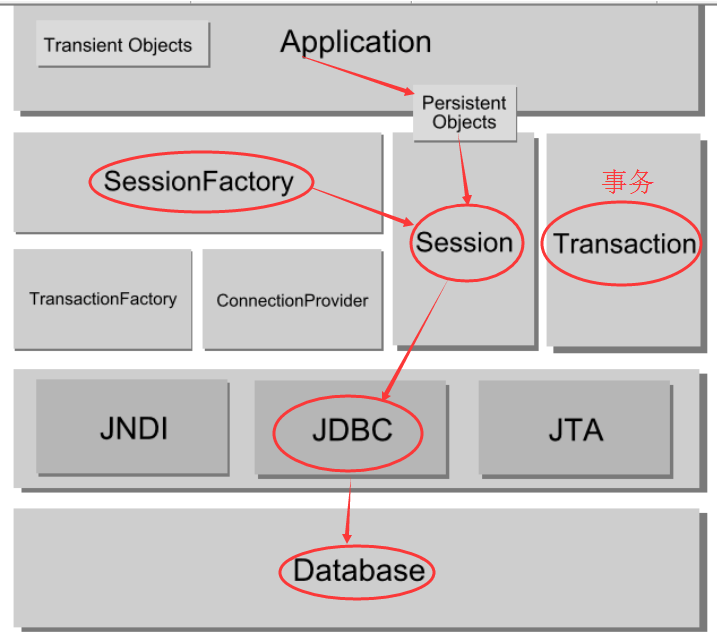
3、举例说明,User.java User.hbm.xml
User.java
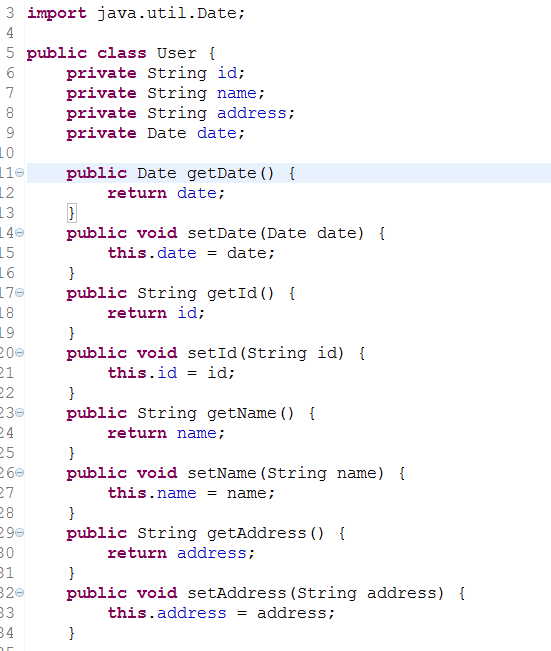
User.hbm.xml
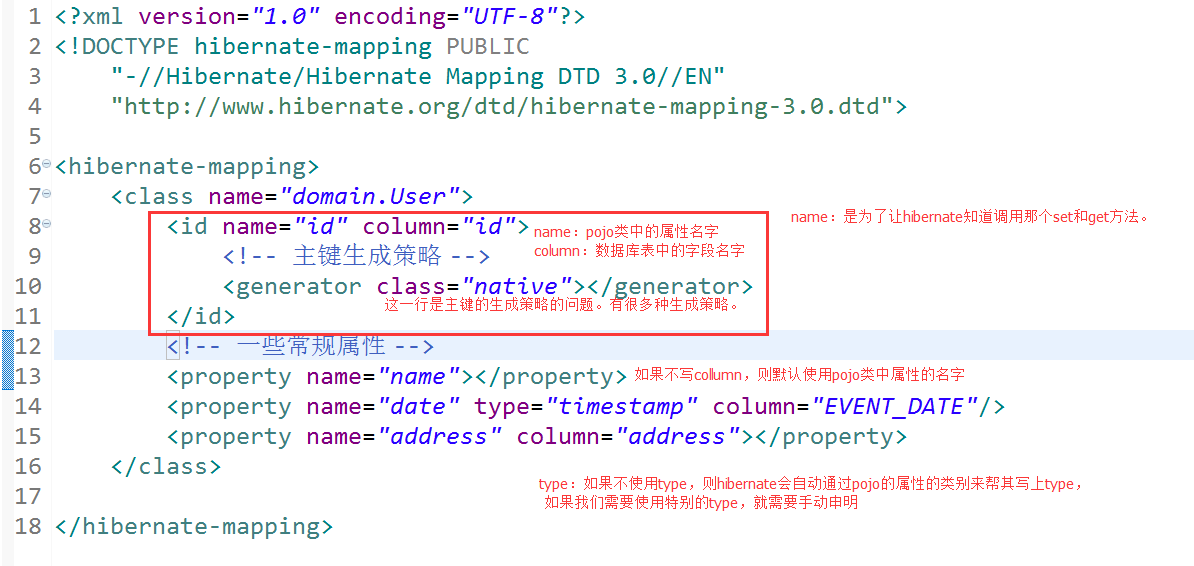
主键生产策略:
1、increment:主键自动增长、由hibernate来管理
注意:如果数据库也设置了自动增长,就会发生主键冲突问题
2、identity:由底层数据库来管理生成,不由hibernate管理
也就是说底层数据库怎么设置的主键就怎么来
注意:mysql、sql server可以,oracle不可以
3、sequence:标识符生成器,就是底层数据库来管理生成,利用底层数据库提供的序列来生成标识符,不由hibernate管理
注意:mysql不支持序列 oracle支持
4、native:由底层数据库自己来决定使用什么策略,hibernate不管
注意:mysql自动选择identity、oracle自动选择sequence
5、uuid:随机生成32位不相同的字符串。
主键分自然主键和代理主键
1自然主键:也就是在业务中有具体意义的主键,
2代理主键,就是上面我们说的那5种,没有任何意义,只是标识主键是唯一的。
其它的一些配置信息,还有什么不理解的可以参考hibernate的api手册。里面讲解的非常详细。
五、hibernate的配置,hibernate.cfg.xml
有了xxx.hbm.xml这个映射文件还不够,因为hibernate需要连接数据库,那么这些操作放哪里呢,就提取出一个公用的配置文件出来,hibernate.cfg.xml就是这种公共的配置文件,加载数据库连接的信息,和将各种映射文件加载进来,其实就是抽取出来的,因为有很多映射文件,每个映射文件都需要连接数据库等操作,那么久将共同的操作提取出来形成了hibernate.cfg.xml。

1、ddl策略:
1、create、创建表,启动的时候,先drop然后再创建表,(测试人员用来测试数据,先清除掉前面的旧表,在创建新表)
2、create-drop:也表示创建,创建完后,就drop掉。(测试程序是否正确)
3、update:检测类和表是否一致,不一致就会做更新,将表更新到和类一样
4、validate:启动时检测表和类是否一致,不一致则报异常
一般常用update、validate。
六、有了xxx.hbm.xml和hibernate.cfg.xml后,就能使用hibernate的功能了。
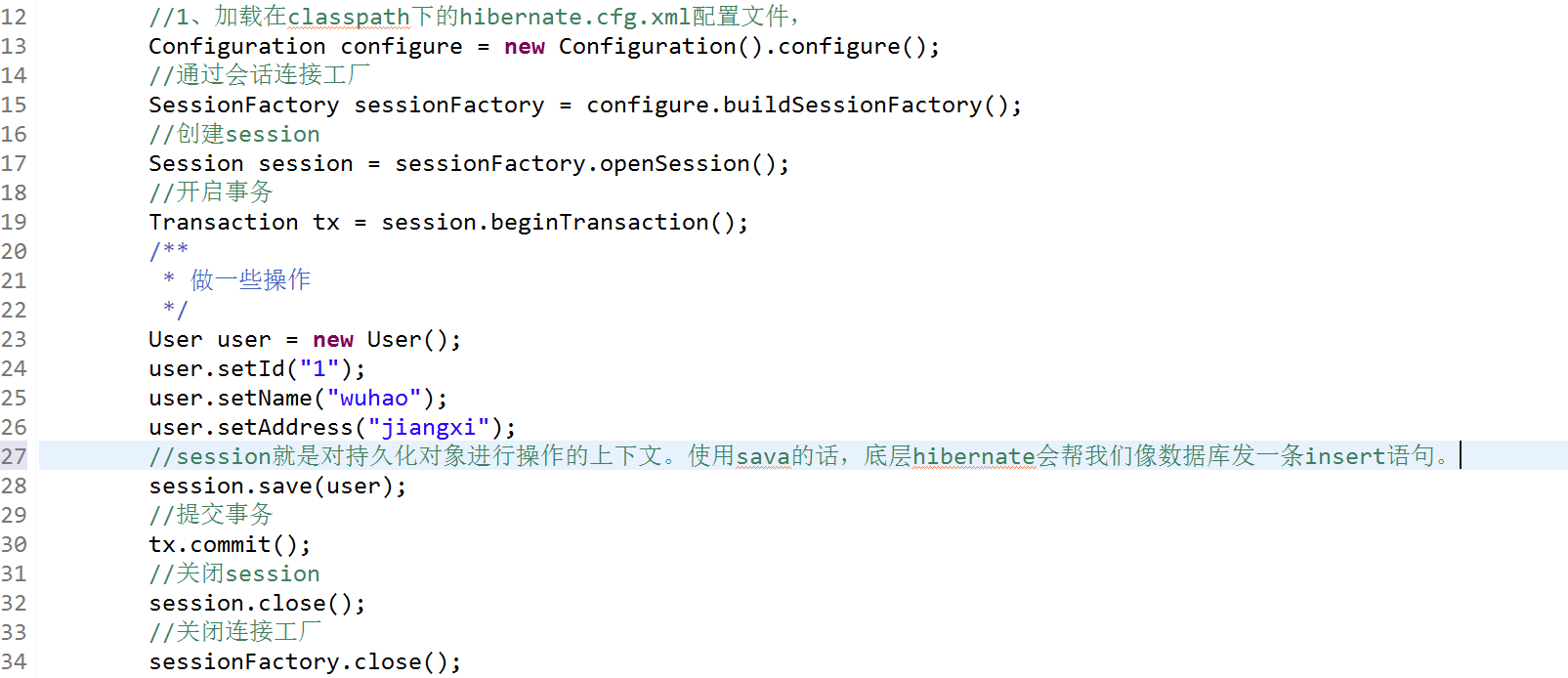
说明:本章中截图里面多了一个User类中多了个date属性,是为了说明解释xxx.hbm.xml中type属性的。没其他作用。可以忽视。
,
最新文章
- linux2.6 内存管理——逻辑地址转换为线性地址(逻辑地址、线性地址、物理地址、虚拟地址)
- tyvj1172 自然数拆分Lunatic版
- SpringMvc 页面DATE传值问题
- C++ 添加库
- TortoiseSVN 同步分支
- MonoBehaviour.StopCoroutine
- LeetCode Maximum Product Subarray 最大子序列积
- maven的pom报plugins却是的解决方法2
- android NDK 笔记
- HTML新元素
- Visual Studio在页面按F7不能跳转至cs代码页的解决方法
- php获取apk信息
- 关于jquery文件上传插件 uploadify 3.1的使用
- virus.win32.parite.H查杀病毒的方法
- PowerBI开发 第七篇:数据集和数据刷新
- #tensorflow入门(1)
- 关于mysql使用命令行时出现Data too long for column的解决方案:
- 《高级软件测试》JIRA使用手册(二)JIRA安装
- [工具]K8tools github/K8工具合集/K8网盘
- python框架之Django(4)-视图&路由