在linux上安装spark详细步骤
2024-10-18 01:55:44
在linux上安装spark ,前提要部署了hadoop,并且安装了scala.
对应版本
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
| 名称 | 版本 |
| JDK | 1.8.0 |
| hadoop | 2.6.0 |
| scala | 2.11.0 |
| spark | 2.2.0 |
第一步,下载 https://spark.apache.org/downloads.html
第二步,解压
tar -zxvf spark-2.2.-bin-hadoop2..tgz
第三步,配置环境变量
vi /etc/profile
#SPARK_HOME
export SPARK_HOME=/home/hadoop/spark-2.2.-bin-hadoop2.
export PATH=$SPARK_HOME/bin:$PATH
第四步,spark配置,
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
spark-env.sh
JAVA_HOME=/home/hadoop/jdk1..0_144
SCALA_HOME=/home/hadoop/scala-2.11.
HADOOP_HOME=/home/hadoop/hadoop260
HADOOP_CONF_DIR=/home/hadoop/hadoop260/etc/hadoop
SPARK_MASTER_IP=ltt1.bg.cn
SPARK_MASTER_PORT=
SPARK_MASTER_WEBUI_PORT=
SPARK_WORKER_CORES=
SPARK_WORKER_MEMORY=2g #spark里许多用到内存的地方默认1g 2g 这里最好设置大与1g
SPARK_WORKER_PORT=
SPARK_WORKER_WEBUI_PORT=
SPARK_WORKER_INSTANCES=
spark-defaults.conf
spark.master spark://ltt1.bg.cn:7077
slaves
ltt3.bg.cn
ltt4.bg.cn
ltt5.bg.cn
-----------------------------
如果整合hive,hive用到mysql数据库的话,需要将mysql数据库连接驱动jmysql-connector-java-5.1.7-bin.jar放到$SPARK_HOME/jars目录下
------------------------------
第五步,将spark-2.2.0-bin-hadoop2.6 分发到各节点。启动
[hadoop@ltt1 sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-2.2.-bin-hadoop2./logs/spark-hadoop-org.apache.spark.deploy.master.Master--ltt1.bg.cn.out
ltt5.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.-bin-hadoop2./logs/spark-hadoop-org.apache.spark.deploy.worker.Worker--ltt5.bg.cn.out
ltt4.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.-bin-hadoop2./logs/spark-hadoop-org.apache.spark.deploy.worker.Worker--ltt4.bg.cn.out
ltt3.bg.cn: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.2.-bin-hadoop2./logs/spark-hadoop-org.apache.spark.deploy.worker.Worker--ltt3.bg.cn.out
最后查看进程
master节点
[hadoop@ltt1 sbin]$ jps
NameNode
JournalNode
ResourceManager
QuorumPeerMain
DFSZKFailoverController
Master
Jps
worker节点
[hadoop@ltt5 ~]$ jps
NodeManager
Worker
Jps
DataNode
进入Spark的Web管理页面: http://ltt1.bg.cn:8080
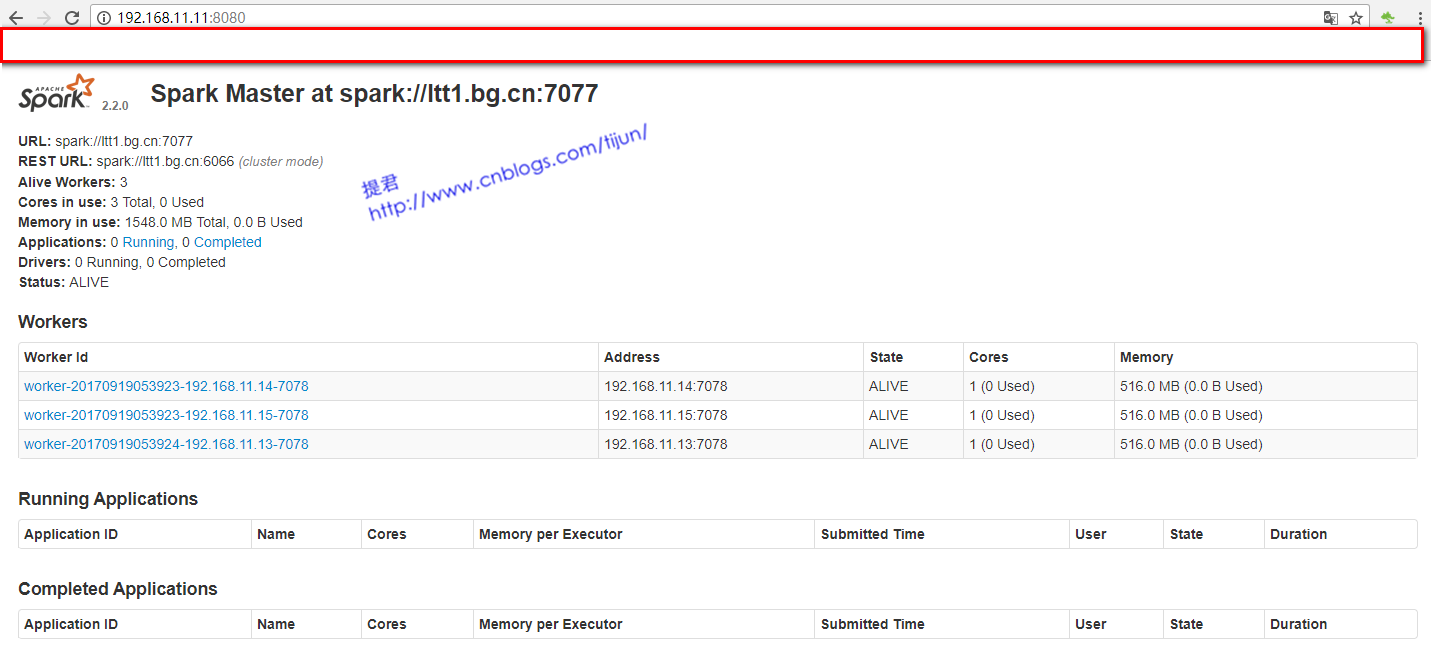
spark安装完成。
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
最新文章
- u-boot的配置、编译及链接
- 读取SD卡文件夹下的MP3文件和播放MP3文件
- 使用MyEclipse生成Java注释时,使用的Code Template
- nfs基本配置
- 设计模式:命令模式(Command)
- MDK中 use microlib
- JAVA while循环,do-while循环,for循环
- android中设置Animation 动画效果
- c3p0配置文件报错 对实体 "characterEncoding" 的引用必须以 ';' 分隔符结尾。
- 在FMX中实现PostMessage的方法
- 2D特效和3D特效
- obj-c编程15[Cocoa实例01]:一个会发声的随机数生成器
- 使用Jmeter监测服务器性能指标
- ZAmbIE [DDoS Attacks](DDOS攻击)
- 如何查看k8s存在etcd中的数据(转)
- nagios 报警参数
- windows多线程--原子操作
- sap gui 定义类并实现接口
- linux 发送Post请求 json格式
- noip第22课作业
热门文章
- 原生js获取鼠标坐标方法全面讲解:clientX/Y,pageX/Y,offsetX/Y,layerX/Y,screenX/Y
- pip自动生成和安装requirements.txt
- Nginx+Keepalived双机热备
- centos7下kubernetes(8.kubernetes Failover)
- Nginx代理与负载均衡
- redis加锁
- json_encode里面经常用到的 JSON_UNESCAPED_UNICODE和JSON_UNESCAPED_SLASHES
- ASP.Net:Javascript 通过PageMethods 调用后端WebMethod方法 + 多线程数据处理 示例
- Java使用Future设置方法超时
- 《程序猿闭门造车》之NBPM工作流引擎 - 项目整体架构