Flink 操作链与任务槽
2024-09-01 20:23:11
Operator Chains(操作链)
Flink出于分布式执行的目的,将operator的subtask链接在一起形成task(类似spark中的管道)。
每个task在一个线程中执行。
将operators链接成task是非常有效的优化:它可以减少线程与线程间的切换和数据缓冲的开销,并在降低延迟的同时提高整体吞吐量。
链接的行为可以在编程API中进行指定,详情请见代码OperatorChainTest。
开启操作链 和 禁用操作链的对比图(默认开启):
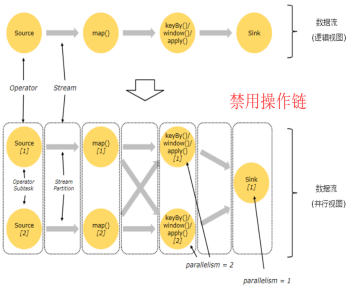
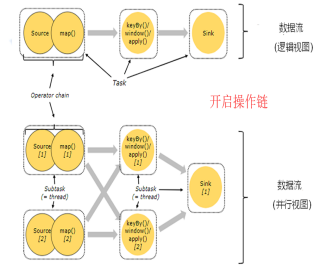
Flink默认会将多个operator进行串联,形成任务链(task chain)
注意: task chain 可以理解为就是 operator chain 只是不同场景下,称呼不同。
我们也可以禁用任务链,让每个operator形成一个task。
StreamExecutionEnvironment.disableOperatorChaining() 这个方法会禁用整条工作链
操作链其实就是类似spark的pipeline管道模式,一个task可以执行同一个窄依赖中的算子操作。
我们也可以细粒度的控制工作链的形成,比如调用dataStreamSource.map(...).startNewChain(),但不能使用dataStreamSource.startNewChain()
dataStreamSource.filter(...).map(...).startNewChain().map(...),需要注意的是,当这样写时相当于source和filter组成一条链,两个map组成一条链。
即在filter和map之间断开,各自形成单独的链。
代码:
package com.ronnie.flink.stream.test; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /**
* 开启与禁用工作链时,输出的结果不一样。
* 当开启工作链时(默认启动),operator map1与map2 组成一个task.
* 此时task运行时,对于hello,flink 这两条数据是:
* 先打印 hello ---- 1 , hello->1 ---- 2
* 后打印 flink ---- 1 , flink->1 ---- 2
* 当禁用工作链时,operator map1与map2 分别在两个task中执行
* 此时task运行时,对于hello,flink 这两条数据是:
* 先打印 hello ---- 1 , flink ---- 1
* 后打印 hello->1 ---- 2 , flink->1 ---- 2
*
* 注:操作链类似spark的管道,一个task执行多个的算子.
*/
public class OperatorChainTest { public static final String[] WORDS = new String[] {
"hello",
"flink",
"spark",
"hbase"
}; public static void main(String[] args) {
// 设置执行环境, 类似spark中初始化sparkContext一样
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 关闭操作链..
env.disableOperatorChaining(); DataStreamSource<String> dataStreamSource = env.fromElements(WORDS); SingleOutputStreamOperator<String> pairStream = dataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 1");
return value + "->1";
}
}).map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 2");
return value + "->2";
}
}); // 还可以控制更细粒度的任务链,比如指明从哪个operator开始形成一条新的链
// someStream.map(...).startNewChain(),但不能使用someStream.startNewChain()。
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Task slots(任务槽)
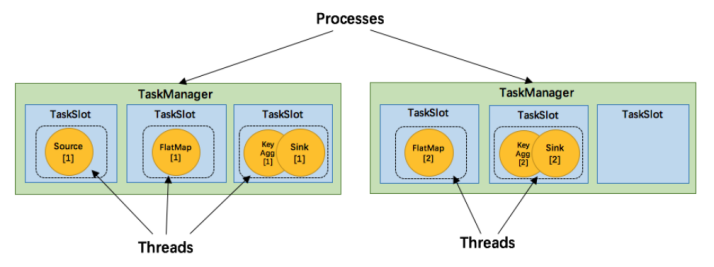
- TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。
- 为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
- Flink 中的计算资源通过 Task Slot 来定义。每个 task slot 代表了 TaskManager 的一个固定大小的资源子集。
- 例如,一个拥有3个slot的 TaskManager,会将其管理的内存平均分成三分分给各个 slot。
- 将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。
- 需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的内存。
- 通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。
- 每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。
- 每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
- 而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。
- 也能共享一些数据结构,一定程度上减少了每个task的消耗。
- 如图中所示,5个Task可能会在TaskManager的slots中分布,图中共2个TaskManager,每个有3个slot。
最新文章
- js的click事件传递参数方法
- elasticsearch-查询
- 【HDU 3938】Portal (并查集+离线)
- UrlConnection连接和Socket连接的区别
- Newspaper Headline_set(upper_bound)
- aspx中的表单验证 jquery.validate.js 的使用 以及 jquery.validate相关扩展验证(Jquery表单提交验证插件)
- 前端必会的js知识总结整理
- UVa 1395 (最小生成树) Slim Span
- Ubuntu下安装Skyeye
- Android各种颜色dawable.xml中定义
- MVC View基础(转)
- HDU 4293 Groups
- JavaScript shift() 方法
- Spring Security OAuth2 Demo -- good
- ibatis 多种传参方式
- NFS服务端与客户端配置
- 自动化测试-20.selenium之FireFox下载项配置
- 树莓派 温度监控 PWM 控制风扇 shell python c 语言
- 微软BI 之SSRS 系列 - 报表邮件订阅中 SMTP 服务器匿名访问与 Windows验证, 以及如何成功订阅报表的实例
- CentOS7安装OpenStack(Rocky版)-09.安装Cinder存储服务组件(控制节点)