【大数据面试】【框架】Shuffle优化、内存参数配置、Yarn工作机制、调度器使用
三、MapReduce
1、Shuffle及其优化☆
Shuffle是Map方法之后,Reduce方法之前,混洗的过程
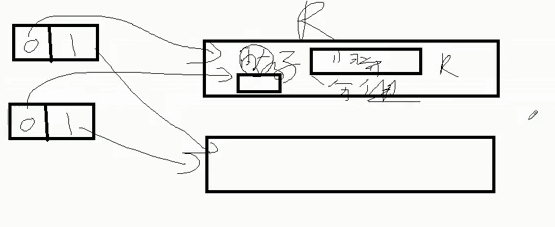
Map-->getPartition(标记数据的分区)-->对应的环形缓冲区(一侧存数据,一侧存索引,默认大小为100M,达到80%时进行反向溢写以提高空间利用率)
(溢写前需要对数据进行排序,默认快排,对key的索引排序,按照字典顺序排)(会产生大量的溢写文件)
【如何对溢写文件进行排序】:按照指定分区进行归并排序
优化:
环形缓冲区调整为200m,反向溢写的比例达到90+%,减少溢写的个数
溢写前进行一次combiner求和,默认一次归并10个,调大其数值(服务器性能可以,不会OOM内存溢出)
对数据进行压缩
【哪些地方能够对数据进行压缩?如何压缩】
Map输入输出端、Reduce的输出端
Map输入:数据量超过128M时,看是否有必要对数据切片,lzo、bzip2支持切片(数据量大时)
Map输出:快的是snappy、lzo
Reduce的输出端:看数据的最终流向(下一个MR看是否支持切片)(永久保存考虑压缩比最高)
【100个分区的数据,默认一次拉取5个,增大每批次拉取的个数,和reduce阶段的内存】
2、NodeManager的默认内存
企业服务器默认内存是128G
NodeManager的默认内存:8G【通常需要调整】
Map Task
Reduce Task
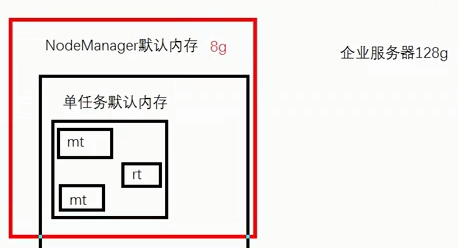
16G的任务,OOM
默认不配置就是8G内存,生产环境下需要配置到90-100G左右,给其他服务器资源留10G左右
3、配置单任务的默认内存
单任务的默认内存:8G
如果有1G/1T/10T的数据
如何调整其内存
估计,128M数据,对应1G内存
1G数据,对应8G内存左右
2G数据量,对应16G内存左右
4、其他默认
Map Task:1G
Reduce Task:1G
如果数据量是128M,不用调整
如果数据量大,且不支持切片,如500M,就需要根据比例调整,配置4G的内存
进入reduce的数据量比较大,适当增大内存
5、配置参数的等级优先级
defaul==》site.xml==》Idea的配置文件==》代码
6、Hadoop命令行如何提交文件
maven打包
hadoop jar wc.jar Class类名 输入路径 输出路径
7、内存设置

8、其他
Spark Shuffle和Hadoop Shuffle的区别
各讲一下其原理
四、Yarn
1、Yarn工作机制(笔试题)【客户端和集群】
客户端
集群:ResourceManager
集群模式(xml是参数的等级,切片影响MapTask的个数)
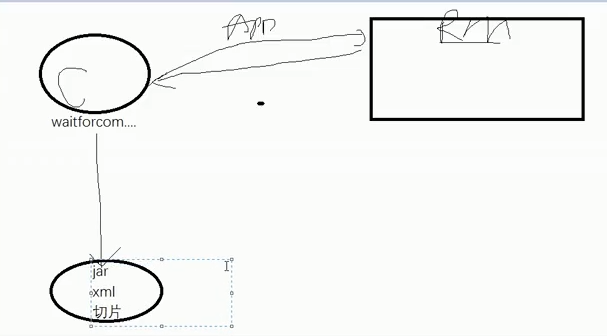
任务在队列中排队,nodemanager接收并执行任务
ApplicationMasterr负责执行,内部container容器拉取指定分区数据
Map按照分区存储在磁盘上-》reduce阶段,拉取完指定数据后释放
2、Yarn的调度器(与生产环境相关)
常见调度器:FIFO、容量、公平调度器
默认调度器是?Apache和CDH
FIFO调度器:支持单队列、先进先出(生产环境不会用)
容量调度器(Apache消耗资源少):支持多个队列,优先保证先进来的资源执行
公平调度器(CDH,占用资源多,需要内存大):保证所有任务公平享有资源,每个任务都分配2G,新进入任务,其他任务释放一定资源。保证每个任务公平享有资源
3、生产环境下如何选择
如果对并发度要求比较高,选择公平调度器,要求服务器性能必须好【大公司】
中小公司一般使用容量调度器,集群服务器资源不太充裕
4、容量调度器默认几个队列
默认只有一个default队列
5、生产环境下如何创建队列
两种方式
可以按照框架:hive/spark/flink放入指定的队列中【企业不常用】
也可以按照业务模块划分:登录队列、注册、购物车、下单、业务部门1、业务部门2
原因:怕新员工写递归死循环代码,导致所有资源全部耗尽
切记,不要使用rm -rf /*
也可以对任务队列划分优先级,集群资源不够用,只留重点资源的执行,对其他资源进行降级
最新文章
- UE4 去除不正确的水面倒影以及不完整镜头轮廓
- hdu 3518 Boring counting 后缀数组基础题
- MyEclipse Spring 学习总结三 SpringMVC 表单处理
- eclipse 导入Maven项目的问题
- 【LeetCode】6 - ZigZag Conversion
- WebRTC源码分析:音频模块结构分析
- UVA 10106 (13.08.02)
- 【noip 2009】 乌龟棋 记忆化搜索&动规
- 如何在markdown中打出上标、下标和一些特殊符号
- 巨杉数据库入选Gartner数据库报告,中国首家入选厂商
- 外媒评李开复的《AI·未来》:四大浪潮正在席卷全球
- iOS12 XCode10更新
- 【BZOJ3561】DZY Loves Math VI (数论)
- 012-docker-安装-fabric:1.4
- 问题解决java.lang.IllegalArgumentException at org.springframework.asm.ClassReader
- 9-9-B+树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
- 搜索入门_简单搜索bfs dfs大杂烩
- Unity 3D与Android Studio安卓交互之-导出jar包
- linux下c语言实现双进程运行
- iOS App与iTunes文件传输的方法和对iOS App文件结构的说明