ES字段类型
1 String
ELasticsearch 5.X之后的字段类型不再支持string,由text和keyword取代,不做说明。
2 text和keyword
2.1 简介
ElasticSearch 5.0以后,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
ElasticSearch字符串将默认被同时映射成text和keyword类型
2.2 示例
PUT /myindex/_doc/1
{
"id":1,
"name":"手机",
"price":3888.8,
"desc":"USA has apple China has pineapple"
}
2)查询mapping映射
GET /myindex/_mapping
结果如下,已字段desc为例,它的type是text,但是为desc自动创建了一个keyword类型的字段。也就是ElasticSearch字符串将默认被同时映射成text和keyword类型
{
"myindex" : {
"mappings" : {
"properties" : {
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "float"
}
}
}
}
}
2.3 Text 与keyword的区别
Text:
会分词,然后进行索引
支持模糊、精确查询
不支持聚合
keyword:
不进行分词,直接索引
支持模糊、精确查询
支持聚合
2.4 示例
Text会分词,然后进行索引,keyword不进行分词,直接索引
1)直接通过text搜索
GET /myindex/_search
{
"query":{
"match":{
"desc":"USA has apple"
}
}
}
结果如下,说明text会被分词,进行索引
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.970927,
"hits" : [
{
"_index" : "myindex",
"_type" : "mytype",
"_id" : "1",
"_score" : 0.970927,
"_source" : {
"id" : 1,
"name" : "手机",
"price" : 3888.8,
"desc" : "USA has apple China has pineapple"
}
}
]
}
}
2)通过keyword进行搜索
GET /myindex/_search
{
"query":{
"match":{
"desc.keyword":"USA has apple"
}
}
}
搜索结果如下,没有搜索到数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
3)再次用keyword进行搜索,搜索到一条结果
GET /myindex/_search
{
"query":{
"match":{
"desc.keyword":"USA has apple China has pineapple"
}
}
}
说明keyword不进行分词,整个直接进入索引
3 数字类型
3.1 ES支持的数字类型

3.2 -0.0和+0.0
对于float、half_float和scaled_float,-0.0和+0.0是不同的值,使用term查询查找-0.0不会匹配+0.0,同样range查询中上边界是-0.0不会匹配+0.0,下边界是+0.0不会匹配-0.0
3.3 数字类型的选择
对于数字类型的数据,选择以上数据类型的注意事项:
1)在满足需求的情况下,尽可能选择范围小的数据类型。比如,某个字段的取值最大值不会超过100,那么选择byte类型即可。迄今为止吉尼斯记录的人类的年龄的最大值为134岁,对于年龄字段,short足矣。字段的长度越短,索引和搜索的效率越高。
2)优先考虑使用带缩放因子的浮点类型
3.4 t添加一个带缩放因子的浮点类型示例
PUT /myindex2
{
"mappings": {
"properties":{
"mathscore":{
"type":"scaled_float",
"scaling_factor":100
}
}
}
}
添加数据,实际上,ES内部存储的是:12.386 * 100(缩放因子) = 1238.6,然后四舍五入得到1239,所以内部真正存储的是1239
PUT /myindex2/_doc/1
{
"mathscore":12.386
}
查询
GET /myindex2/_search
{
"query":{
"match":{
"mathscore":12.386
}
}
}
查询结果
{
"took" : 97,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "myindex2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"mathscore" : 12.385
}
}
]
}
}
过查询结果可以看到,通过12.386查询出了ID为1的文档,实际上ES是将查询条件:12.386 * 100(缩放因子) = 1238.6,然后四舍五入之后到最近的长值得到1239,这样就能匹配到ID为1的文档。
需要注意的是,虽然ES在内部做了缩放处理,但是查询返回值还是原始值(12.385)
4 Object类型
JSON天生具有层级关系,文档会包含嵌套的对象
4.1 示例
PUT myindex/_doc/4
{
"region": "US",
"manager": {
"age": 30,
"name": {
"first": "John",
"last": "Smith"
}
}
}
上面的文档中,整体是一个JSON,JSON中包含一个manager,manager又包含一个name。最终,文档会被索引成key-value对
{
"region": "US",
"manager.age": 30,
"manager.name.first": "John",
"manager.name.last": "Smith"
}
4.2 查询
下面两个查询都查不到结果
GET myindex/_search
{
"query": {
"match": {
"manager": "John"
}
}
} GET myindex/_search
{
"query": {
"match": {
"manager.name": "John"
}
}
}
下面的查询可以查到结果
GET myindex/_search
{
"query": {
"match": {
"manager.name.first": "John"
}
}
}
查询结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.13353139,
"hits" : [
{
"_index" : "myindex",
"_type" : "mytype",
"_id" : "4",
"_score" : 0.13353139,
"_source" : {
"region" : "US",
"manager" : {
"age" : 30,
"name" : {
"first" : "John",
"last" : "Smith"
}
}
}
}
]
}
}
5 date类型
5.1 简介
JSON中没有date类型,es中的date可以由下面3种方式表示
1)格式化的date字符串,例如"2018-01-01"或者"2018-01-01 12:00:00"
2)一个long型的数字,代表从1970年1月1号0点到现在的毫秒数
3)一个integer型的数字,代表从1970年1月1号0点到现在的秒数
在es内部,date被转为UTC,并被存储为一个长整型数字,代表从1970年1月1号0点到现在的毫秒数
date类型字段上的查询会在内部被转为对long型值的范围查询,查询的结果类型是字符串。
假如插入的时候,值是"2018-01-01",则返回"2018-01-01"
假如插入的时候,值是"2018-01-01 12:00:00",则返回"2018-01-01 12:00:00"
假如插入的时候,值是1514736000000,则返回"1514736000000"。(进去是long型,出来是String型)
5.2 默认格式
date格式可以在put mapping的时候用 format 参数指定,如果不指定的话,则启用默认格式,是"strict_date_optional_time||epoch_millis"。
这表明只接受符合"strict_date_optional_time"格式的字符串值,或者long型数字。
5.2.1 strict_date_optional_time
strict_date_optional_time是date_optional_time的严格级别,这个严格指的是年份、月份、天必须分别以4位、2位、2位表示,不足两位的话第一位需用0补齐。不满足这个格式的日期字符串是放不进es中的。
实测strict_date_optional_time,仅支持"yyyy-MM-dd"、"yyyyMMdd"、"yyyyMMddHHmmss"、"yyyy-MM-ddTHH:mm:ss"、"yyyy-MM-ddTHH:mm:ss.SSS"、"yyyy-MM-ddTHH:mm:ss.SSSZ"格式
不支持常用的"yyyy-MM-dd HH:mm:ss"等格式。注意,"T"和"Z"是固定的字符
5.2.2 epoch_millis
epoch_millis约束值必须大于等于Long.MIN_VALUE,小于等于Long.MAX_VALUE
date类型字段除了type参数必须指定为date外,还有一个常用的参数 format 。可以通过该参数来显式指定es接受的date格式,如果有多个的话,多个date格式需用||分隔。之后index/create/update操作时,将依次匹配,如果匹配到合适的格式,则会操作成功,并且查询时,该文档该字段也会以该格式展示。否则,操作不成功。
5.2.3 示例
添加一个字段名为update_date,类型为date,格式为yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis的字段
PUT myindex/_mapping
{
"properties": {
"updated_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
} }
6 Array类型
ELasticsearch没有专用的数组类型,默认情况下任何字段都可以包含一个或者多个值,但是一个数组中的值要是同一种类型。
1)字符数组: [ “one”, “two” ]
2)整型数组:[1,3]
3)嵌套数组:[1,[2,3]],等价于[1,2,3]
4)对象数组:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }]
注意事项
1)动态添加数据时,数组的第一个值的类型决定整个数组的类型
2)混合数组类型是不支持的,比如:[1,”abc”]
3)数组可以包含null值,空数组[ ]会被当做missing field对待
7 binary类型
binary类型接受base64编码的字符串,默认不存储也不可搜索
7.1 添加一个binary类型字段blobs
PUT myindex/_mapping
{ "properties": {
"blobs": {
"type": "binary"
}
}
}
7.2 添加数据
PUT myindex/_doc/10
{
"blobs": "U29tZSBiaW5hcnkgYmxvYg=="
}
7.3 通过字段blobs查询
GET /myindex/_search
{
"query": {
"match":{
"blobs":"U29"
}
}
}
报错,提示binary类型的字段不支持查询
{
"error" : {
"root_cause" : [
{
"type" : "query_shard_exception",
"reason" : "Binary fields do not support searching",
"index_uuid" : "cSOGKPPDQF2TsecmZEY-ig",
"index" : "myindex"
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "myindex",
"node" : "WItnUli7SN2T159XFePjQQ",
"reason" : {
"type" : "query_shard_exception",
"reason" : "Binary fields do not support searching",
"index_uuid" : "cSOGKPPDQF2TsecmZEY-ig",
"index" : "myindex"
}
}
]
},
"status" : 400
}
8 IP类型
ip类型的字段用于存储IPV4或者IPV6的地址
8.1 添加一个类型为ip的字段ip_addr
PUT myindex/_mapping
{
"properties":{
"ip_addr":{
"type":"ip"
}
}
}
8.2 添加数据
PUT myindex/_doc/11
{
"ip_addr":"192.168.128.110"
}
8.3 通过ip_addr精确查询
GET myindex/_search
{
"query": {
"match": {
"ip_addr":"192.168.128.110"
}
}
}
查询结果
{
"took" : 574,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "myindex",
"_type" : "mytype",
"_id" : "11",
"_score" : 1.0,
"_source" : {
"ip_addr" : "192.168.128.110"
}
}
]
}
}
9 range类型
范围类型(range)是es中比较具有特色的数据类型
9.1 range的几种类型

9.2 示例
range类型的使用场景:比如前端的时间选择表单、年龄范围选择表单等。
1)创建一个Integer_range类型字段和一个date_range类型字段
假设我们有一张会议表。我们知道实际中党政机关会议都有一个出席率的问题,需要出席率在某个点或某个区间内才能算作是有效的。所以我们的映射结构来了
PUT range_index
{
"mappings": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
2)添加数据
假如这时我们需要添加一个10-20人参与,并且在2015-10-31到2015-11-01期间举行的会议
PUT range_index/_doc/1
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}
3)查询
我们需要查询会议时间在2015-08-01到2015-12-01之间的会议
GET range_index/_search
{
"query" : {
"range" : {
"time_frame" : {
"gte" : "2015-08-01",
"lte" : "2015-12-01",
"relation" : "within"
}
}
}
}
查询结果
{
"took" : 84,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "range_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}
}
]
}
}
9.3 relation
关键字
用range query查询range类型字段时,可以额外指定一个relation参数,默认值是intersects,其他可选值有within、contains。
intersects意思是只要文档range类型字段值指定的范围和range query指定的范围有交叉,就能查出来。
within表示只有查询范围包含文档范围时,能查出来。
contains表示只有文档范围包含查询范围时,能查出来
10 nested类型
10.1 简介
官方定义:官方释义:这个nested类型是object一种数据类型,允许对象数组以相互独立的方式进行索引
nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作。Elasticsearch没有内部对象的概念,因此,ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表
10.2 示例1Object类型
假如我们有如下order索引,包含订单的商品列表
10.2.1 添加数据
PUT /order/_doc/1
{
"order_name": "xiaomi order",
"desc": "shouji zhong de zhandouji",
"goods_count": 3,
"total_price": 12699,
"goods_list": [
{
"name": "xiaomi PRO MAX 5G",
"price": 4999
},
{
"name": "ganghuamo",
"price": 19
},
{
"name": "shoujike",
"price": 1999
}
]
}
PUT /order/_doc/2
{
"order_name": "Cleaning robot order",
"desc": "shouji zhong de zhandouji",
"goods_count": 2,
"total_price": 12699,
"goods_list": [
{
"name": "xiaomi cleaning robot order",
"price": 1999
},
{
"name": "dishwasher",
"price": 4999
}
]
}
10.2.2 查询
查询订单商品中商品名称为dishwasher并且商品价格为1999的订单信息,尝试执行以下脚本
GET order/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"goods_list.name": "dishwasher" // 条件一
}
},
{
"match": {
"goods_list.price": 1999 // 条件二
}
}
]
}
}
}
查询结果
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.7199211,
"hits" : [
{
"_index" : "order",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.7199211,
"_source" : {
"order_name" : "Cleaning robot order",
"desc" : "shouji zhong de zhandouji",
"goods_count" : 2,
"total_price" : 12699,
"goods_list" : [
{
"name" : "xiaomi cleaning robot order",
"price" : 1999
},
{
"name" : "dishwasher",
"price" : 4999
}
]
}
}
]
}
}
按照bool中must的查询逻辑,两个条件都符合的数据并不存在,然而执行查询后发现返回以下结果
10.2.3 原因
可以看到上述结果元数据中出现了订单数据,这和预期结果不一致。
因为当字段值为复杂数据类型(Object、Geo-Point等)的时候,ES内部实际是以如下方式保存数据的
{
"order_name": "Cleaning robot order",
"desc": "shouji zhong de zhandouji",
"goods_count": 2,
"total_price": 12699,
"goods_list.name":[ "alice", "cleaning", "robot", "order", "dishwasher" ],
"goods_list.price":[ 1999, 4999 ]
}
上述例子中goods_list中每个对象元素的属性值被扁平化存储在了数组中,此时已丢失了对应关系,因此无法保证搜索的准确
10.3 Nested类型
10.3.1 创建mapping
PUT order1
{
"mappings": {
"properties": {
"goods_list": {
"type": "nested",
"properties": {
"name": {
"type": "text"
}
}
}
}
}
}
10.3.2 添加数据
PUT /order1/_doc/1
{
"order_name": "xiaomi order",
"desc": "shouji zhong de zhandouji",
"goods_count": 3,
"total_price": 12699,
"goods_list": [
{
"name": "xiaomi PRO MAX 5G",
"price": 4999
},
{
"name": "ganghuamo",
"price": 19
},
{
"name": "shoujike",
"price": 1999
}
]
}
PUT /order1/_doc/2
{
"order_name": "Cleaning robot order",
"desc": "shouji zhong de zhandouji",
"goods_count": 2,
"total_price": 12699,
"goods_list": [
{
"name": "xiaomi cleaning robot order",
"price": 1999
},
{
"name": "dishwasher",
"price": 4999
}
]
}
10.3.3 查询
查询订单商品中商品名称为dishwasher并且商品价格为1999的订单信息,查不到结果
查询在外面嵌套了一个nested和path
GET /order1/_search
{
"query": {
"nested": {
"path": "goods_list",
"query": {
"bool": {
"must": [
{
"match": {
"goods_list.name": "dishwasher"
}
},
{
"match": {
"goods_list.price": 1999
}
}
]
}
}
}
}
}
再次查询订单商品中商品名称为dishwasher并且商品价格为4999的订单信息
GET /order1/_search
{
"query": {
"nested": {
"path": "goods_list",
"query": {
"bool": {
"must": [
{
"match": {
"goods_list.name": "dishwasher"
}
},
{
"match": {
"goods_list.price": 4999
}
}
]
}
}
}
}
}
查询到想要的结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.7844853,
"hits" : [
{
"_index" : "order1",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.7844853,
"_source" : {
"order_name" : "Cleaning robot order",
"desc" : "shouji zhong de zhandouji",
"goods_count" : 2,
"total_price" : 12699,
"goods_list" : [
{
"name" : "xiaomi cleaning robot order",
"price" : 1999
},
{
"name" : "dishwasher",
"price" : 4999
}
]
}
}
]
}
}
11 token_count类型
token_count是单词计数数据类型。
类型字段token_count实际上是一个integer,接受字符串值,对其进行分析,然后为字符串中的单词数量作为其值进行动态存储
1)添加一个类型为token_count的字段
PUT myindex2/_mapping
{
"properties": {
"music": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
2)添加数据
PUT myindex2/_doc/1
{ "music": "John Smith" } PUT myindex2/_doc/2
{ "music": "Rachel Alice Williams" }
3)查询
GET myindex2/_search
{
"query": {
"term": {
"music.length": 3
}
}
}
查询结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "myindex2",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"music" : "Rachel Alice Williams"
}
}
]
}
}
12 geo point 类型
地理位置信息类型用于存储地理位置信息的经纬度
12.1 es对空间地理的支持
参考:https://zhuanlan.zhihu.com/p/378770937
官网描述:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/geo-queries.html
可以看到,官网中提供了两种类型的地理数据,分别是基于经纬度的geo_point数据类型 和 基于GeoJson的geo_shape数据类型,并且geo_shape数据类型支持点、线、圆、多边形、多多边形等复杂的地理形状;
同时,ES支持的空间地理的语法一共有4种,分别如下:
1)geo_bounding_box
2)geo_distance
3)geo_polygon
4)geo_shape
12.2 数据准备
1)先创建一个mapping结构
用于存储经纬度信息,定义存储空间地理信息的字段的类型为 geo_point,mapping映射结构如下
PUT /location
{
"settings": {
"number_of_shards": "1",
"number_of_replicas": "0"
},
"mappings": {
"properties": {
"locationStr": {
"type": "geo_point"
}
}
}
}
2)创建好mapping映射结构后,再来批量插入一些经纬度数据到ES中,DSL语句如下
POST /location/_doc/_bulk
{"index":{"_id":1}}
{"locationStr":"40.17836693398477,116.64002551005981" }
{"index":{"_id":2}}
{"locationStr":"40.19103839805197,116.5624013764374" }
{"index":{"_id":3}}
{"locationStr":"40.13933715136454,116.63441990026217" }
{"index":{"_id":4}}
{"locationStr":"40.14901664712196,116.53067995860928" }
{"index":{"_id":5}}
{"locationStr":"40.125057718315716,116.62963567059545" }
{"index":{"_id":6}}
{"locationStr":"40.19216257806647,116.64025980109571" }
{"index":{"_id":7}}
{"locationStr":"40.16371689899584,116.63095084701624" }
{"index":{"_id":8}}
{"locationStr":"40.146045218040605,116.5696251832195" }
{"index":{"_id":9}}
{"locationStr":"40.144735806234166,116.60712460957835" }
12.3 ES的geo_bounding_box语法
12.3.1 简介
geo_bounding_box语法又称为地理坐标盒模型,在当前语法中,只需选择一个矩阵范围(输入矩阵的左上角的经纬度和矩阵的右上角的经纬度,构建成为一个矩阵),即可计算出当前矩阵中符合条件的元素;
用通俗易懂的话讲,就是给定两个坐标,通过这两个坐标形成对角线,平行于地球经纬度从而得到的一个矩阵。采用geo_bounding_box语法可以得到坐落于当前矩阵中的元素的信息;
假设我这边给定两个坐标,分别是北京市顺义西站(116.498353,40.187328) 和 北京市首都机场(116.610461,40.084509),这样我们就得到了一个矩阵,如下图所示,通过两个坐标确定一个矩阵

ES的geo_bounding_box语法有很多种查询方式,但是需要注意的是我们要确定好哪个是左上角的坐标,哪个是右下角的坐标,并且这两个坐标不能互换
12.3.2 基于经纬度属性的DSL语法
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"top_left": {
"lat": 40.187328,
"lon": 116.498353
},
"bottom_right": {
"lat": 40.084509,
"lon": 116.610461
}
}
}
}
}
通过执行上述DSL语句,可以得到一共有3个建筑元素坐落于这两个坐标所构建的矩阵中;
12.3.3 基于经纬度数组的DSL语法
# 需要注意的是,数组形式的,经纬度顺序需调换一下
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"top_left": [116.498353, 40.187328],
"bottom_right": [116.610461, 40.084509]
}
}
}
}
12.3.4 基于经纬度字符串的DSL语法
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"top_left": "40.187328, 116.498353",
"bottom_right": "40.084509,116.610461"
}
}
}
}
12.3.5 基于经纬度边界框WKT的DSL语法
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"wkt": "BBOX (116.498353,116.610461,40.187328,40.084509)"
}
}
}
}
12.3.6 基于经纬度GeoHash的DSL语法
# 关于GeoHash可以参考两个网址
# 全球GeoHash地图 http://geohash.gofreerange.com/
# GeoHash坐标在线转换 http://geohash.co/
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"top_left": "wx4udgz",
"bottom_right": "wx4uj91"
}
}
}
}
12.3.7 基于经纬度顶点属性的DSL语法
GET location/_search
{
"query": {
"geo_bounding_box": {
"locationStr": {
"top": 40.187328,
"left": 116.498353,
"bottom": 40.084509,
"right": 116.610461
}
}
}
}
至此,采用上述7种方式计算的矩阵坐落元素所执行结果均一致,且逐个在地图上核实,所召回的建筑均真实的在上图的矩阵中;
计算某个矩阵或者是多边形中的元素,在Redis中目前是不支持的,在这方面ES表现的更为强大;通过上述的三种语法可以看到,ES可以很好的支持 矩阵、圆、多边形的空间地理检索,通过查看Redis的语法可以看到Redis目前只支持圆的空间地理检索;
12.4 ES的geo_distance语法
12.4.1 简介
ES中的geo_distance语法与Redis中的georadius语法类似,通过给定一个坐标和半径,圈出圆内的点。在ES可以定义一些排序规则返回召回结果集数据与当前坐标的距离,Redis中默认返回了距离;
与geo_bounding_box语法类似,geo_distance语法也有多种查询方式,如 经纬度属性、经纬度数组、经纬度字符串、GeoHash等,下面就简单的以 经纬度字符串和GeoHash为例进行演示,重新选定坐标,以公司目前所在位置为例,理想总部经纬度为:(116.5864,40.174697),查询公司5km范围内的建筑
12.4.2 查询
GET location/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"locationStr": "40.174697,116.5864"
}
},
"sort": [
{
"_geo_distance": {
"locationStr": "40.174697,116.5864",
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
]
}
当前DSL一共召回了6条记录,其中第一条的信息为
{
"_index" : "location",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"locationStr" : "40.19103839805197,116.5624013764374"
},
"sort" : [
2.7309695122568725
]
}
返回结果集的每一条数据中,都包含一个 sort字段,里面的数据表示的是当前建筑坐标与当前用户坐标相差的直线距离,单位为km,单位是在上述DSL语句中指定的,但是这个是有误差的,细心的朋友可能会发现,我添加到ES中的数据的经纬度,比我查询时给定的经纬度在精度上相差很多。我们通常说做的坐标,在地图上看上去像是一个点,其实坐标都是描述的范围,只是跟地面参考,就变成了一个微乎其微的点了;
采用GeoHash方式查询的DSL语句如下,没有指定sort时,默认是没有返回坐标距离的
GET location/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"locationStr": "wx4uscxds42d"
}
}
}
12.5 ES的geo_polygon语法
12.5.1 简介
ES的geo_polygon语法,可以通过指定多个坐标点,从而构成一个多边形,然后从当前多边形中召回坐落其中的元素进行召回;在当前语法中,最少需要3个坐标,从而构成一个多边形;
ES的geo_point结构的3中语法,分别覆盖了矩形、圆、多边形的空间地理的召回;
为了方便演示,我这边在ES中新增一条记录,记录公司的所在位置经纬度为:(116.5864,40.174697)
POST location/_doc/10
{
"locationStr": "40.174697,116.5864"
}
然后可以指定3个坐标,将公司位置坐落于这三个坐标中,看看公司位置是否可以检索出来,3个坐标在地图上的展示如下
坐标点A:(116.577188,40.178012)
坐标点B:(116.586315,40.169329)
坐标点C:(116.591813,40.178288)
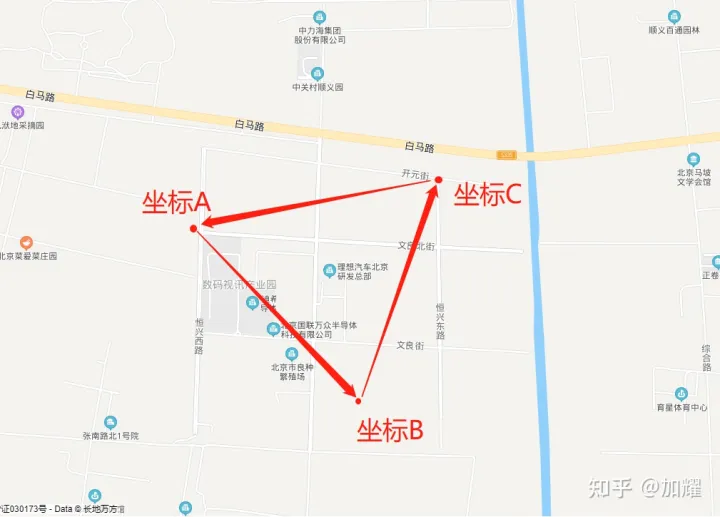
ES的geo_polygon语法也支持多种语法,如 经纬度数组、经纬度字符串、GeoHash值等;这里就采用字符串演示了,另外两种语法不再赘述;其执行结果如下
GET location/_search
{
"query": {
"geo_polygon": {
"locationStr": {
"points": [
"40.178012,116.577188",
"40.169329, 116.586315",
"40.178288, 116.591813"
]
}
}
}
}
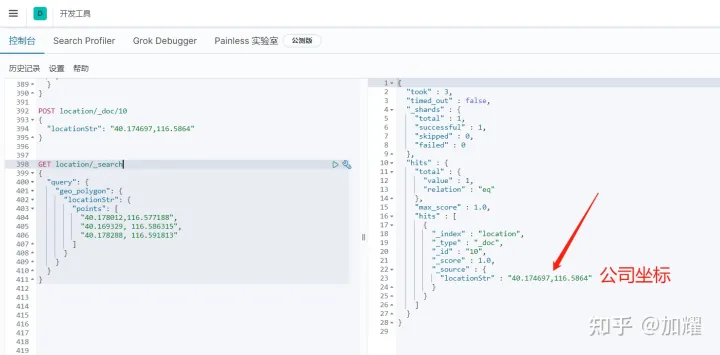
可以看到,通过三个点构建成一个三角形,当目标元素坐落于所构建的形状中,即可很好的将其召回;
到这里,关于ES的geo_point语法已经接近尾声了,简单的了解了一下ES的空间地理支持;下面再新增一种相对复杂一点的地形,看看geo_polygon语法可以很好的支持不。
通过刚才的3个坐标,我们新增一个坐标,构建一个凹形的多边形,将目标节点剔除在多边形外,看看ES在这方面的支持如何,最终构建的多边形如下
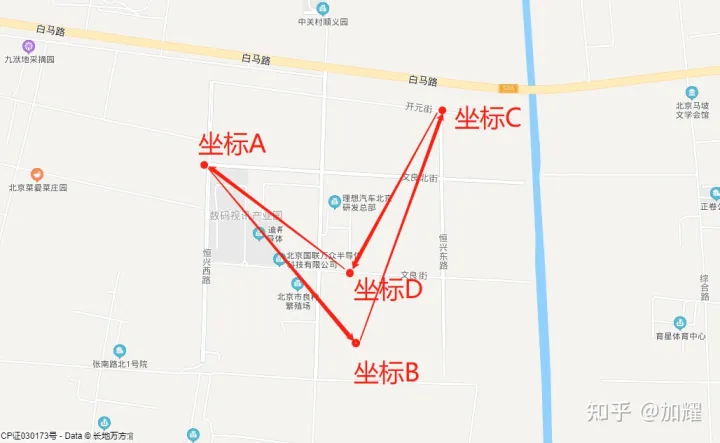
如上图所示,构建一个凹形的多边形,构建出一个区域,这个时候看看ES的查询结果是否和预期一致;其四个坐标如下
坐标点A:(116.577188,40.178012)
坐标点B:(116.586315,40.169329)
坐标点C:(116.591813,40.178288)
坐标点D:(116.587105,40.171975)
所构建的DSL语句
GET location/_search
{
"query": {
"geo_polygon": {
"locationStr": {
"points": [
"40.178012,116.577188",
"40.169329, 116.586315",
"40.178288, 116.591813",
"40.171975,116.587105"
]
}
}
}
}
执行结果

可以看到,在这种复杂的空间地理情况下,ES也可以很好的支持,所执行结果和预期一致;
比较重要的点,坐标是有顺序的,不能随意颠倒,不然构建的空间和预期的就不一致了;
我们看看在上面所构建的三角形区域的DSL语法的ES执行计划
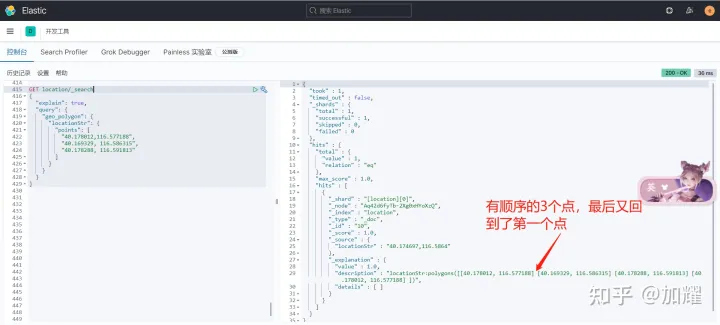
最新文章
- Unity 小问题
- dedecms /member/flink_main.php SQL Injection Vul
- Acronis True Image Home 2011 PXE服务器配置_qxxz_新浪博客
- jquery ajax 实例
- 153. Find Minimum in Rotated Sorted Array
- oracle 10G以上版本 树形查询新加的几个功能
- libnet发包例子(tcp udp arp广播)
- Practical Common Lisp
- Python----文件的IO操作
- java基础之路(一)
- Eclipse插件的各种安装方法
- mongo分布式集群搭建手记
- vue-router动态路由 刷新页面 静态资源没有加载的原因
- SSM框架整合(Spring+SpringMVC+MyBatis+Oracle)
- Asp.net MVC通过自定义特性实现Action日志记录
- Nginx实现数据库端口转发
- wmiprvse.exe cpu占用高怎么解决
- MySQL存储引擎之Myisam和Innodb总结性梳理-转
- 【JAVA】猜数字
- Loading Xps from MemoryStream
热门文章
- 嵌入式-C语言基础:怎么样使得一个指针指向固定的区域?
- 使用 Spring Cloud LoadBalancer 实现客户端负载均衡
- vivo霍金实验平台设计与实践-平台产品系列02
- C温故补缺(十五):栈帧
- WINDOWS下对NIGNX日志文件进行限制
- springboot接收前端传参的几种方式
- easui 两个combobox相互选中时至对方为空的解决方案
- Jmeter启动报错: ANOMALY: use of REX.w is meaningless (default operand size is 64), Unrecognized option: --add-opens
- ArcGIS QGIS学习二:图层如何只显示需要的部分几何面数据(附最新坐标边界下载全国省市区县乡镇)
- 使用 Rainbond 搭建本地开发环境