读论文SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution
Learning a Deep Convolutional Network for Image Super-Resolution
SRCNN是深度学习应用于SR领域的开山之作。
Pytorch代码 与论文的细节设置有些不同。
实验细节总结:
1 数据集
set5:5张图片
set14:14张图片
用到的数据集为set5、set14、ImageNet。
其中,为和之前其他的方法保持相同的条件,先用91张图片作为训练集,set5、set14作为测试集,其中set5的5张图片用作x2x3x4的测试集,set14的14张图片用作x3的测试集。得出的模型效果比之前其他的方法更好。随后用ImageNet的大数据量训练(网络的参数发生了一些改变),得出训练数据集的增加,会给结果带来更好效果,同时训练时间和推理时间也会增加。
在文章的4 Experiments中,描述如下,
Datasets. For a fair comparison with traditional example-based methods, we use the same training set, test sets, and protocols as in [20].
Specifically, the training set consists of 91 images.
The Set5 [2] (5 images) is used to evaluate the performance of upscaling factors 2, 3, and 4, and Set14 [28] (14 images) is used to evaluate the upscaling factor 3.
In addition to the 91-image training set, we also investigate a larger training set in Section 5.2.
具体来说,训练集包含91张图片。set5的五张图片用来估计模型在上采样x2,x3,x4时的表现,set14用来估计模型在上采样x3的表现。除了91张图片之外,在5.2节也用了大数据集训练。
值得注意的是,文章中提出了sub-images(即子图)的概念。
在训练阶段,地面真实图像{Xi}是从训练图像中随机裁剪出来的32张32×32像素的子图像。我们所说的“子图像”是指这些样本被视为小的“图像”而不是“补丁”,在这个意义上,“补丁”是重叠的,需要一些平均作为后处理,但“子图像”不需要。为了合成低分辨率样本{Yi},我们用适当的高斯核模糊子图像,用放大因子进行子采样,并通过双边插值对相同的因子进行放大。这91张训练图像提供了大约24,800张子图像。子图像从原始图像中提取,步幅为14。我们尝试了较小的进步,但没有观察到显著的性能改善。从我们的观察来看,训练集足以训练所提出的深度网络。
2 实验流程
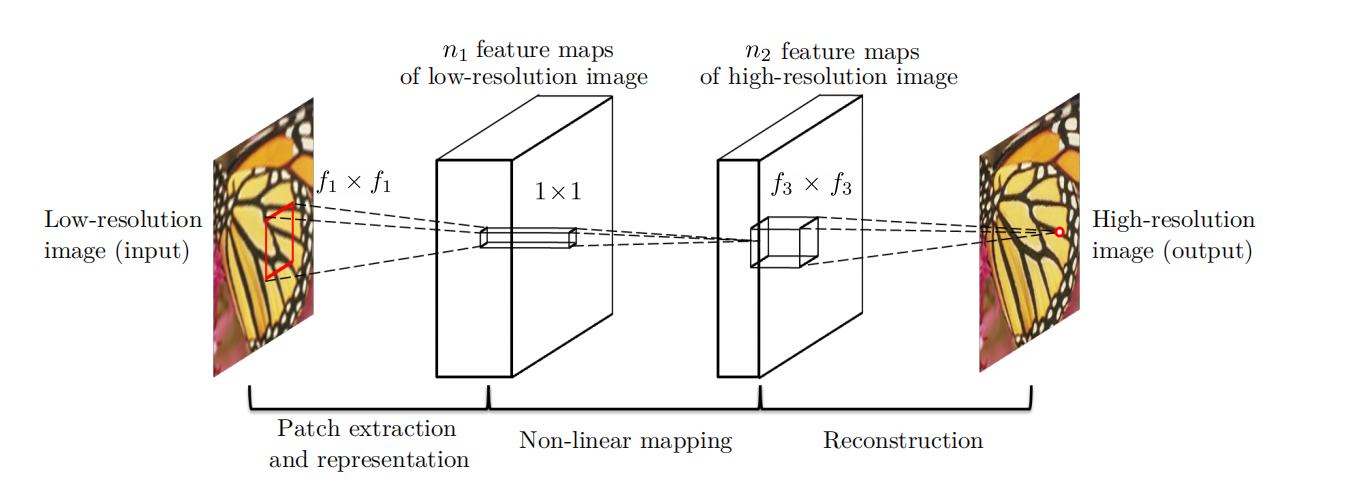
输入为32x32像素的子图sub-image,经过三层卷积,得到输出。
提前对输入input进行了双三次插值,所以网络的输入和输出是相同大小的。
第一层卷积的参数为:(kernel size)9x9,(input channel)1,(outputchannel)64
第二层卷积的参数为:1x1,64,32
第三层卷积的参数为:5x5,32,1
至于为什么第一层网络中输入通道为1,文章中这样说是为了和之前的方法进行对比,所以采用相同的通道数。
在[20]之后,我们在实验中只考虑亮度通道(在YCrCb颜色空间中),所以在第一/最后一层考虑c=1。
这两个色度通道仅为显示的目的而进行双边上采样,而不是用于训练/测试。
请注意,我们的方法可以通过设置c=3来扩展到直接的彩色图像训练。
我们使用c=1主要是为了与以前的方法进行公平的比较,因为大多数方法只涉及亮度通道。
步长s=1;训练时为避免边缘效应,无padding;测试时为保持和input image相同的大小,padding填充0。
所以,训练时的网络输出为20x20像素的子图。因为损失函数为MSE损失函数,所以调整损失函数为仅通过Xi(input image)的中心20×20与网络输出之间的差异来评估。
为了解决边界效应,在每个卷积层中,每个像素的输出(在ReLU之前)被有效输入像素的数量归一化,这可以预先计算。(ReLu激活之前归一化输入像素)
卷积核(kernel or filter)初始化为从一个均值为0,标准差为0.001(偏差为0)的高斯分布中随机抽取来初始化。
前两层的学习率为 \(10^{-4}\) ,最后一层的学习率为 \(10^{-5}\).作者通过经验发现,在最后一层的一个较小的学习速率对网络的收敛是很重要的(类似于去噪的情况[12])。
优化方式为普通的梯度下降SGD。
文章中没写epoch,batch-size。只写了训练 \(8 \times 10^8\) 个反向传播需要三天时间。
网络结构:
3 损失函数:MSE损失函数
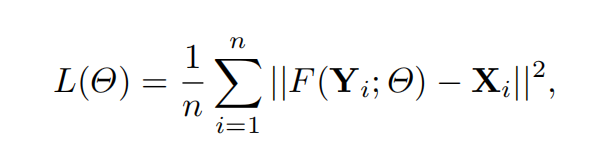
其中,n为像素点的个数,F为网络的输出,X为网络的输入,i表示第i个图像。其中,训练集和测试集的计算方式有区别。
4 实验结果
表一 在set5数据集上的PSNR(dB)和测试时间(sec,秒)
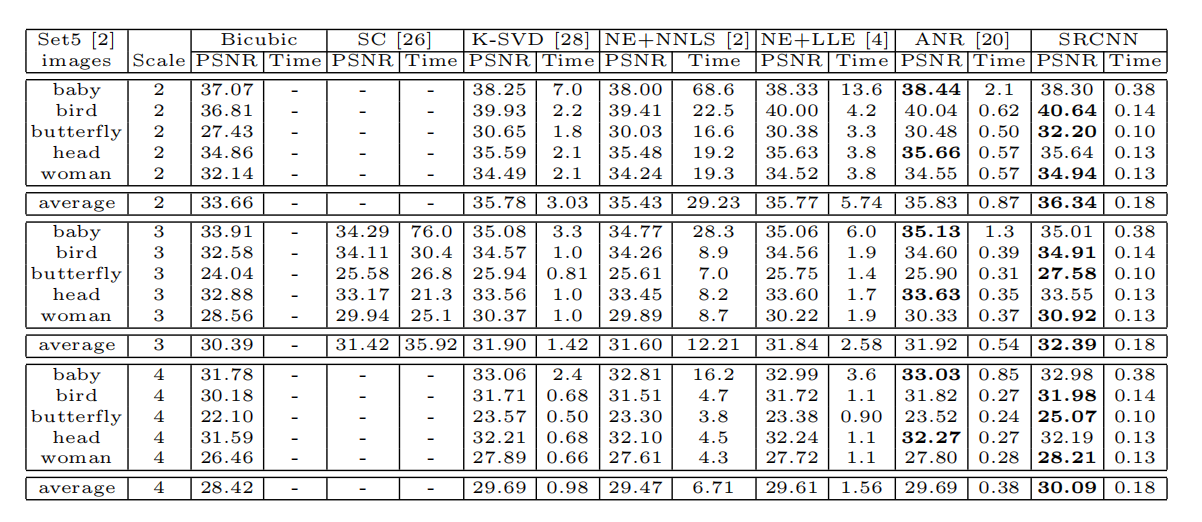
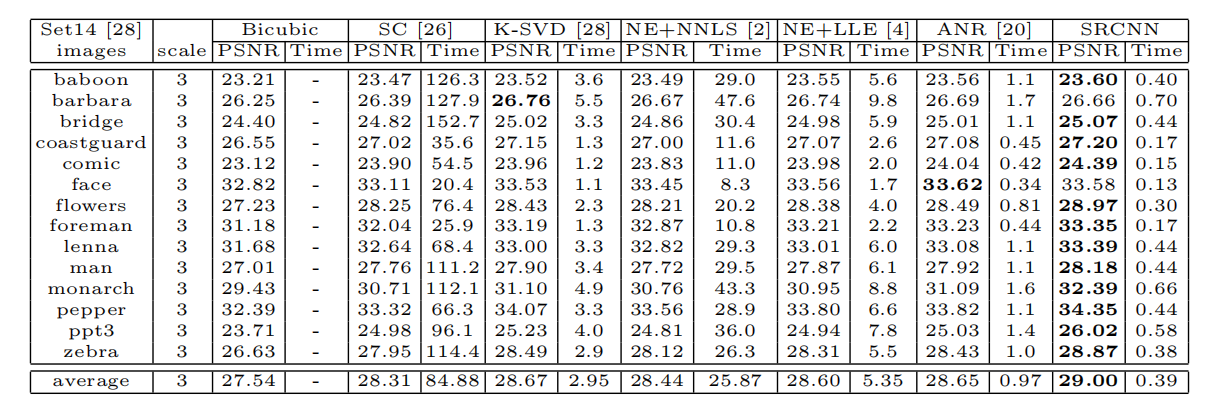
表2 set14数据集上的PSNR(dB)和测试时间(sec)
5 实验配置
GTX 770 GPU
c++
IntelCPU3.10 GHz
16GB内存
最新文章
- 转载:jQuery实现返回顶部功能
- IOS开发——使用数据库
- 调试SQLSERVER (二)使用Windbg调试SQLSERVER的环境设置
- Kinect for Windows SDK 1.8的改进及新特性
- PS网页设计教程XXVII——设计一个大胆和充满活力的作品集
- 5 个最受人喜爱的开源 Django 包
- Verify an App Store Transaction Receipt 【苹果服务端 验证一个应用程序商店交易收据有效性】
- NLog使用总结
- MXNet在64位Win7下的编译安装
- 过度补脑系列:Nokia的不归路
- 【1414软工助教】团队作业4——第一次项目冲刺(Alpha版本) 得分榜
- day7、用户登陆出现-bash-4.1$错误的原因
- Luogu 3384 【模板】树链剖分
- Android 性能优化之工具和优化点总结
- svn与cvs的一些比较
- qmp的简单使用
- 第88讲:Scala中使用For表达式实现map、flatMap、filter
- HTML5 拖拽实现
- python 读取csv文件
- T分布(T-Distribution)