Mysql数据库简单常用语句
2024-10-20 18:57:47
Mysql数据库简单常用语句
1、命令连接数据库
mysql -h 127.0.0.1 -u root -p
2、新增用户
GRANT SELECT on 数据库.* to 用户名@登录主机 identified by "密码";
3、创建数据库
CREATE DATABASE databaseName;
4、使用数据库
USE databaseName;
5、删除数据库
DROP DATABASE databaseName;
6、创建表
CREATE TABLE person(
id int(10) not null auto_increment UNIQUE,
name varchar(25),
age int(10));
7、查看表结构
DESC person;
8、插入数据
INSERT INTO person(name,age) VALUES('张三',30);
9、批量插入数据
INSERT INTO person VALUES(3,'李5',30),(4,'李6',30),(5,'李7',30);
10、删除数据
DELETE FROM person where id=4;
11、修改数据
UPDATE person SET age=50 WHERE name='李7';
12、查询数据
SELECT * FROM person WHERE id=5 AND name='李7';
13、升序排序
SELECT * FROM person ORDER BY age;
默认升序ASC可以省略。
14、降序排序
SELECT * FROM person ORDER BY age DESC;
降序必须写上DESC。
15、数据分组
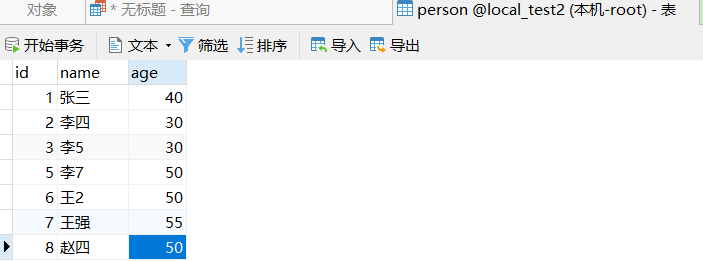
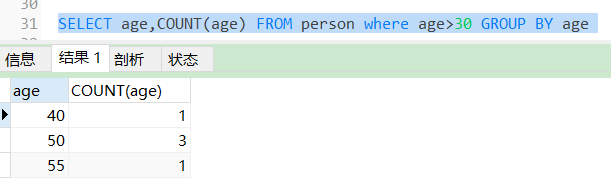
SELECT age,COUNT(age) FROM person where age>30 GROUP BY age;
查询出年龄大于30岁的人数有还有哪些年龄段,并统计出来各个年龄段的人数个数。
16、分组条件查询
SELECT age,COUNT(age) FROM person where age>30 GROUP BY age HAVING COUNT(age)>2;
查询出年龄大于30岁的人数有还有哪些年龄段,并统计出来各个年龄段的人数个数,最后筛选出来年龄段的人数大于2人的年龄段人数信息。
HAVING 是用来设置分组条件的条件表达式,用来分组查询后指定一些条件来输出查询结果。
WHERE 语句在聚合前先筛选记录,也就是说作用在GROUP BY和HAVING字句前,而HAVING子句在聚合后对组记录进行筛选,HAVING只能用于GROUP BY。
WHERE 用于过滤数据行,而 HAVING用于过滤分组。
WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤。
WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名。

17、限制查询数量LIMIT
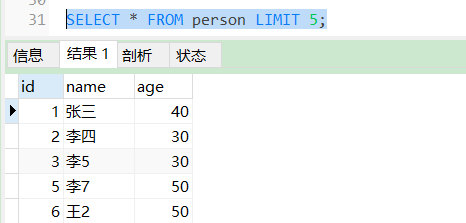
SELECT * FROM user LIMIT 5;
检索前5行记录,只给一个参数,它表示返回最大的记录行数目。
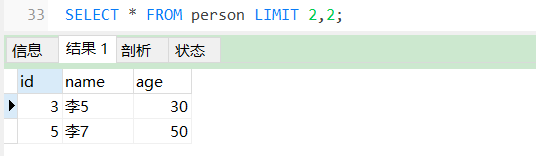
SELECT * FROM person LIMIT 2,2;
从第2条数据开始,检索出2条数据。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
初始记录行的偏移量是从0开始(不是 1)。
18、添加字段
ALTER TABLE person add phoneNumber varchar(25) not Null;

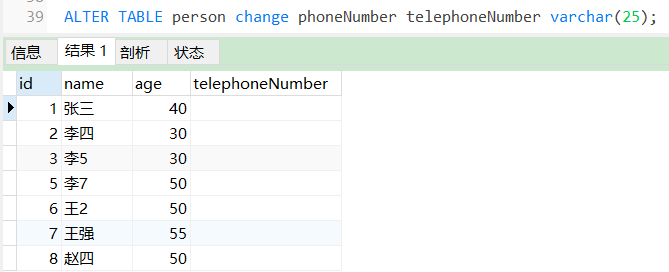
19、重命名字段
ALTER TABLE person change phoneNumber telephoneNumber varchar(25);
20、条件查询过滤
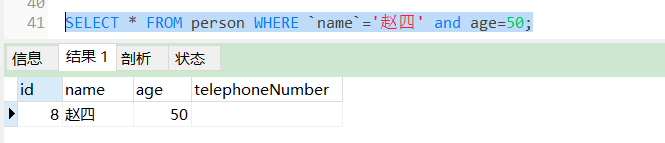
(1)AND(与查询)
用AND进行查询的时候,查询出来的数据要求条件都得满足。
SELECT * FROM person WHERE `name`='赵四' and age=50;
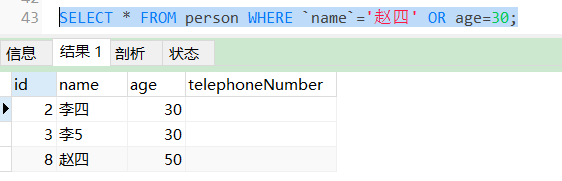
(2)OR(或查询)
用OR进行查询的时候,查询出来的数据只要求满足其中任意一个条件就可以查询出来。
SELECT * FROM person WHERE `name`='赵四' OR age=30;
查询出来名字是‘赵四’的,或者age在30岁的所有人信息。
(3)IN(在给定范围内)
用IN进行查询的时候,查询出来的数据在这个IN后边括号里边给定的值当中。
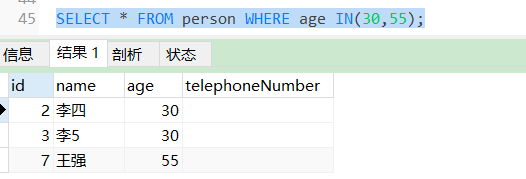
SELECT * FROM person WHERE age IN(30,55);
只查询出来年龄是30岁和55岁的人数信息。
(4)NOT IN(不在范围内)
用NOT IN进行查询的时候,查询出来的数据不在这个给定的范围内。
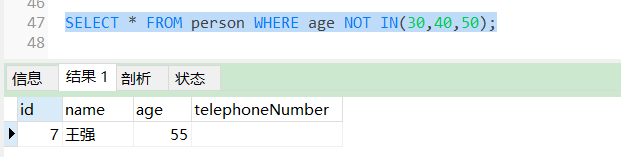
SELECT * FROM person WHERE age NOT IN(30,40,50);
查询出来所有年龄不是30岁,40岁,50岁的人。
(5)IS(为空)
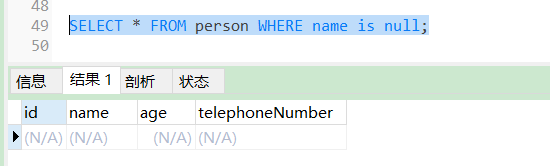
用IS NULL进行查询的时候,是用来查询某字段为空时用is null,而不能使用"=null",因为mysql中的null不等于任何其他值,也不等于另外一个null。
优化器会把"=null"的查询过滤掉而不返回任何数据,查询某字段为非空时使用is not null。
SELECT * FROM person WHERE name is null;
21、模糊查询LIKE
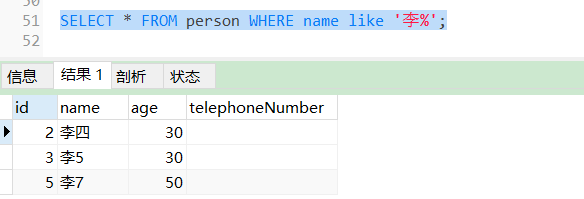
(1)LIKE '李%'
使用LIKE查询该字段以“李”姓开头的数据。
SELECT * FROM person WHERE name like '李%';
(2)LIKE '%明'
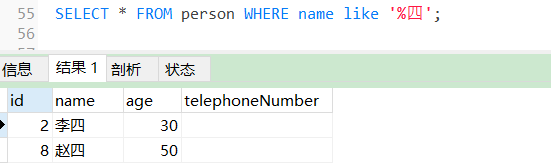
使用LIKE查询该字段以“四”结尾的数据。
SELECT * FROM person WHERE name like '%四';
(3)LIKE '%明%'
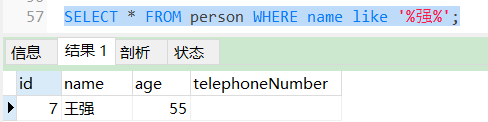
使用LIKE查询该字段包含“强”的数据。
SELECT * FROM person WHERE name like '%强%';
22、字段控制查询过滤
(1)DISTINCT
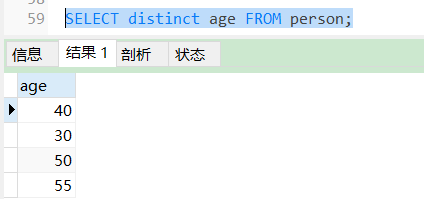
去除重复的数据。
SELECT distinct age FROM person;
(2)AS
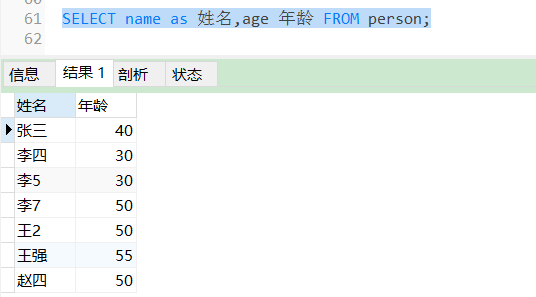
可以设置列的别名、也可以省略AS来设置关键字。
SELECT name as 姓名,age 年龄 FROM person;
23、聚合函数
(1)AVG()函数
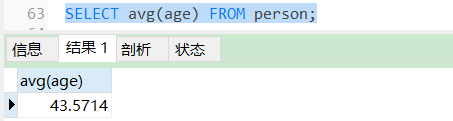
AVG函数是用来计算某一列的平均值,比如可以用在计算平均薪资、平均年龄等。
SELECT avg(age) FROM person;
(2)COUNT()函数
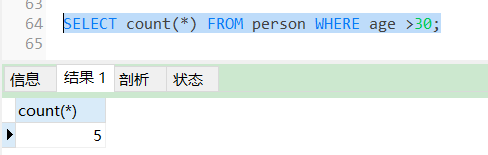
COUNT()聚合函数是用来统计表中记录的个数或者列中值的总个数,计算内容由SELECT语句指定,例如要获取person表中age > 30岁的人数。
SELECT count(*) FROM person WHERE age >30;
(3)MAX()/MIN()函数
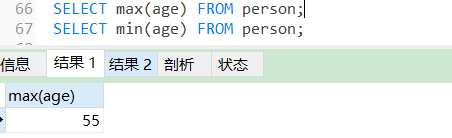
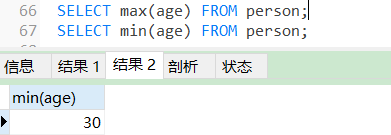
MAX()聚合函数选取最大值,MIN()聚合函数选取最小值。
SELECT max(age) FROM person;
SELECT min(age) FROM person;
(4)SUM()函数
SUM()聚合函数用来计算满足条件的某一列的总和。
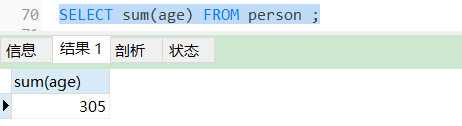
SELECT sum(age) FROM person ;
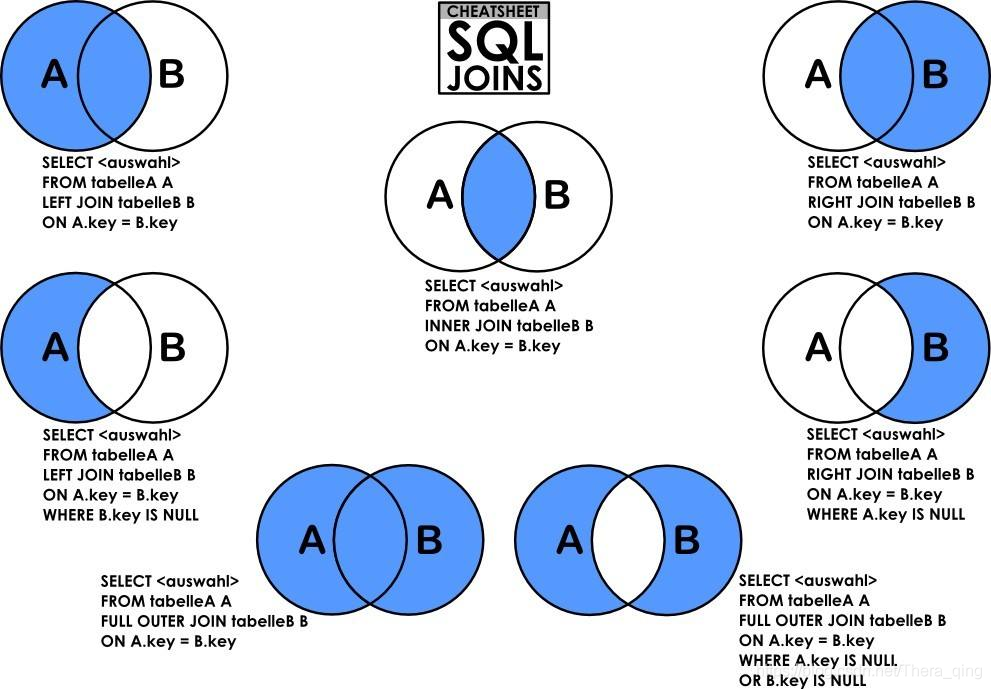
24、表连接查询
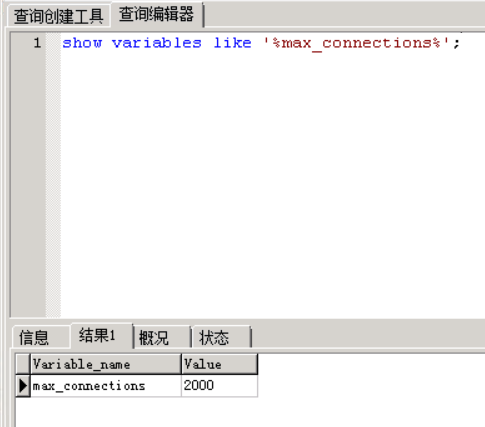
25、修改最大连接数
show variables like '%max_connections%';
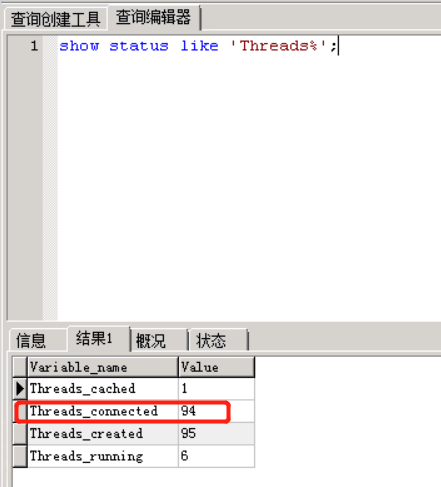
show status like 'Threads%';
set global max_connections=1000;
最新文章
- J2EE版本
- android学习笔记15——Galley
- poj 2299 求逆序数
- matlab中 hold on 与hold off的用法
- 更好的使用chrome
- [置顶] ※数据结构※→☆非线性结构(tree)☆============树结点 链式存储结构(tree node list)(十四)
- js使用栈来实现10进制转8进制 js取除数 余数
- 观察者模式(Observer)发布、订阅模式
- Activiti工作流几种驳回方式的实现与比较
- init,initialize,initWithFrame,initWithCoder,awakeFromNib等区别
- iframe中的a标签电话链接不能正常打开
- RN 的页面布局
- 菜鸟教程之学习Shell script笔记(上)
- php配置文件php.ini的详细解析(续)
- 那些令人迷惑的名词:切图/H5/XML/REST
- spark 运行架构
- Spring中的destroy-method方法
- webpack进阶--打包
- Tomcat8.5 升级tomcat版本导致出现异常,Base64不存在
- Java远程调试 java -Xdebug各参数说明