ElasticSearch基本简介(一)
一、ES简介
1,什么是ES
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式的全文搜索引擎,其对外服务是基于RESTful web接口发布的。Elasticsearch是用Java开发的应用,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
2,ES的相关概念
a)cluster
cluster集群。ElasticSearch集群由一或多个节点组成,其中有一个主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ElasticSearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部看ElasticSearch集群,在逻辑上是个整体,你与集群中的任何一个节点通信和与整个ElasticSearch集群通信是等价的。也就是说,主节点的存在不会产生单点安全隐患、并发访问瓶颈等问题。
b)shards
primary shard:代表索引的主分片,ElasticSearch可以把一个完整的索引分成多个primary shard,这样的好处是可以把一个大的索引拆分成多个分片,分布存储在不同的ElasticSearch节点上,从而形成分布式存储,并为搜索访问提供分布式服务,提高并发处理能力。primary shard的数量只能在索引创建时指定,并且索引创建后不能再更改primary shard数量(重新分片需要重新定义分片规则)。es5.x之后默认为5,es7.x默认为1。
c)replicas
replica shard:代表索引主分片的副本,ElasticSearch可以设置多个replica shard。replica shard的作用:一是提高系统的容错性,当某个节点某个primary shard损坏或丢失时可以从副本中恢复。二是提高ElasticSearch的查询效率,ElasticSearch会自动对搜索请求进行负载均衡,将并发的搜索请求发送给合适的节点,增强并发处理能力。可取值为0~n,默认为1。
d)Index
索引。相当于关系型数据库中的表。其中存储若干相似结构的Document数据。如:客户索引,订单索引,商品索引等。ElasticSearch中的索引不像数据库表格一样有强制的数据结构约束,在理论上,可以存储任意结构的数据。但了为更好的为业务提供搜索数据支撑,还是要设计合适的索引体系来存储不同的数据。
e)Type
类型。每个索引中都必须有唯一的一个Type,Type是Index中的一个逻辑分类。ElasticSearch中的数据Document是存储在索引下的Type中的。
注意:ElasticSearch5.x及更低版本中,一个Index中可以有多个Type。ElasticSearch6.x版本之后,type概念被弱化,一个index中只能有唯一的一个type。且在7.x版本之后,删除type定义。
f)Document
文档。ElasticSearch中的最小数据单元。一个Document就是一条数据,一般使用JSON数据结构表示。每个Index下的Type中都可以存储多个Document。一个Document中可定义多个field,field就是数据字段。如:学生数据({"name":"张三", "age":20, "gender":"男"})。
g)反向索引(倒排索引)
对数据进行分析,抽取出数据中的词条,以词条作为key,对应数据的存储位置作为value,实现索引的存储。这种索引称为倒排索引。倒排索引是Document写入ElasticSearch时分析维护的。
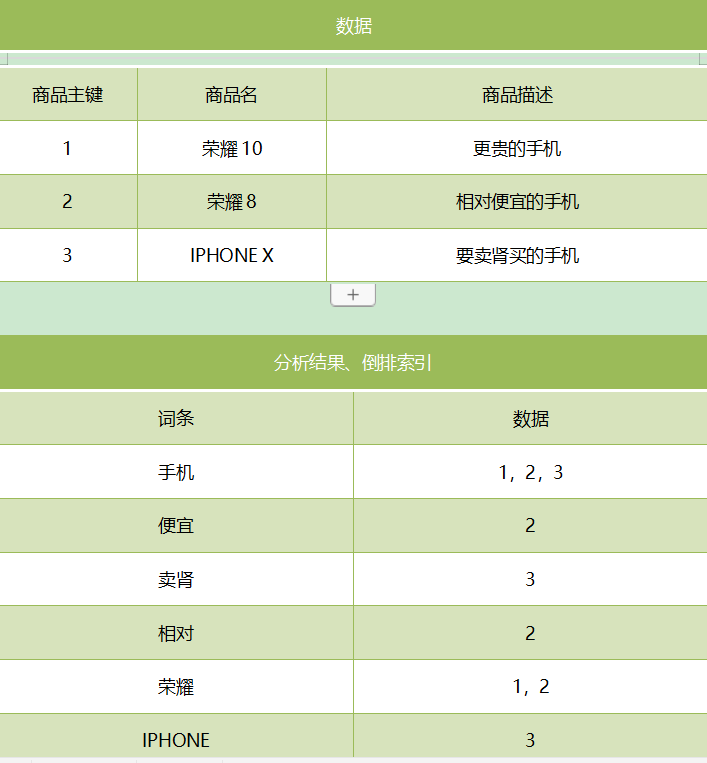
3,比数据库做搜索的优势
- 数据库查询复杂度高。比如:like '%关键字%'不能命中索引,搜索复杂度高
- 数据库关键字的搜索不全面,搜索结果不符合要求。比如:搜索商品为'笔记本电脑',不能搜索到只有'笔记本'或者只有'电脑'的数据
- 数据库搜索的效率问题。数据量越大,查询效率越低。
二、ElasticSearch索引操作
1,查询健康状态
GET _cat/health?v

其中status的状态分为三种:green、yellow和red
- green:每个索引的primary shard和replica shard都是active的
- yellow:每个索引的primary shard都是active的,但部分的replica shard不是active的。比如:当前只有两个node结点,需要创建大于等于两个repica shard副分片,由于主分片和副分片均不能在同一个结点上,所有必定有副分片不能正常的active。
- red:不是所有的索引的primary shard都是active状态的。
#查看健康状态
GET _cat/health?v
#查看节点信息
GET _cat/nodes?v
#查看索引信息
GET _cat/indices?v
#查看分片信息
GET _cat/shards?v
2,创建索引
#创建my_index索引(settings可以省略),创建后shards分片数不能修改,只能修改shards副本数
PUT my_index
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
在ElasticSearch中,默认的创建索引的时候,会分配5个primary shard,并为每个primary shard分配一个replica shard(在ES7版本后,默认创建1个primary shard)。在ElasticSearch中,默认的限制是:如果磁盘空间不足15%的时候,不分配replica shard。如果磁盘空间不足5%的时候,不再分配任何的primary shard。ElasticSearch中对shard的分布是有要求的。ElasticSearch尽可能保证primary shard平均分布在多个节点上。Replica shard会保证不和他备份的那个primary shard分配在同一个节点上。
3,修改索引(副分片数)
#修改索引
PUT my_index/_settings
{
"number_of_replicas": 2
}
注意:索引一旦创建,primary shard数量不可变化,可以改变replica shard数量。
4,删除索引
DELETE my_index
5,查看索引信息
GET _cat/indices?v

三、ElasticSearch中Document相关操作
1,新增Document
在索引中增加文档。在index中增加document。
ElasticSearch有自动识别机制。如果增加的document对应的index不存在,自动创建index;如果index存在,type不存在,则自动创建type。如果index和type都存在,则使用现有的index和type。
a)PUT
PUT 索引名/类型名/唯一ID{字段名:字段值}
#如果当前id已经存在,那么就是修改,如果不存在就是新增
PUT my_index/_doc/1
{
"name":"test_doc_01",
"remark":"first test elastic search",
"order_no":1
}
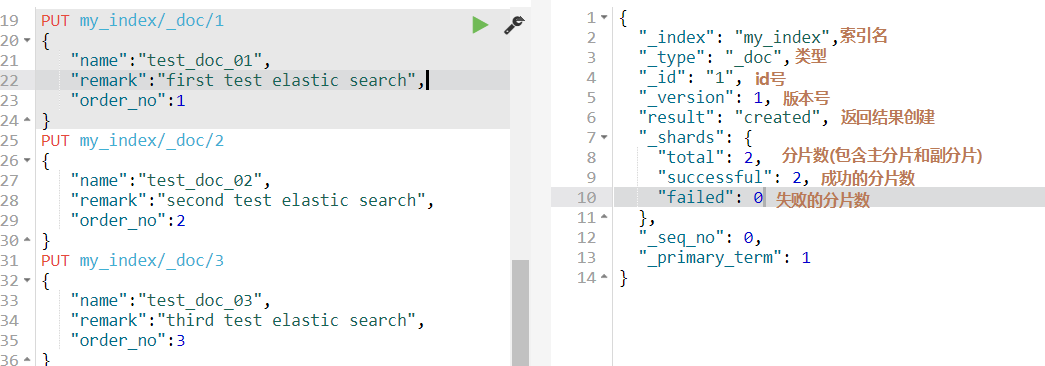
如果当前索引中的document的id已经存在,那么就是修改,如果不存在就是新增。但是如果此时id已经存在,想要强制新增会报错,强制新增的语法为:
PUT 索引名/类型名/唯一ID/_create{字段名:字段值} 或者是 PUT 索引名/类型名/唯一ID?op_type=create{字段名:字段值}
b)POST
此操作为ElasticSearch自动生成id的新增Document方式。此语法格式和PUT请求的数据新增,只有唯一的区别,就是可以自动生成主键id,其他的和PUT请求新增数据完全一致。
POST 索引名/类型名[/唯一ID]{字段名:字段值}
#此时,如果新增时唯一id(2)不存在就是新增,如果唯一id(2)存在就是修改。这个与PUT相同
#可以直接变为没有id,会随机生成一个GUID作为id
POST my_index/_doc
{
"name":"test_doc_02",
"remark":"second test elastic search",
"order_no":2
}
2,查询Document
a)GET 通过ID查询
GET 索引名/类型名/唯一ID
GET my_index/_doc/1
b)GET _mget批量查询
批量查询可以提高查询效率。推荐使用(相对于单数据查询来说)。
#语法
GET 索引名/类型名/_mget
{
"docs" : [
{
"_id" : "唯一ID值"
},
{
"_id" : "唯一ID值"
}
]
}
3,修改Document
a)全量替换(同新增)
PUT|POST 索引名/类型名/唯一ID{字段名:字段值}
本操作相当于覆盖操作。全量替换的过程中,ElasticSearch不会真的修改Document中的数据,而是标记ElasticSearch中原有的Document为deleted状态,再创建一个新的Document来存储数据,当ElasticSearch中的数据量过大时,ElasticSearch后台回收deleted状态的Document。
PUT my_index/_doc/1
{
"name":"test_doc_01111",
"remark":"first 111",
"order_no":1111
}
b)更新Document
POST 索引名/类型名/唯一ID/_update{doc:{字段名:字段值}}
只更新某Document中的部分字段。这种更新方式也是标记原有数据为deleted状态,创建一个新的Document数据,将新的字段和未更新的原有字段组成这个新的Document,并创建。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别。
POST my_index/_doc/1/_update
{
"doc":{
"name":" test_doc_01_for_update"
}
}
4,删除Document
DELETE 索引名/类型名/唯一ID
ElasticSearch中执行删除操作时,ElasticSearch先标记Document为deleted状态,而不是直接物理删除。当ElasticSearch存储空间不足或工作空闲时,才会执行物理删除操作。标记为deleted状态的数据不会被查询搜索到。
DELETE my_index/_doc/2
5,bulk批量增删改
定义:
POST _bulk
{ "action_type" : { "metadata_name" : "metadata_value" } }
{ document datas | action datas }
action_type:
create: 强制创建,相当于PUT 索引名/类型名/唯一ID/_create
index : 普通的PUT操作,相当于创建Document或全量替换
update: 更新操作(partial update),相当于 POST 索引名/类型名/唯一ID/_update
delete: 删除操作
案例:
#如果index和type为同一个可以提出来,此时创建ID为111,覆盖ID为1,修改ID为2,删除ID为3
POST my_index/_doc/_bulk
{"create":{"_id":111}}
{"name":"zs","age":15}
{"index":{"_id":1}}
{"name":"first","sort":1}
{"update":{"_id":2}}
{"doc":{"sort":2}}
{"delete":{"_id":3}}
注意:bulk语法中要求一个完整的json串不能有换行。不同的json串必须使用换行分隔。多个操作中,如果有错误情况,不会影响到其他的操作,只会在批量操作返回结果中标记失败。bulk语法批量操作时,bulk request会一次性加载到内存中,如果请求数据量太大,性能反而下降(内存压力过高),需要反复尝试一个最佳的bulk request size。一般从1000~5000条数据开始尝试,逐渐增加。如果查看bulk request size的话,一般是5~15MB之间为好。
bulk语法要求json格式是为了对内存的方便管理,和尽可能降低内存的压力。如果json格式没有特殊的限制,ElasticSearch在解释bulk请求时,需要对任意格式的json进行解释处理,需要对bulk请求数据做json对象会json array对象的转化,那么内存的占用量至少翻倍,当请求量过大的时候,对内存的压力会直线上升,且需要jvm gc进程对垃圾数据做频繁回收,影响ElasticSearch效率。
生成环境中,bulk api常用。都是使用java代码实现循环操作。一般一次bulk请求,执行一种操作。如:批量新增10000条数据等。
四、ElasticSearch中的mapping
Mapping在ElasticSearch中是非常重要的一个概念。决定了一个index中的field使用什么数据格式存储,使用什么分词器解析,是否有子字段等。
1,mapping的核心数据类型
- 文本(字符串):text
- 整数:byte、short、integer、long
- 浮点型:float、double
- 布尔类型:boolean
- 日期类型:date
- 数组类型:array {a:[]}
- 对象类型:object {a:{}}
- 不分词的字符串(关键字): keyword
2,dynamic mapping自动分配字段类型
- true or false -> boolean
- 123 -> long
- 123.123 -> double
- 2018-01-01 -> date
- hello world -> text
- [] -> array
- {} -> object
在上述的自动mapping字段类型分配的时候,只有text类型的字段需要分词器。默认分词器是standard分词器。
3,查看索引mapping
GET 索引名/_mapping
{
"my_index": { # 索引名
"mappings": { # 映射列表
"my_type": { # 类型名
"properties": { # 字段列表
"age": { # 字段名
"type": "long" # 字段类型
},
"gender": { #字段名
"type": "text", #字段类型
"fields": { # 子字段列表
"keyword": { # 子字段名
"type": "keyword", # 子字段类型,keyword不进行分词处理的文本类型。gender.keyword可以进行排序
"ignore_above": 256 # 子字段存储数据长度
}
}
}
}
}
}
}
}
4,custom mapping
可以通过命令,在创建index和type的时候来定制mapping映射,也就是指定字段的类型和字段数据使用的分词器。
手工定制mapping时,只能新增mapping设置,不能对已有的mapping进行修改。
如:有索引a,其中有类型b,增加字段f1的mapping定义。后续可以增加字段f2的mapping定义,但是不能修改f1字段的mapping定义。
a)创建索引时指定mapping
PUT 索引名称
{
"mappings":{
"类型名称":{
"properties":{
"字段名":{
"type":类型,
["analyer":字段的分词器,]
["fields":{
"子字段名称":{
"type":类型,
"ignore_above":长度限制
}
}]
}
}
}
}
}
例如:
PUT test_index
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"test_type":{
"properties": {
"author_id" : {
"type": "byte",
"index": false
},
"title" : {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword" : {
"type": "keyword",
"ignore_above": 256
}
}
},
"content" : {
"type": "text",
"analyzer": "ik_max_word"
},
"post_date" : {
"type": "date"
}
}
}
}
}
"index" - 是否可以作为搜索索引。可选值:true | false
"analyzer" - 指定分词器。
"type" - 指定字段类型
b)为已有索引添加新的字段mapping
PUT 索引名/_mapping/类型名
{
"properties":{
"新字段名":{
"type":类型,
"analyer":字段的分词器,
"fields":{
"子字段名":{
"type":类型,
"ignore_above":长度
}
}
}
}
例如:
PUT /test_index/_mapping/test_type
{
"properties" : {
"new_field" : { "type" : "text" , "analyzer" : "standard" }
}
}
c)测试不同的字段分词器
GET 索引名称/_analyze
{
"field":"索引中的text类型的字段名",
"text":"要分词处理的文本数据"
}
例如:
#测试content字段的分词效果
GET test_index/_analyze
{
"field": "content",
"text": "我是一个程序员"
}
最新文章
- Python的方法解析顺序(MRO)
- 一个3D ar打飞机的游戏iOS源码
- PHP function
- hexo deploy出错的解决方法
- $ajax引用DOM
- Logical Databases逻辑数据库
- CodeSmith 7.01破解下载
- j2ee中如何拦截jsp页面?
- FindBugs的Eclipse插件安装与使用
- strcmp和==比较
- 重构ConditionHelper
- css修改滚动条默认样式
- Kafka学习-复制
- 1.Java 加解密技术系列之 BASE64
- Android Studio帮助文档的安装及智能提示设置
- 一款堪称完美的编程字体Source Code Pro
- IntelliJ IDEA 关闭多余项目
- SpringBoot文件上传
- Confluence 6 服务器硬件要求指南
- Sublime Text3—Project(项目管理)