数据流分析软件SQLFlow的工作原理
2024-10-20 16:37:34
SQLFlow是一个可视化的在线处理SQL对象依赖关系的工具,只需要上传你的SQL脚本,它可以自动分析SQL里的数据对象,包括database、schema、table、view、column、procedure、function、trigger等等,并且能够分析这些数据对象之间的依赖关系,并将这些依赖关系可视化展现出来。本文将描述SQLFlow的工作原理。
SQLFlow底层主要是依赖GSP Parser来完成SQL的处理,按照处理顺序从前到后依次为: 数据源连接、Metadata数据导出、SQLEnv初始化、SQL语法解析、SQL语法分析、DataFlow关系分析、DataFlow序列化输出。
考虑下面这个SQL:
CREATE TABLE tmp.tmp_a_supp_achievement_an_mom_001 AS
SELECT a1.dim_day_txdate,
a.a_pin,
Sum(Coalesce(b.amount, 0)) AS total_amount
, Sum(Coalesce(c.refund_amt, 0)) AS refund_amt
, Sum(os_prcp_amt) os_prcp_amt
FROM (SELECT dim_day_txdate
FROM dmv.dim_day
WHERE dim_day_txdate>=concat(cast(Year('2018-05-15')-1 AS string),'-', substring('2018-05-15', 6, 2), '-01')
AND dim_day_txdate<='2018-05-15' )a1
JOIN (SELECT DISTINCT a_pin, product_type
FROM dwd.dwd_as_qy_cust_account_s_d
WHERE dt ='2018-05-15' AND product_type='20288' )a
LEFT OUTER JOIN (SELECT substring(tx_time, 1, 10) AS time, sum(order_amt) AS amount, a_pin
FROM dwd.dwd_actv_as_qy_iou_receipt_s_d
WHERE a_order_type='20096' AND a_pin NOT IN ('vep_test', 'VOPVSP测试')
AND dt='2018-05-15'
GROUP BY substring(tx_time, 1, 10), a_pin )b
ON cast(a.a_pin AS string)=cast(b.a_pin AS string) AND a1.dim_day_txdate=b.time
LEFT OUTER JOIN ( SELECT substring(refund_time, 1, 10) AS refund_time, a_pin, sum(refund_amt)AS refund_amt
FROM dwd.dwd_as_qy_iou_refund_s_d
WHERE refund_status='20090' AND dt='2018-05-15' AND a_order_no <> '12467657248'
AND a_refund_no <> '1610230919767139947'
GROUP BY substring(refund_time, 1, 10), a_pin )c
ON cast(a.a_pin AS string)=cast(c.a_pin AS string) AND a1.dim_day_txdate=c.refund_time
LEFT OUTER JOIN (SELECT dt, a_pin, sum(os_prcp_amt) AS os_prcp_amt
FROM dwd.dwd_as_qy_cycle_detail_s_d
WHERE dt>=concat(substr('2018-05-15', 1, 7), '-01') AND dt<='2018-05-15'
GROUP BY dt, a_pin)e
ON cast(a.jd_pin AS string)=cast(e.a_pin AS string) AND a1.dim_day_txdate=e.dt
GROUP BY a1.dim_day_txdate, a.a_pin;
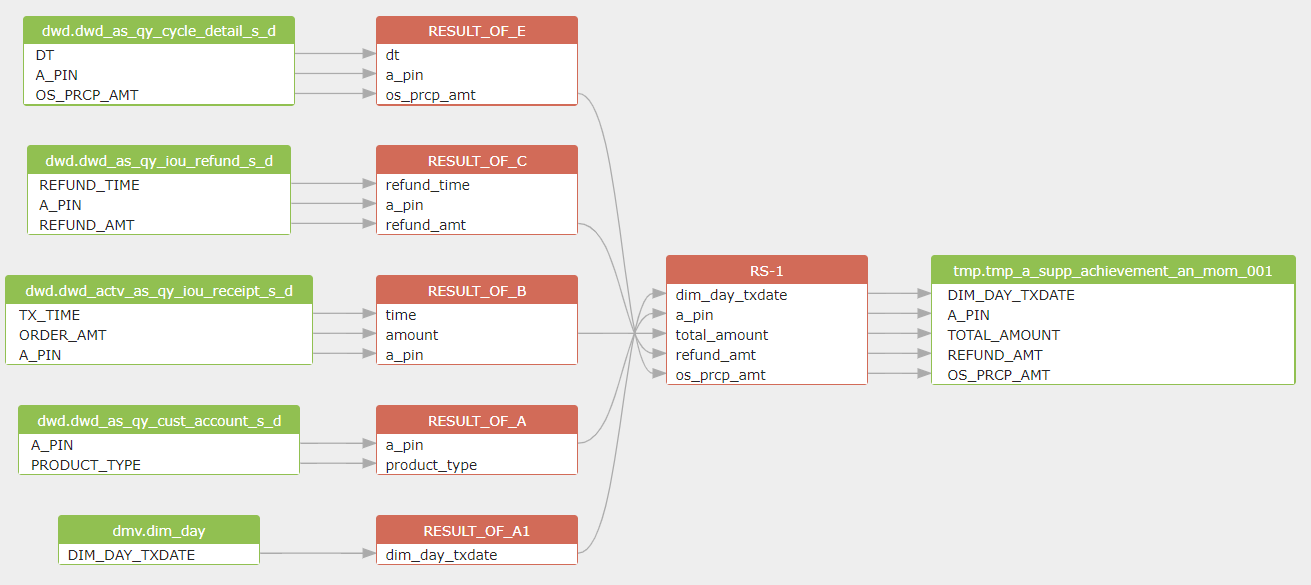
可以看到,Table tmp.tmp_a_supp_achievement_an_mom_001 的创建依赖一个子查询语句,而子查询的结果集中包含了function,并且子查询的from table,又包含了一个复杂的子查询语句,并且还有join依赖关系,join中也有一个子查询语句。因此这是一个多层子查询的嵌套语句。
因此,我们可以分析得出,在处理SQL依赖关系的时候,需要建立一个stack,进行深度遍历,一层层的分析SQL依赖关系,最后出栈的时候,再将各层依赖关系连接起来,形成一个依赖关系调用链。
实际上的分析过程是,优先分析SQL中的Table,看其是否有子查询,如果有则继续向下继续分析子查询。然后再分析查询结果集,将结果集中的字段和Table字段一一关联起来。如果结果集中包含Function,还需要对Function进行进一步的解析,形成Function和内部字段的依赖关系。
SQLFlow官方入口: https://sqlflow.gudusoft.com
最新文章
- AFNetWorking https请求 SSL认证 自制证书
- iOS 图片选择器 总结
- JavaScript中以一个方法作为参数的写法
- MySQL创建数据库和表的Demo
- .Net简单图片系统-简介
- ECharts使用心得总结(二)
- 清理无用的CSS样式的几个工具(转)
- Java中的接口与抽象类
- Osmocom-BB中cell_log的多种使用姿势
- HDU 4540 威威猫系列故事——打地鼠
- android 多线程数据库读写分析与优化
- CentOs Linux 分区建议
- 记一次lnmp环境下无法执行php文件
- 阿里云Ubuntu部署java web(2) - 配置tomcat
- CSDN泄漏数据完整分析
- android正则表达式隐藏邮箱地址中间字符
- 章节十、8-XPath---如何构建有效的XPath
- Clion 配置
- php上传文件配置
- 多线程.Thread.Sleep方法