JavaScript学习(一)——引擎,运行时,调用堆栈
JavaScript引擎
谷歌 V8 引擎是流行的 JavaScript 引擎之一。V8 引擎在诸如 Chrome 和 Node.js 内部使用。
引擎包括两个主要组件:
- 动态内存管理 – 在这里分配内存
- 调用栈 – 这里代码执行 即 堆栈结构
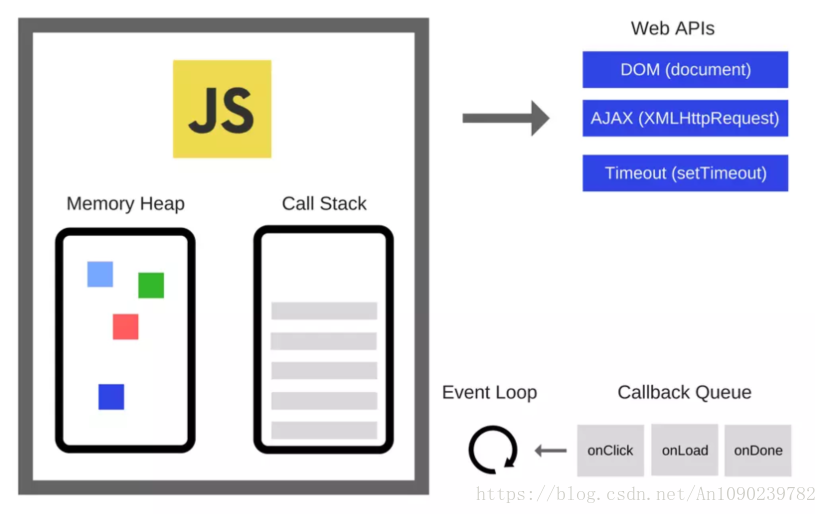
运行时
除了引擎,实际上还有更多其它方面的东西。有被称为 Web API 的东西,这些 Web API 是由浏览器提供的,比如 DOM,AJAX,setTimeout 以及其它。
于是,就有了流行的事件循环和回调队列。
调用栈
JavaScript 只是一个单线程的编程语言,这意味着它只有一个调用栈。这样它只能一次做一件事情。
调用栈是一种数据结构,里面会记录我们在程序中的大概位置。当执行进入一个函数,把它置于栈的顶部。如果从函数中返回则从栈顶部移除函数。这就是调用栈所能够做的事情。
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);当引擎开始执行这段代码的时候,调用栈会被清空。之后,产生如下步骤:
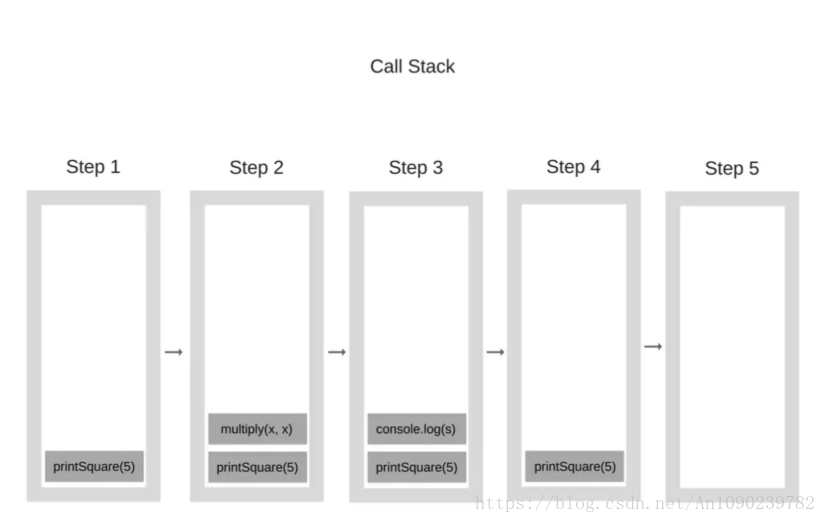
调用栈中的每个入口被称为堆栈结构。
当抛出异常的时候这正好是堆栈追踪是如何被构造出来的-当发生异常的时候这基本上是调用栈的状态。看下如下代码:
function foo() {
throw new Error('SessionStack will help you resolve crashes:)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();如果在 Chrome 中执行(假设代码在 foo.js 的文件中),将会产生如下的堆栈追踪:

“堆栈溢出”-当你达到最大调用栈大小的时候发生。这种情况相当容易发生,特别是当你使用递归而没有仔细地检查代码的时候。查看下如下代码:
function foo() {
foo();
}
foo();当引擎开始执行这段代码的时候,它开始调用 foo 函数。这个函数,然而,会递归并开始调用其自身而没有任何结束条件。所以在每步执行过程中,调用堆栈会反复地添加同样的函数。执行过程如下所示:
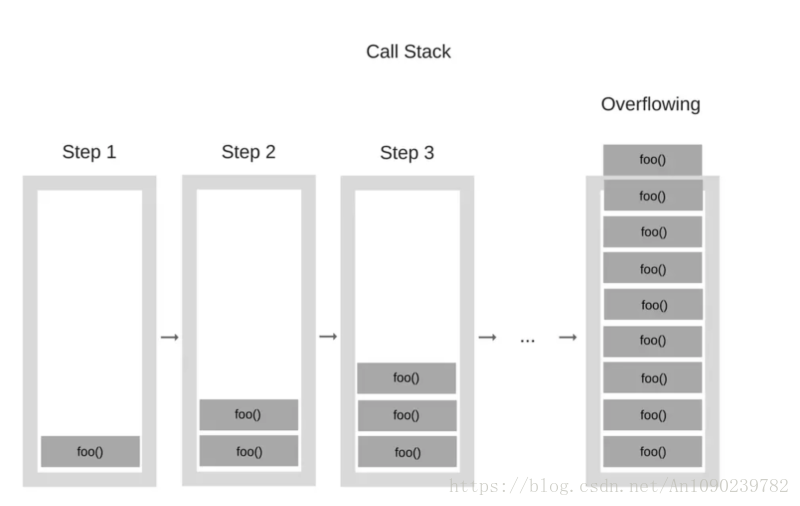
在某一时刻,然而,调用堆栈中的函数调用次数超过了调用堆栈的实际大小,这样浏览器决定抛出错误的动作,如下所示:

并发和事件循环
一旦浏览器开始在调用栈中执行如此多的任务,浏览器将会在相当一段时间内停止交互。大多数浏览器会抛出一个错误,询问你是否关闭网页。
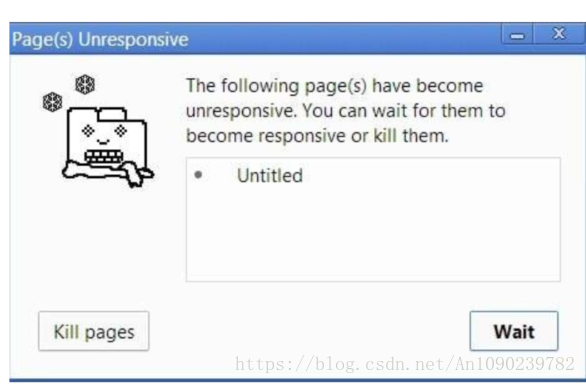
如何不阻塞 UI 且不让浏览器停止响应来执行运行缓慢的代码呢?使用异步回调。
转载:
作者:tristan
链接:https://juejin.im/post/5ae09017f265da0b8f623aa3
最新文章
- Qemu+gdb跟踪内核源码
- GitHub--git push出错解决
- HDU5764 After a Sleepless Night 树形乱搞题
- css实现网页布局随滚轮变化响应移动
- (6/18)重学Standford_iOS7开发_控制器多态性、导航控制器、选项卡栏控制器_课程笔记
- 226. Invert Binary Tree(C++)
- extjs底层源码实现继承分析
- 学习HTML5的第二周
- 初次就这么给了你(Django-rest-framework)
- 关于主机用户名显示为"-bash-4.1$"
- java.lang.NumberFormatException: For input string: " "
- 剑指Offer——如何做好自我介绍(英文版)
- .NET Core微服务之基于Ocelot实现API网关服务(续)
- ORA-04030: out of process memory when trying to allocate 152 bytes (Logminer LCR c,krvtadc)
- 配置合适的Visual Studio 2017 开发环境(其它版本的也适用)
- HaProxy 负载均衡集群
- 常用linux命令(项目部署)
- 判断js数组包是否包含某个元素
- django2.1---admin 修改模块的名字为中文显示
- CentOS Docker环境搭建教程