修改ES分片规则
转自:http://my.oschina.net/crxy/blog/422287?p=1
Es查询的时候默认是随机从一些分片中查询数据,可以通过配置让es从某些分片中查询数据
1:_local
指查询操作会优先在本地节点有的分片中查询,没有的话再在其它节点查询。
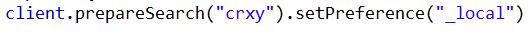
2:_primary:指查询只在主分片中查询
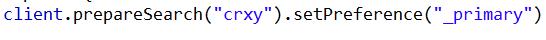
3:_primary_first:指查询会先在主分片中查询,如果主分片找不到(挂了),就会在副本中查询。
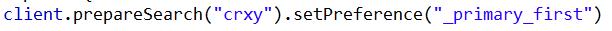
4:_only_node:指在指定id的节点里面进行查询,如果该节点只有要查询索引的部分分片,就只在这部分分片中查找,所以查询结果可能不完整。如_only_node:123在节点id为123的节点中查询。

5:_prefer_node:nodeid 优先在指定的节点上执行查询
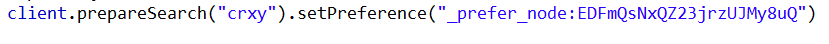
6:Custom (string) value:随机指定一个值就可以。

7:_shards:0,1,2,3,4:查询指定分片的数据

8:自定义:_only_nodes:nodeid1,nodeid2,nodeid3根据多个节点进行查询
Es默认没有提供这种查询方式,所以就只能修改源码了。
首先找到org.elasticsearch.cluster.routing.operation.plain.PlainOperationRouting这个类,es搜索时获取分片信息是通过这个类的。它的preferenceActiveShardIterator()方法就是根据条件来找出响应的分片。

看源码可知其主要是根据preference这个参数来决定取出的分片的。如果没有指定该参数,就随机抽取分片进行搜索。
下面的代码就是根据上面说的不同情况进行的一些判断,使用的switch case语句。
在里面多增加一项ONLY_NODES,这个可以接收多个节点id,这个参数需要配置到preference枚举类中,还要在这个类中的switch判断中判断参数_only_nodes。添加case语句。
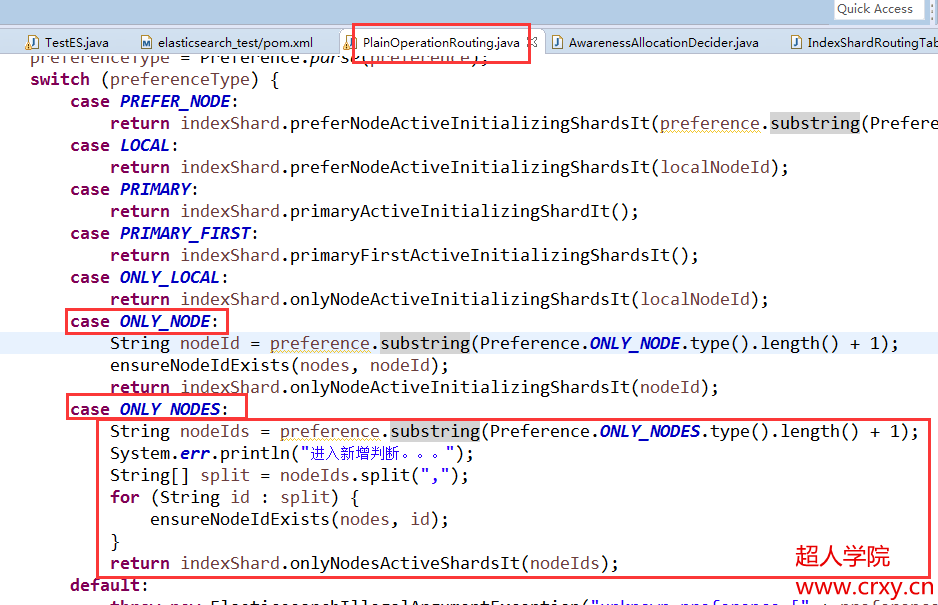
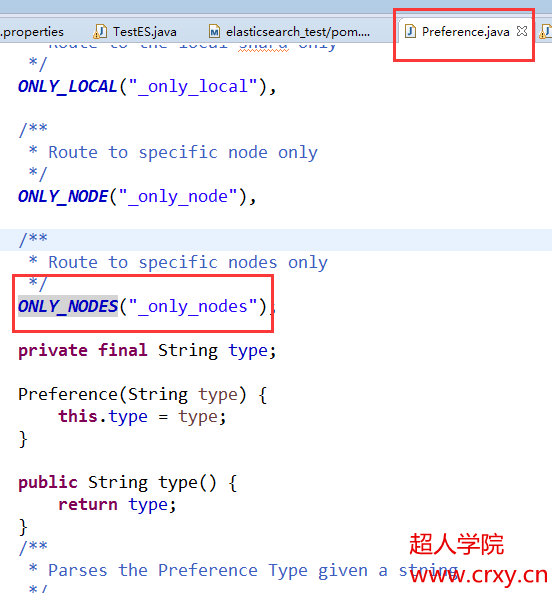
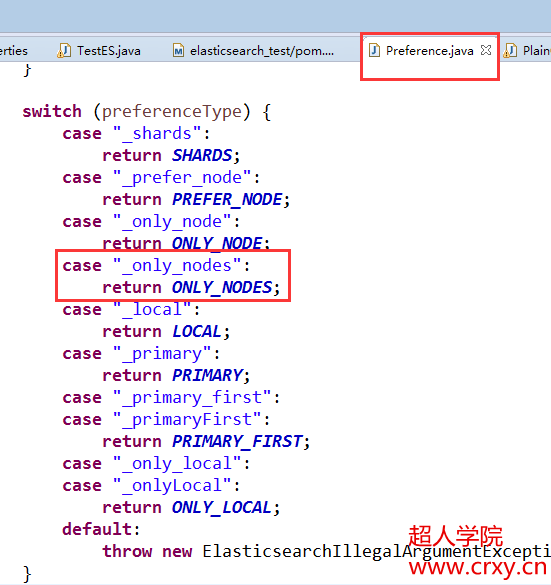
接下来就需要完善PlainOperationRouting类中的case语句判断逻辑了。
首先获取传递过来的所有节点id,以逗号分割。获取一个节点id的数组,下面循环判断传递的节点是否存在,如果不存在就抛异常。
下面就返回一个方法的返回值,这个方法是需要我们自己实现的,这个方法可以参考上面的onlyNodeActiveInitializingShardsIt这个方法。

接下来完善onlyNodesActiveShardsIt这个方法,

这样的话就可以从用户指定的多个节点中获取数据。
把项目重新打包,放到服务器上重新启动。
最新文章
- oracle函数大全(转载)
- 读懂IL代码就这么简单 (一)
- Mac Pro 安装 最新版的 SVN 1.9.4
- mysql 5.7.15发布
- Swift 中的函数(下)
- 优化mysql主从下的slave延迟问题
- configure: error: Please reinstall the libcurl distribution
- 【LeetCode】118 & 119 - Pascal's Triangle & Pascal's Triangle II
- windows下揪出java程序占用cpu很高的线程 并找到问题代码 死循环线程代码
- WebView加载页面的两种方式——网络页面和本地页面
- Flink从入门到放弃(入门篇1)-Flink是什么
- 记一次Hbase的行键过滤器事故问题
- ubuntu16.04 pip install scrapy 报错处理
- 一般服务器端口号的反斜杠表示访问webapp下的资源
- 微信web开发者工具 移动调试
- 四十二、Linux 线程——线程同步之条件变量之线程状态转换
- Unity3d中PureMVC框架的搭建及使用资料
- sublime3 怎么快速自定义头部注释信息
- [UE4]自定义函数,快速增加输入参数的一种方法
- 最近玩了下linux下的lampp注意一些使用