【scrapy】使用方法概要(一)(转)
【请初学者作为参考,不建议高手看这个浪费时间】
工作中经常会有这种需求,需要抓取互联网上的数据。笔者就经常遇到这种需求,一般情况下会临时写个抓取程序,但是每次遇到这种需求的时候,都几乎要重头写,特别是面临需要抓取大数量网页,并且被抓取网站有放抓取机制的时候,处理起来就会很麻烦。
无意中接触到了一个开源的抓取框架scrapy,按照introduction做了第一个dirbot爬虫,觉得很方便,就小小研究了一下,并在工作中用到过几次。
scrapy的文档是英文的,网上相关的说明很少,使用的过程中也遇到过很多问题,大部分都是在 stack overflow 上找到的解答,看来这个工具国外的同行们用的会更多些。鉴于国内关于scrapy的文章甚少,笔者希望能用自己的一些浅显的经验希望帮助大家更快对scrapy入门,作为笔者的第一篇分享文章,很难一气呵成完成,本文将分为几个部分,按照我自己的学习曲线作为组织,如果有错误,希望大家指正。
首先简要终结一下我认为scrapy最便利的几个地方:
1. 代码分工明确,一个抓取任务只需要在几个位置固定的地方增加代码,很容易就能写出基本的抓取功能。
2. 框架隐藏了很多抓取细节,如任务调度,重试机制,但并不是说框架不够灵活,例如框架支持以添加中间件的方式更改隐藏的细节,满足特殊需要,如使用代理ip池进行抓取,防止服务器封掉ip。
好啦,下面正式开始,从安装开始
笔者的运行环境是:linux python2.5
包管理使用的是:apt-get
安装流程:
1. 首先去官方网站下载源码
https://github.com/scrapy/scrapy/tarball/0.14
2. 安装scrapy以来的python库
sudo apt-get install python-twisted python-libxml2 python-pyopenssl python-simplejson
3. 安装
tar zxf Scrapy-X.X.X.tar.gz
cd Scrapy-X.X.X
sudo python setup.py install
4. 执行
scrapy
如果出现
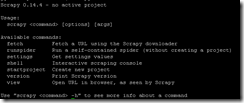
恭喜你,安装成功。
【未完待续~~~~~】
最新文章
- ASP.NET Core 1.1.0 Release Notes
- app使用微信支付成功后,点击返回到该app却跳到另外一个app去了
- sh4.case语句
- UVA 572 油田连通块-并查集解决
- 对button或radiobutton制作样式
- java生成excel文件
- sysbench压力测试工具简介和使用(一)
- /etc/profile和~/.bash_profile的区别
- java web 学习十二(session)
- jetty之安装,配置,部署,运行
- 发布MVC IIS 报错未能加载文件或程序集“System.Web.Http.WebHost
- iOS: 获取文件路径
- Lua学习(5)——迭代器与泛型for
- ElasticHD Windows环境下安装
- terminal、Shell、tty和console
- CF848E Days of Floral Colours——DP+多项式求逆/分治NTT
- JVM 内部原理(三)— 基本概念之类文件格式
- linux rabbitmq 远程登录
- scala学习——(1)scala基础(下)
- luogu P2073 送花 线段树