Unstanding LSTM
1.RNNs
我们可以把RNNs看成一个普通网络做多次复制后叠加在一起组合起来,每一个网络都会把输出传递到下一个网络中。
把RNNs按时间步上展开,就得到了下图;
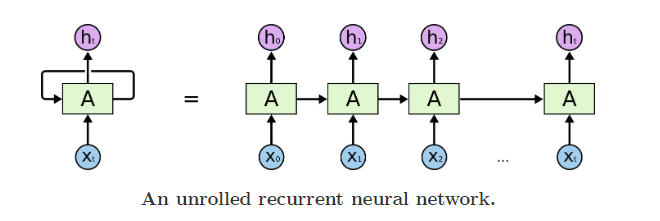
从RNNs链状结构可以容易理解到他是和序列信息相关的。
2.长时期依赖存在的问题
随着相关信息和预测信息的间隔增大,RNNs很难把他们关联起来了。
但是,LSTMs能解决这个问题
3. LSTM网络
Long Short Term Memory networks(长短期记忆网络)通常叫为LSTMS。LSTMs被设计用于避免前面提到的长时期依赖,他们的本质就是能够记住很长时期的信息。
RNNs都是由完全相同的结构复制而成的,在普通的RNNs中,这个模块非常简单,比如仅是单一的tanh层。
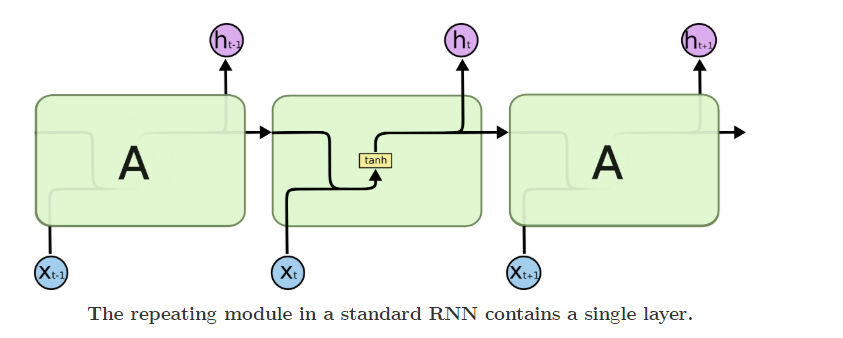
LSTMs也有类似的结构,不过重复模块部分不是一个简单的tanh层,而是4个特殊层。

先定义用到的符号:

3.1 LSTMs的核心思想
LSTMs最关键地方在于cell,即绿色部分的状态和结构图上横穿的水平线
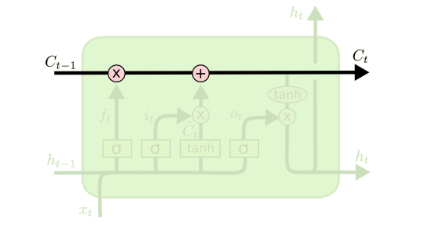
cell状态像是一条传送带,向量从cell上传过,只做了少量的线性运算,信息很容易穿过cell而不做改变(实现了长时期的记忆保留)
cell state 好比是一个记忆器,不断往cell输入数据,他会不断变化来记忆之前输入的信息。
可以看到,Ct-1到Ct经过两步,第一步是一个point wise的乘法操作,用来忘记不再需要的记忆,第二步是point wise的加操作,把Xt中有用的信息加到记忆中。
LSTMs通过门(gates)的结构来实现增加或者删除信息。
门可以实现选择性地让信息通过,通过一个sigmod神经层和一个逐点相乘的操作来实现。
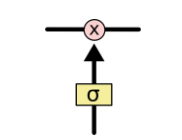
sigmod层输出的值为0到1,表示对应信息应该被通过的权重,0表示不让通过,1表示让所有信息通过。
每个LSTM由3个门结构,来实现保护和控制cell状态,分别是遗忘门forget gate layer、传入门input gate layer、输出门output gate layer。
3.2逐步理解LSTM
3.2.1遗忘门
LSTM第一步是要决定丢弃哪些信息,这通过一个叫做forget gate layer的sigmod层实现。
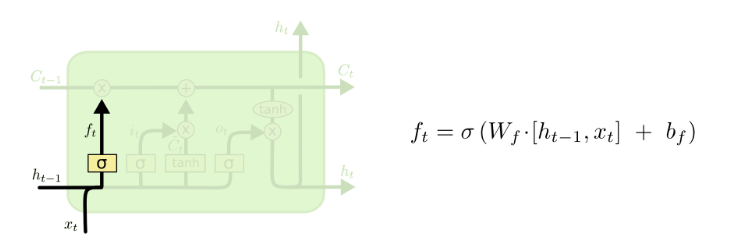
这里出现了ht-1,ht-1是输出,也是来自Ct-1,不过多了一层计算,可以理解为基于Ct-1给出的预测。
根据图上右边的公式,总的参数个数为s*(s+Xt的位数),可见Wf的规模是和S的大小直接相关的,s越大,虽然保存的信息越多,但是模型的参数规模也会按照平方数量上升。
一个根据所有上下文信息来预测下一个词的语言模型,每个cell状态都应该保存当前主语的性别(保留信息),接下来才能正确使用代词,当我们又开始描述一个新主语的时候,就用改把上文中的主语性别给忘了才对(忘记信息)
3.2.2传入门
LSTM下一步是要决定哪些新信息要加入到cell 状态中来。包括两个部分,1.把Xt中的信息转换为Ct-1一样长度的向量,这个过程就是带波浪线Ct所做的事,第二事对带波浪线的Ct进行一个信息筛选,筛选的功能是通过it和带波浪线的Ct的相乘来实现的,这和上面的ft非常相似,ft表示forget,it表示input,一个是对原有信息进行筛选,一个是对新的信息进行筛选。
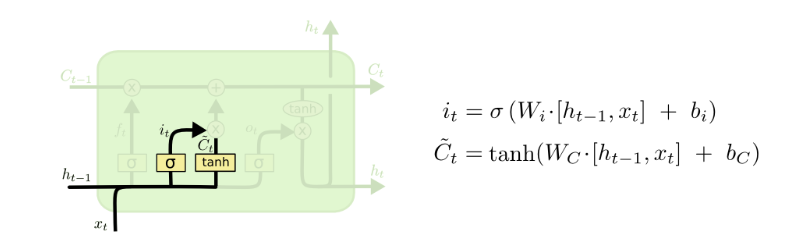
在我们的语言模型中,我门把新的主语的性别信息加入cell状态中,替换老的状态信息。
有了上述结构,就能够更新cell状态了Ct-1 to Ct 即把两部分筛选的信息合并起来。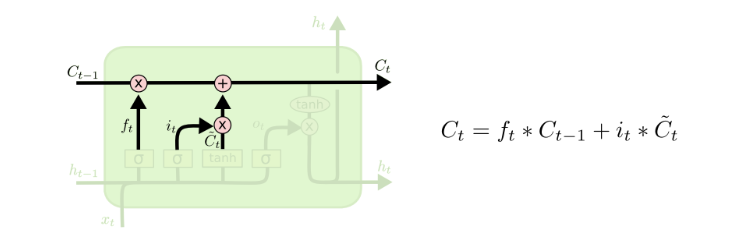
3.2.3输出门
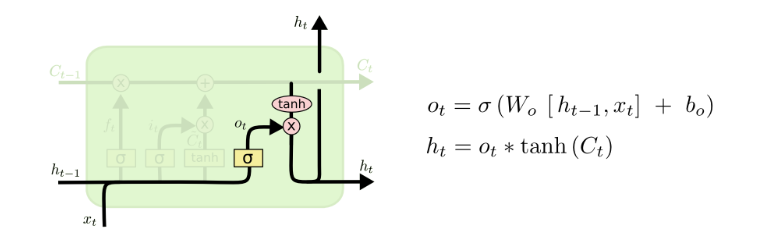
最后我们要来决定输出什么值,这个输出值是依赖于cell的状态Ct,还要经过一个过滤处理。
首先,我门使用一个sigmoid层决定Ct中哪部分信息被输出,然后把Ct通过一个tanh层(把数值都归到-1到1),把tanh层的输出和sigmoid层计算出来的权重相乘,得到最后的输出结果。
在语言模型中,模型刚刚接触了一个代词,接下来可能要输出一个动词,这个输出可能和代词的信息息息相关了,比如动词应该采用单数形式还是复数形式,所以我们要把刚学到的和代词相关的信息加入到cell状态中,才能进行正确的预测。
4.LSTM的变种
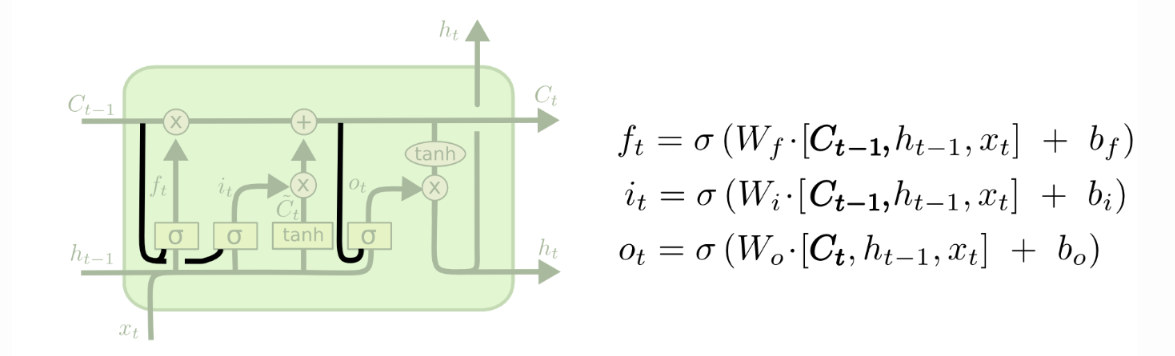
4.1增加peephole connections
在所有门之前都与状态线相连,使得状态信息对门的输出值产生影响,但有一些论文只在部分门前添加。
4.2耦合遗忘门和输入门
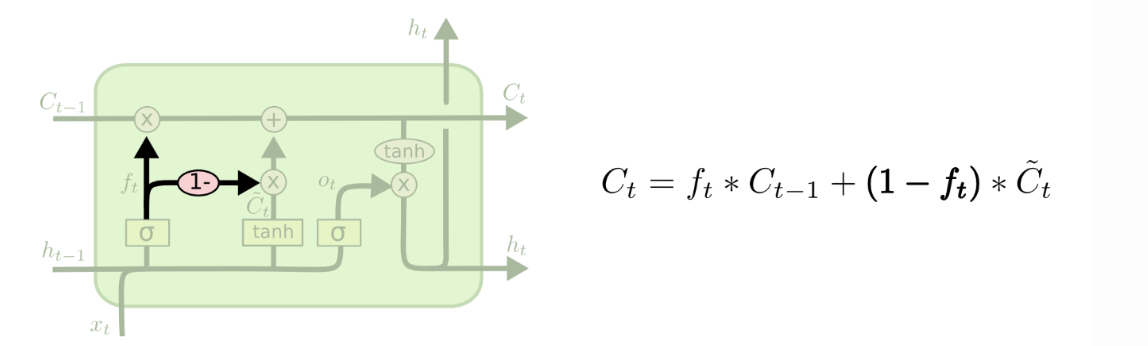
将遗忘门和输入们耦合在一起,遗忘多少就更新多少新状态,没有遗忘就不用更新。
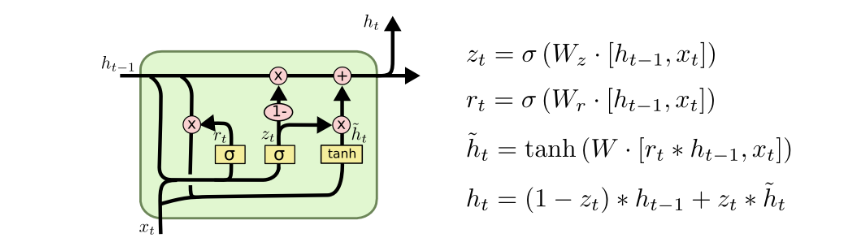
4.3GRU
将遗忘门和输入门统一为更新门,而且把h和c合并了。
5.为什么LSTM比RNN能解决长时期依赖?
RNN是怎么修改Ht的?Ht = tanh(W Xt + U Ht-1),这是一个复合函数,符合函数求偏导是连乘,其中tanh是双曲正切,在X偏大或者偏小的时候导数接近为0,反向传播时,当链路比较长时,就没有梯度传回来矫正参数了。
而LSTM不是复合函数,而是两个函数求和,f(x) +g(x)求偏导,得到两个偏导的和,就算有一个约等于0,也不会导致整体约等于0.
LSTM最大的变化就是把RNN的连乘变成了求和,不会严重地出现梯度消失的问题。
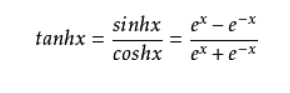
最新文章
- 基于SOA架构的TDD测试驱动开发模式
- C#正则表达式验证
- C# 改变无边框窗体的尺寸大小
- PHP 开发 APP 接口 学习笔记与总结 - JSON 结合 XML 方式封装通信接口
- C++ Primer 笔记(2)第二章 变量与基本类型
- Farm Irrigation(并查集)
- saltstack对递归依赖条件(死循环依赖)的处理
- 【Python3之内置函数】
- VM及centOS系统安装
- [Codeforces 606C]Sorting Railway Cars
- HDU6278 Just h-index
- Mysql8.0导入数据时出错
- JS中的continue,break,return的区别
- Python接口自动化【requests处理Token请求】
- HDU 4403 A very hard Aoshu problem(dfs爆搜)
- 2018-01-06自定义view时遇到的问题
- LeetCode: Search Insert Position 解题报告
- mysql常用日期、时间查询
- 【Web】前台传送JSON格式数据到后台Shell处理
- RenderMonkey基本使用方法【转】