Python_014(面向对象之继承)
一.面向对象之继承
1.初始继承
引入:面向对象的三大特性:继承,多态,封装
a.继承是创建新类的一种方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类;新建的类称为派生类和子类;
b:引入几个小程序:
class Animal:
def __init__(self, name, sex, age):
self.name = name
self.sex = sex
self.age = age
def eat(self,a1):
print('%s吃%s' % (self.name,a1))
def drink(self):
print('%s喝东西' % (self.name)) class Cat(Animal):
def miaow(self):
print('喵喵叫')
def eat(self): # 只执行自己类中的方法
print(666) class Brid(Animal):
def __init__(self, name,sex,age,wing):
# Animal.__init__(self, name, sex, age)
super().__init__(name,sex,age)
self.wing = wing
**从上面代码可以看出,Animal是父类(基类,超类),而Brid(子类,派生类)实例化的对象时候有三种情况需要注意
1)实例化的对象想要只执行父类的方法:那么在子类中就不要定义与父类同名的方法,因为它会先调用自己本类的这个方法;
2)实例化的对象想要只执行子类的方法:在子类中创建这个方法就行;若没有,才会去父类去找;
3)当实例化的对象既要执行子类的方法,又要执行父类的方法时,有两种解决办法;
a:第一种是第19行格式,将自己类中的__init__方法做为跳板,执行父类的__init__方法;传入参数,这里面不要忘了传入self(对象本身)
b:20行格式,用super()函数,函数里的super(Brid,self)可以省略;
二.继承的进阶
1.继承分为单继承,多继承(只有Python中有多继承概念),多继承又被称为砖石继承;
2.Python中类分为两种(经典类和新式类)
1)Python2中(既有新式类,又有经典类)所有类默认都不继承object类,都默认是经典类,你可以让它继承object类,转为新式类
2)Python3中(只有新式类),所有类都默认继承object类;
**补充知识点,object类中有__init__()方法,这也是你为什么在类中不写__init__()方法不会报错的原因;
3.单继承:经典类和新式类查询顺序一样;
class A:
pass
def func(self):
print('IN A')
class B(A):
pass
def func(self):
print('IN B')
class C(B):
pass
def func(self):
print('IN C')
c1 = C()
c1.func()
a:经典类查询顺序: C->B->A b:新式类查询顺序: C->B->A->object
4.多继承中查询顺序:
a;新式类:遵循广度优先,一条路走到倒数第二级,判断如果有其他路走到,则返回走另一条路,如果没有,则走到终点;
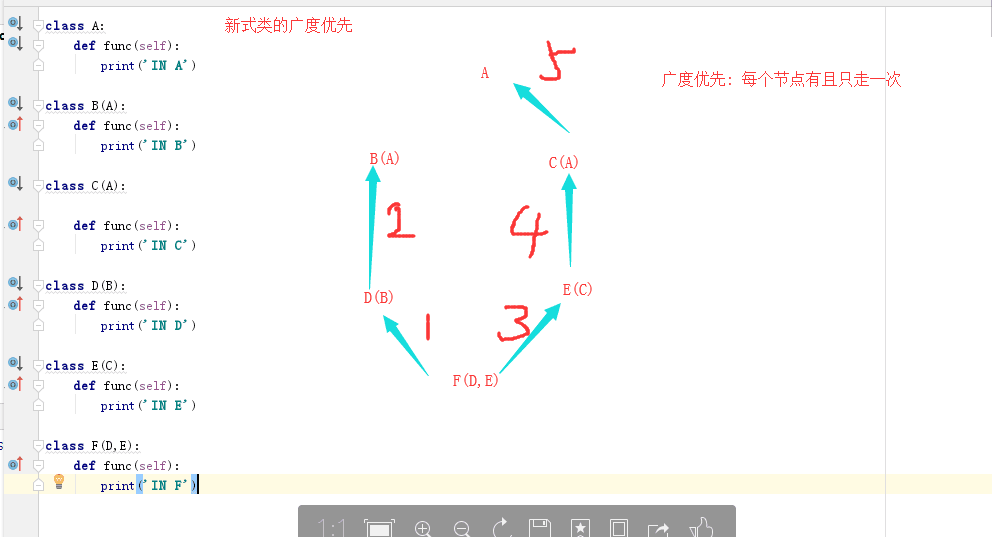
b:多继承的经典类:深度优先:一条路走到底;如果一条走到头没找到,在选择另外一条路;
**小知识:用类名.miro()查找类的广度优先顺序;
总结:继承的优点:1)提高了代码的复用性 2)提高了代码的维护性 3)让类与类之间产生了关系,是多态的前提;
补充知识点:Python的继承体系mro详解
引入mor之后,按照c3算法,进行线性化;
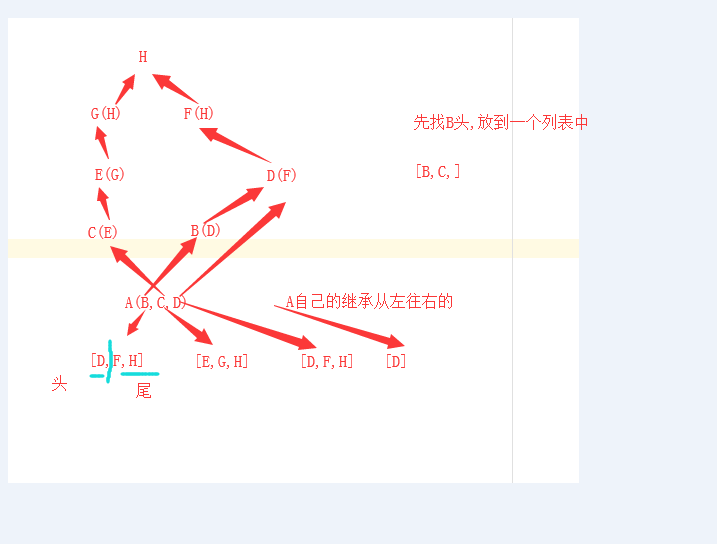
原理:
#首先找到A继承的三个类的深度继承顺序,放到一个列表中
L[B] = [B,D,F,H] #B往上面的继承顺序
L[C] = [C,E,G,H] #C往上面的继承顺序
L[D] = [D,F,H] #D往上面的继承顺序
#第二步:A自己的广度,第一层
L[A] = [B,C,D]
list = [A,B,C,D,F,E,G,H,O]
#每个列表的第一个元素为头部,从第一个列表的头部开始找,找其他列表中尾部是否含有
这个类名,如果没有,提取出来放到一个列表中,如果有,找下一个列表的头部,循环下去
只要提取来一个,我们就从第一个列表的头部接着重复上面的操作.
1 [B,D,F,H] [C,E,G,H] [D,F,H] [B,C,D]
2 [D,F,H] [C,E,G,H] [D,F,H] [C,D] #提取了头部的B,然后将其他列表头部的B删除,并将B放到list中
3 [D,F,H] [E,G,H] [D,F,H] [D] #因为第一个列表的D在其他列表的尾部存在,所以跳过D,然后找第二个列表的头部C,提取了头部的C,然后将其他列表头部的B删除,并将B放到list中
如下图所示:
class H:
def func(self):
print('inH')
class G(H):
def func(self):
print('inG')
class F(H):
def func(self):
print('inF')
class E(G):
def func(self):
print('inE')
class D(F):
def func(self):
print('inD')
class C(E):
def func(self):
print('inC')
class B(D):
def func(self):
print('inB')
class A(C,F,H):
def func(self):
print('inA')
r = A()
print(A.mro())
所以列表为: B:[B,D,F,H] C;[C,E,G,H] D:[D,F,H] A[B,C,D] 所以按照c3算法找
最后结果为 A B C D F E H O
最新文章
- 一起学微软Power BI系列-使用技巧(2)连接Excel数据源错误解决方法
- 用python实现逻辑回归
- Android中处理崩溃异常
- memset函数详解
- NDB Cluster 存储引擎物理备份
- Android 项目实战--手机卫士(实现splash)
- LAMP php5.4编译
- Codeigniter 利用加密Key(密钥)的对象注入漏洞
- 第五篇:python高级之面向对象高级
- php之上传小案例,根据时间:月日分创建目录并随机生成文件名
- java--字节数组输入、输出流
- tableview 分割线置最左边的解决方法
- HDU-1049
- Noip2013之路
- python 开发者 精品
- Javascript事件模型(一):DOM0事件和DOM2事件
- Hibernate table schema 的设置与应用
- android新闻App源码、仿微信源码、地图音乐源码等
- js高级4
- sqlserver2012 offset分页