吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
2024-09-13 17:12:54
import numpy as np
import matplotlib.pyplot as plt from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split def create_regression_data(n):
'''
创建回归模型使用的数据集
'''
X =5 * np.random.rand(n, 1)
y = np.sin(X).ravel()
# 每隔 5 个样本就在样本的值上添加噪音
y[::5] += 1 * (0.5 - np.random.rand(int(n/5)))
# 进行简单拆分,测试集大小占 1/4
return train_test_split(X, y,test_size=0.25,random_state=0) #KNN回归KNeighborsRegressor模型
def test_KNeighborsRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=neighbors.KNeighborsRegressor()
regr.fit(X_train,y_train)
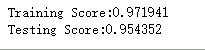
print("Training Score:%f"%regr.score(X_train,y_train))
print("Testing Score:%f"%regr.score(X_test,y_test)) #获取回归模型的数据集
X_train,X_test,y_train,y_test=create_regression_data(1000)
# 调用 test_KNeighborsRegressor
test_KNeighborsRegressor(X_train,X_test,y_train,y_test)
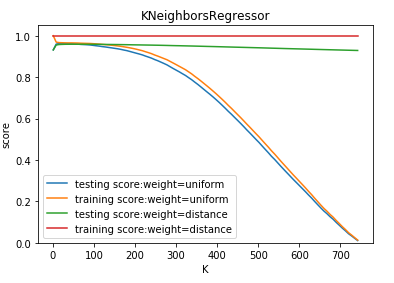
def test_KNeighborsRegressor_k_w(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 weights 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int')
weights=['uniform','distance'] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线
for weight in weights:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(weights=weight,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight)
ax.plot(Ks,training_scores,label="training score:weight=%s"%weight)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_w
test_KNeighborsRegressor_k_w(X_train,X_test,y_train,y_test)
def test_KNeighborsRegressor_k_p(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 p 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int')
Ps=[1,2,10] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线
for P in Ps:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(p=P,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:p=%d"%P)
ax.plot(Ks,training_scores,label="training score:p=%d"%P)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_p
test_KNeighborsRegressor_k_p(X_train,X_test,y_train,y_test)

最新文章
- SQLSERVER常见系统函数之字符串函数(一)
- git命令查看远程分支
- 30分钟学会反向Ajax
- java中对象多态时成员变量,普通成员函数及静态成员函数的调用情况
- 用TypeScript开发了一个网页游戏引擎,开放源代码
- Sqlserver Sql Agent Job 只能同时有一个实例运行
- Oracle DB SQL 性能分析器
- 棋盘问题 分类: 搜索 POJ 2015-08-09 13:02 4人阅读 评论(0) 收藏
- js时间转换相关
- ASP.NET中的验证控件
- Android应用公布的准备——生成渠道包
- OA小助手
- python codis集群客户端(一) - 基于客户端daemon探活与服务列表维护
- 解决mongodb的安装mongod命令不是内部或外部命令
- Mathematica 代码
- 第一次玩博客,今天被安利了一个很方便JDBC的基于Spring框架的一个叫SimpleInsert的类,现在就来简单介绍一下
- 使用addeventlistener为js动态创建的元素添加事件监听
- 潭州课堂25班:Ph201805201 WEB 之 HTML 第一课 (课堂笔记)
- 第十八章 dubbo-monitor计数监控
- Nginx多进程高并发、低时延、高可靠机制在缓存代理中的应用