Redis源码阅读-Dict哈希字典
2024-10-18 06:25:32
Dict和Java中的HashMap很相似,都是数组开链法解决冲突。
但是Redis为了高性能, 有很多比较微妙的方法,例如 数组的大小总是2的倍数,初始大小是4。
rehash并不是一次就执行完,而是分多次执行。每次执行一部分。其中rehashidx表示现在hash到哪一个桶啦,-1表示现在并没有rehash.
dict包含两个dicttable, 编号为0,1, dictht0是直接存储哈希表的地方, dictht1在rehash中用到,当rehashidx不为-1时, 查找key,同时在dictht1和dictht0中查找。
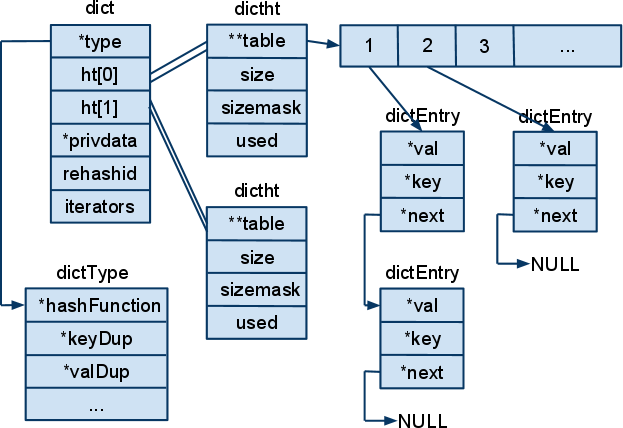 、
、
数据结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
查找key
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table; if (d->ht[].size == ) return NULL; /* We don't have a table at all */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = ; table <= ; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
redis的rehash是增量rehash,每次rehash一部分
rehash过程:
1. 从 dictht0的table 0到----N-1查找不为NULL的位置(非空桶)
2. 对该位置的链表进行处理, hash到dictht 1的table 1中。
rehash的函数,设置了n参数,表示要处理的非空桶的个数,但是在函数内部设置了最多访问10*n个空桶。
int dictRehash(dict *d, int n) {
int empty_visits = n*; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return ;
while(n-- && d->ht[].used != ) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[].size > (unsigned long)d->rehashidx);
while(d->ht[].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == ) return ;
}
de = d->ht[].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[].sizemask;
de->next = d->ht[].table[h];
d->ht[].table[h] = de;
d->ht[].used--;
d->ht[].used++;
de = nextde;
}
d->ht[].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[].used == ) {
zfree(d->ht[].table);
d->ht[] = d->ht[];
_dictReset(&d->ht[]);
d->rehashidx = -;
return ;
}
/* More to rehash... */
return ;
}
和adlist一样,dict也有迭代器
迭代方法如下:
dictEntry *dictNext(dictIterator *iter)
{
//对表的桶进行遍历,直到找到一个非空桶,返回
while () {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == - && iter->table == ) {
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d);//对dict进行指纹
}
iter->index++;
//如果迭代到表的最后一个桶,就判断要不要迭代第二个表
if (iter->index >= (long) ht->size) {
if (dictIsRehashing(iter->d) && iter->table == ) {
iter->table++;
iter->index = ;
ht = &iter->d->ht[];
} else {
break;
}
}
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}
Dict的API如下:
/* API */
/* 字典创建, type参数制定各类对字典的自定义函数,会初始化dictht, dict */
dict *dictCreate(dictType *type, void *privDataPtr);
int dictExpand(dict *d, unsigned long size);
/* 添加键值对,内部调用addRaw和setvalue ,如果已经存在,返回NULL*/
int dictAdd(dict *d, void *key, void *val);
/* 添加键 ,如果已经存在,返回NULL*/
dictEntry *dictAddRaw(dict *d, void *key);
/* 添加一个key,如果存在,直接设置value,设置key的value */
int dictReplace(dict *d, void *key, void *val);
/* 添加一个key,如果存在,直接返回 */
dictEntry *dictReplaceRaw(dict *d, void *key);
/* 删除一个节点,需要free那个节点 */
int dictDelete(dict *d, const void *key);
/* 删除一个节点,不需要free那个节点 */
int dictDeleteNoFree(dict *d, const void *key);
/* 删除dict*/
void dictRelease(dict *d);
/* 查找key*/
dictEntry * dictFind(dict *d, const void *key);
/* 查找key的value*/
void *dictFetchValue(dict *d, const void *key);
/* 将dict的size设置和元素数量一样,但是符合2的倍数*/
int dictResize(dict *d);
dictIterator *dictGetIterator(dict *d);
dictIterator *dictGetSafeIterator(dict *d);
dictEntry *dictNext(dictIterator *iter);
void dictReleaseIterator(dictIterator *iter);
dictEntry *dictGetRandomKey(dict *d);
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count);
void dictPrintStats(dict *d);
unsigned int dictGenHashFunction(const void *key, int len);
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len);
void dictEmpty(dict *d, void(callback)(void*));
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);
/* rehash,设置一个最长时间*/
int dictRehashMilliseconds(dict *d, int ms);
void dictSetHashFunctionSeed(unsigned int initval);
unsigned int dictGetHashFunctionSeed(void);
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, void *privdata);
上面的API很多函数内部都会判断当前是不是还在rehash状态,如果是,就rehash一步。
在rehash前,会判断是不是有迭代器存在,如果有迭代器存在,就不rehash
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
最新文章
- C# await和async
- Linux基础练习题(二)
- 高德地图纯js和html
- const char **
- ASP通过代码绑定Gridview控件
- phpstorm自动对齐数组=>,自动加空格
- NSLog中的%@
- [OFBiz]开发 四
- CodeForces 732C Sanatorium (if-else)
- JavaScript学习笔记 -- ES6学习(三) 变量的解构赋值
- Mutex的使用方法以及封装的AutoLock介绍(转载)
- Codeforces Round #354 (Div. 2)_Vasya and String(尺取法)
- Smarty模板的基础
- Spark源码剖析(六):Worker原理与源码剖析
- PHPExcel生成或读取excel文件
- Mac appStore下载软件报500错误的解决方法
- 2072. Kirill the Gardener 3
- 【EF6学习笔记】(七)读取关联数据
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
- 批量更改数据库表架构(生成sql后直接执行!)