Hadoop MapReduce 操作 统计词频
1、 准备文件并设置编码格式为UTF-8并上传Linux
1)设置编码:首先打开文件点击左上角 文件(F) 点击另存为并将编码(E)设置为UTF-8 然后保存(S)替换的原来的文件
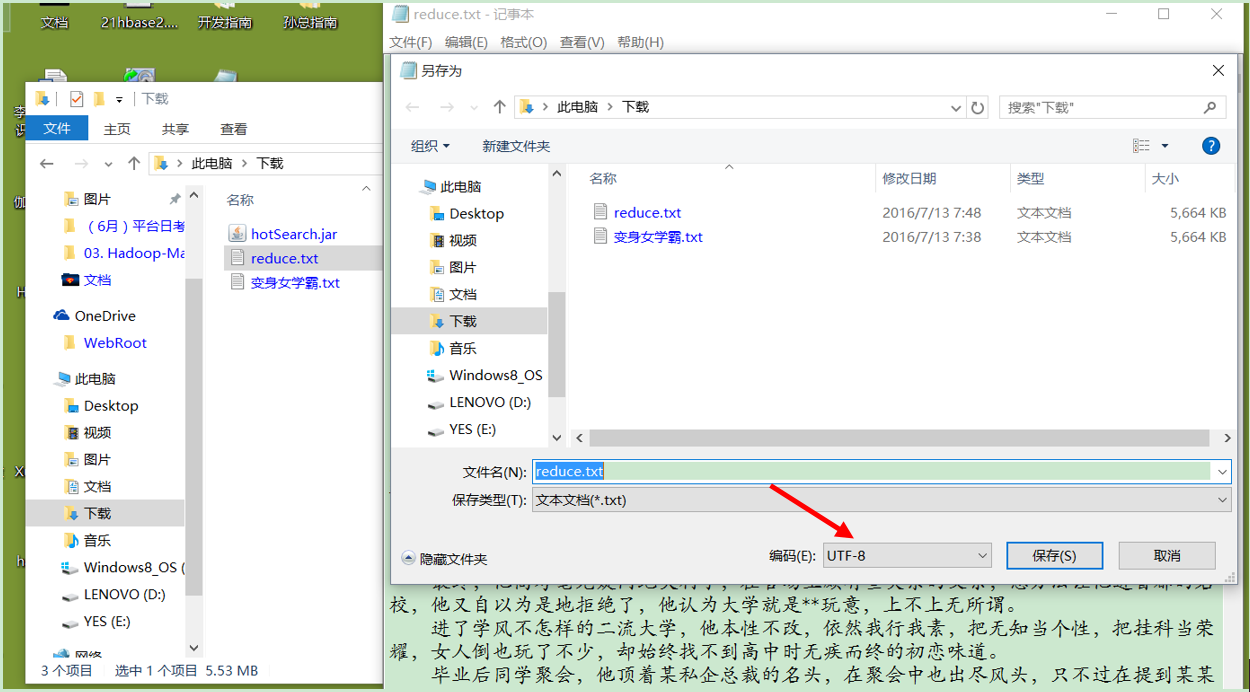
2)用工具将文件上传就Linux
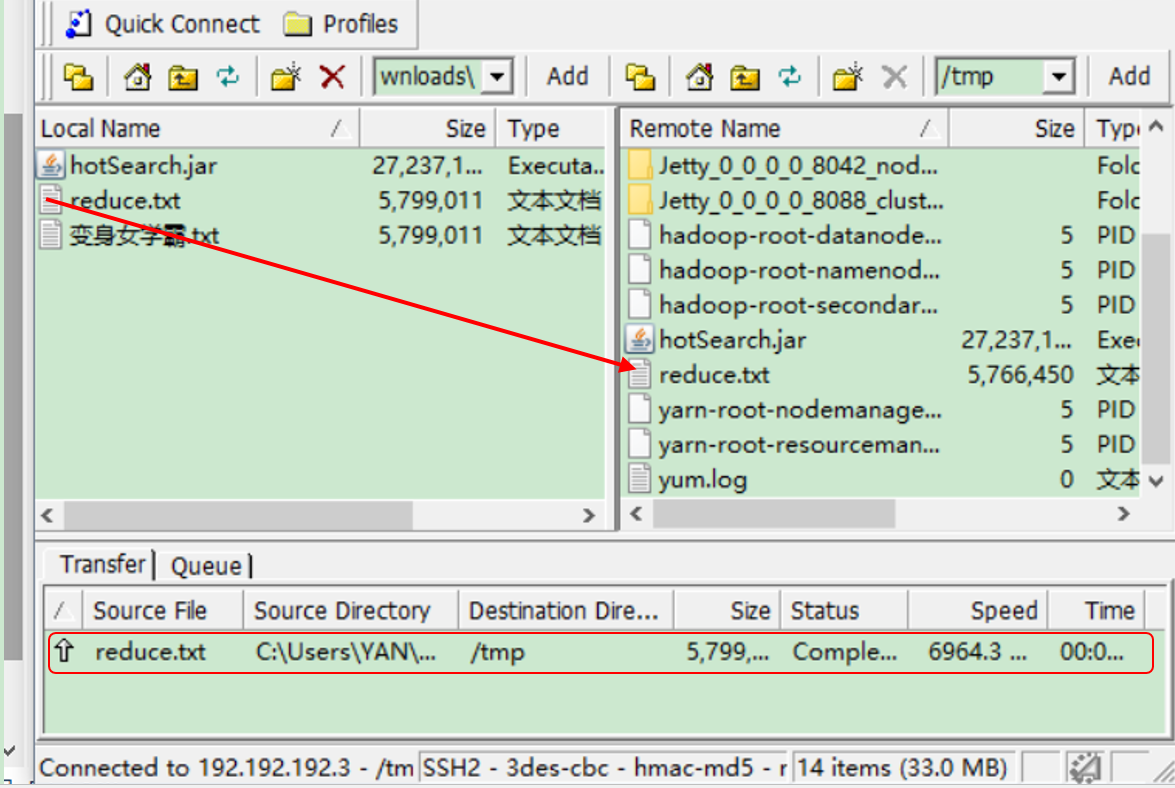
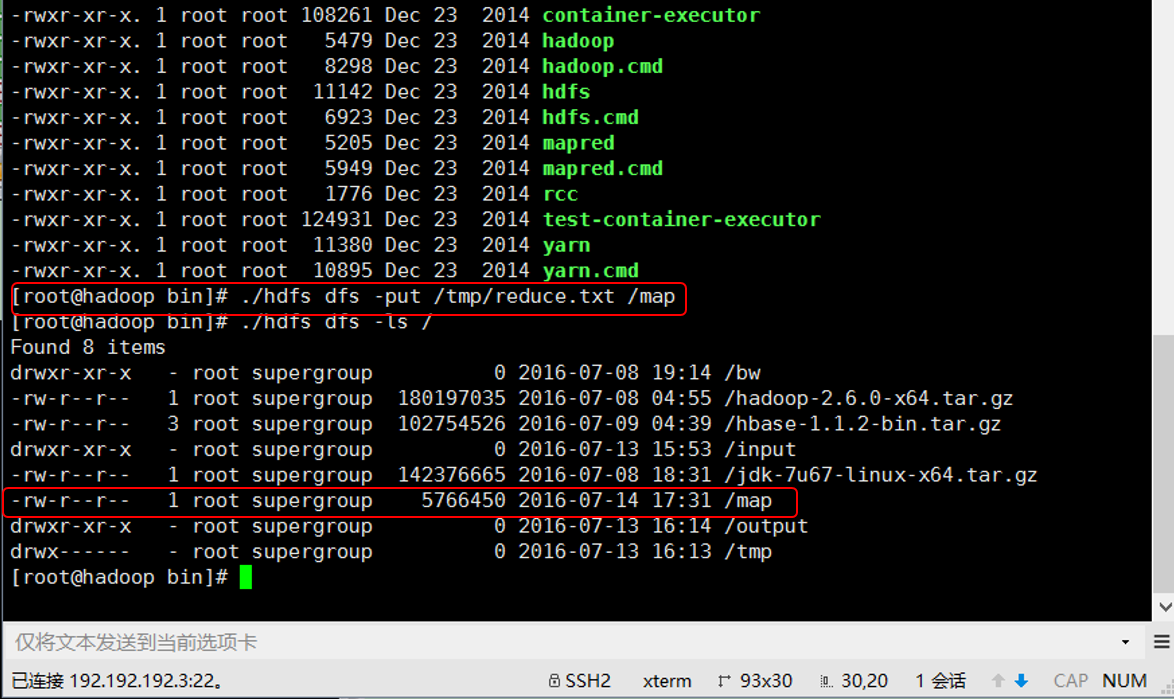
3)将文件上传至HDFS
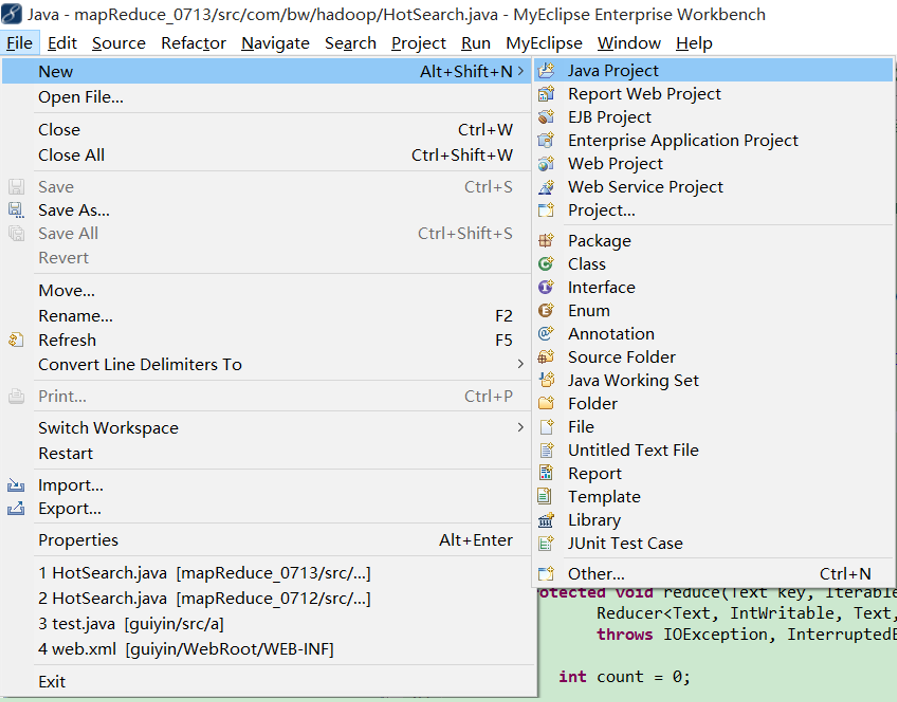
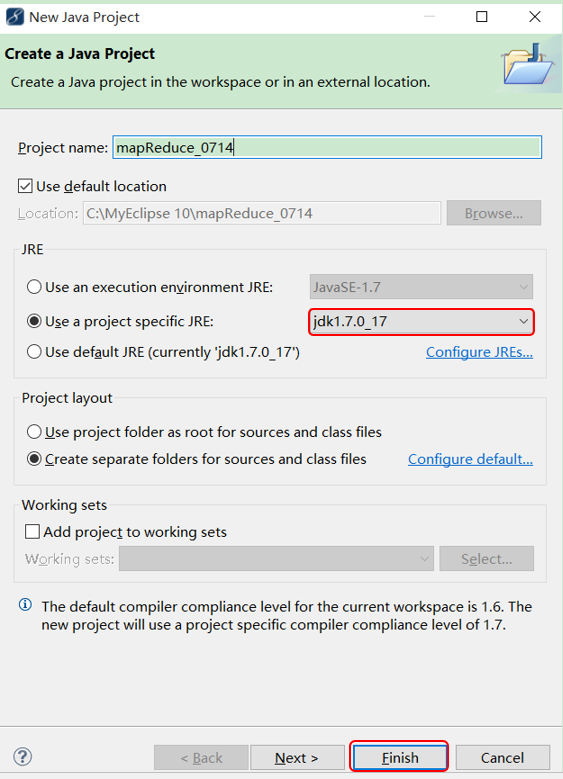
2、 新建一个Java Project
JDK必须是1.7版本以后的否则不支持

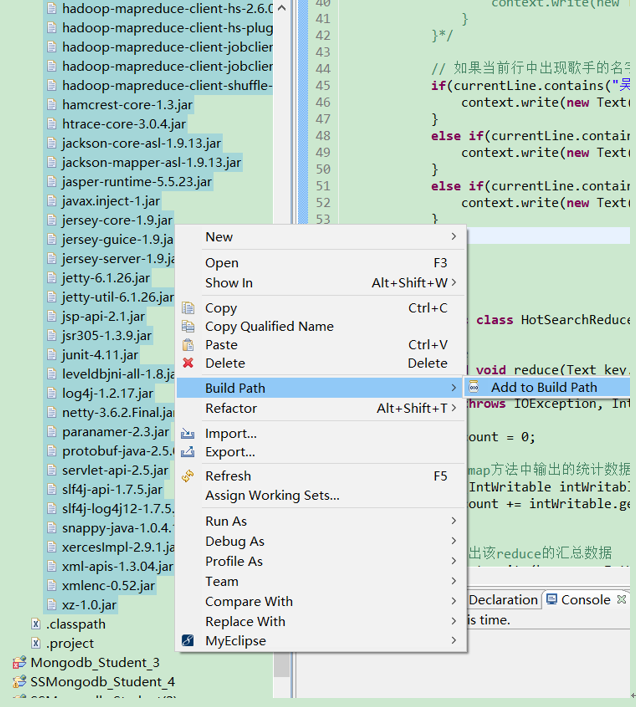
3、 导入jar
导入好多jar包并Add to Build Path

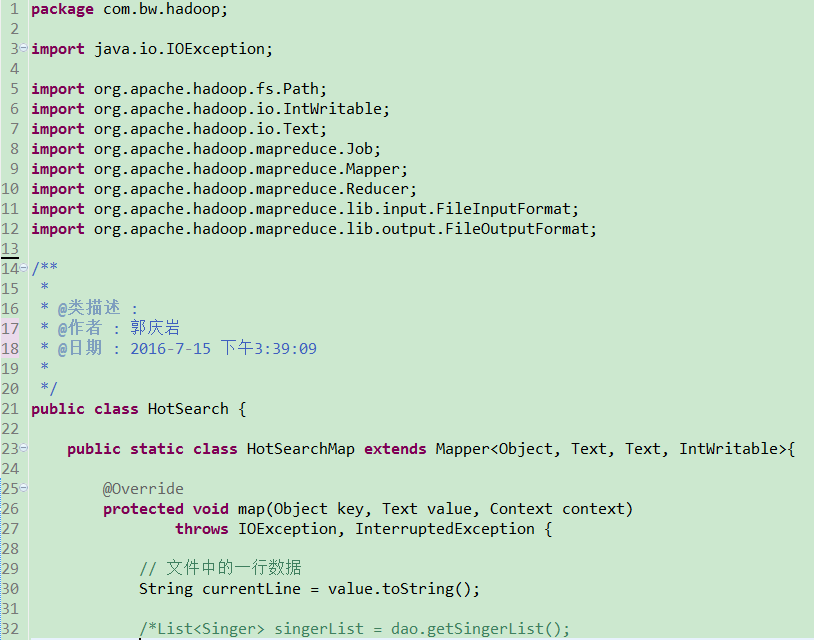
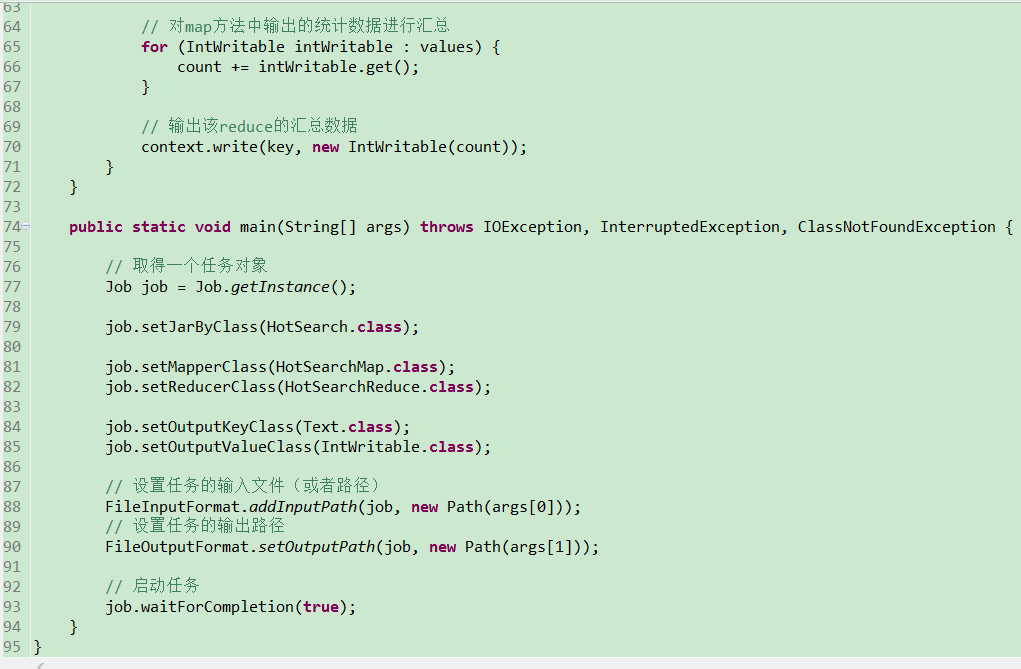
4、 编写Map()和Reduce()

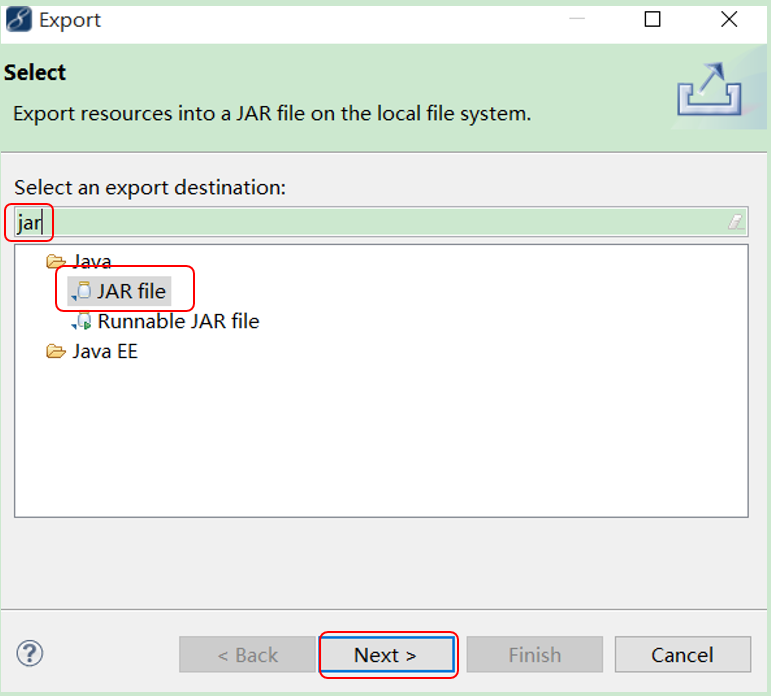
5、将代码输出成jar
1) 将代码输出成jar

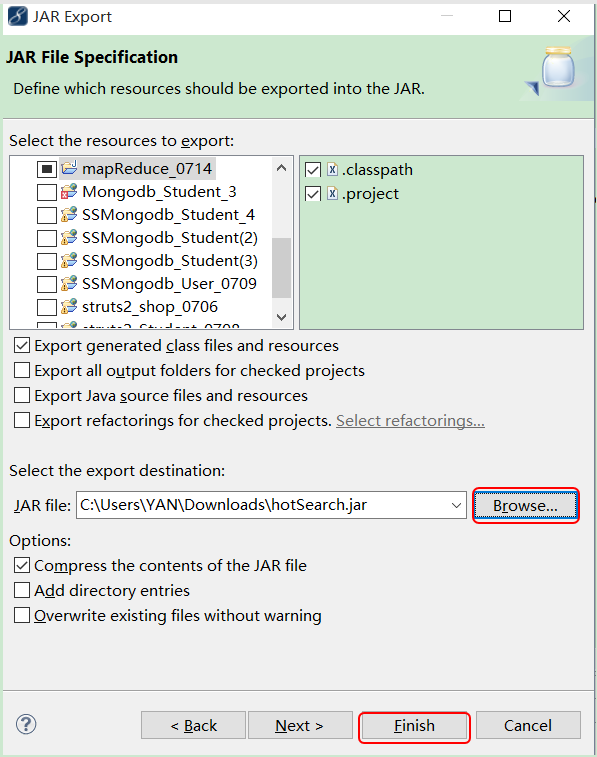
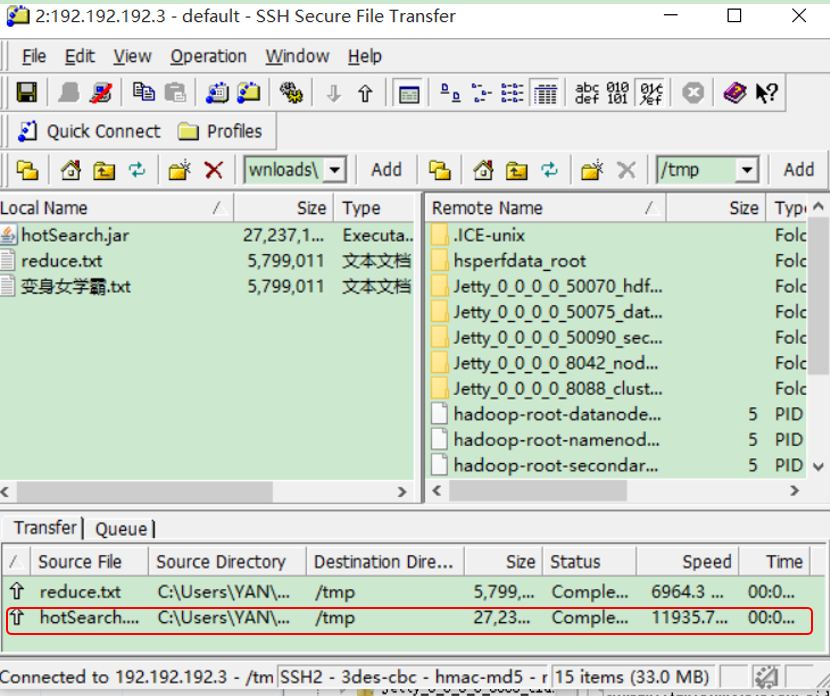
2) 将生成的jar上传至Linux
6、在linux中启动hdfs
1) 启动hdfs

1) 将text文件上传到HDFS

7、修改两个配置文件

在<configuration>配置项中增加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
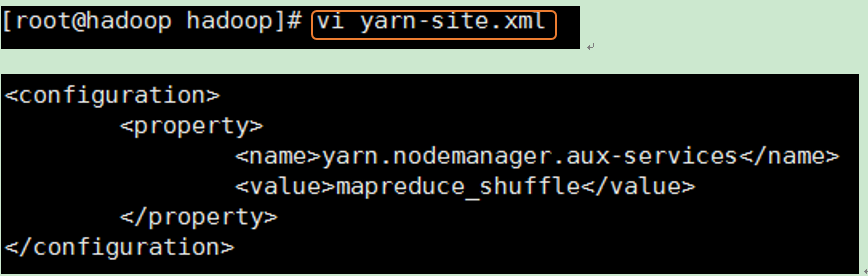
在<configuration>配置项中增加以下内容:
(参数解释:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运MapReduce程序)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8、在linux中启动yarn
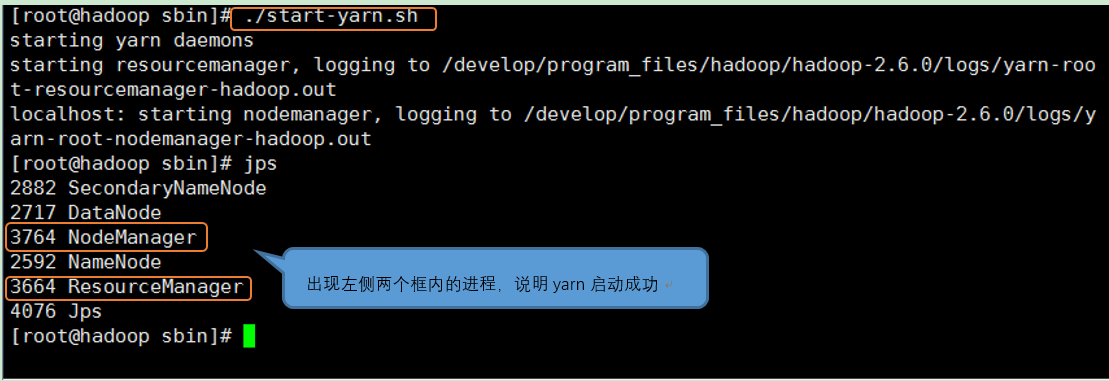
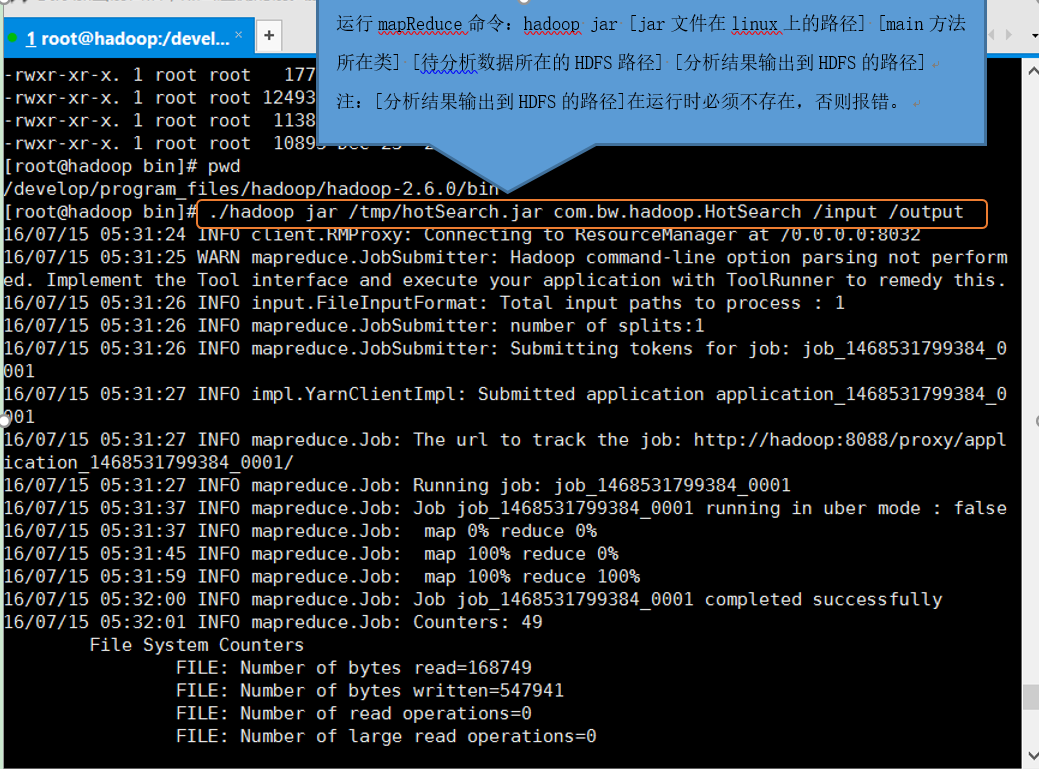
9、运行mapReduce
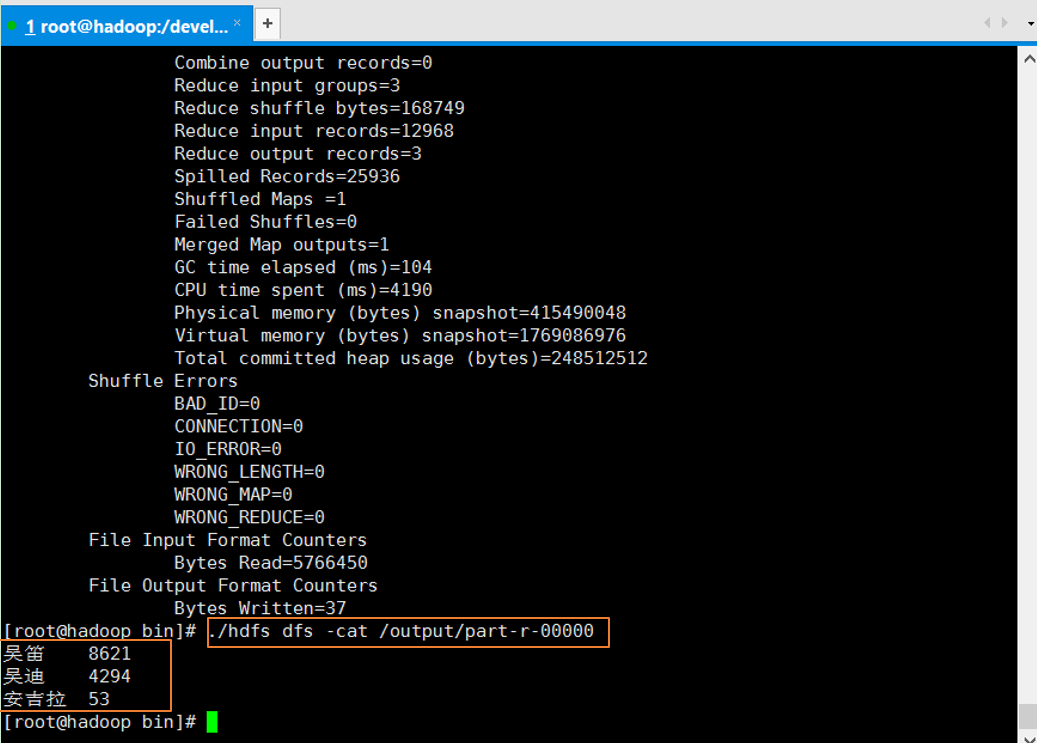
10、查看运行结果
最新文章
- 分布式文件系统 - FastDFS 简单了解一下
- NSURLConnection实现文件上传和AFNetworking实现文件上传
- JS 字符串
- PYTHON 内置函数
- 学习微信小程序之css10外边距
- Gradle常用命令
- 安装Docker Toolbox后出现的问题
- 安全模式下运行Windows installer并卸载程序
- 整理一下Entity Framework的查询
- GC之七--gc日志分析工具
- wmi详解,RPC和防火墙
- HDU 3487 Play with Chain(Splay)
- Mac系统下下删除加锁文件方法|使用终端命令强制清除废纸篓中的文件
- 《MySQL必知必会》[02] 多表联合查询
- NodeJs之数据库异常处理
- Python接口自动化测试 HTTP协议
- sololearn的c++学习记录_4m11d
- Spark学习之在集群上运行Spark
- java中的定时任务小示例
- NET设计模式 第二部分 创建型模式(4):工厂方法模式(Factory Method)