Python面试题之Super函数
这是个高大上的函数,在python装13手册里面介绍过多使用可显得自己是高手 23333. 但其实他还是很重要的. 简单说, super函数是调用下一个父类(超类)并返回该父类实例的方法. 这里的下一个的概念参考后面的MRO表介绍.
help介绍如下:
super(type, obj) -> bound super object; requires isinstance(obj, type)
super(type) -> unbound super object
super(type, type2) -> bound super object; requires issubclass(type2, type)
Typical use to call a cooperative superclass method:
class C(B):
def meth(self, arg):
super(C, self).meth(arg)
由此可知, super有三种用法, 第一参数总是召唤父类的那个类, 第二参数可缺(返回非绑定父类对象),也可以是实例对象或该类的子类. 最终返回的都是父类的实例(绑定或非绑定). 在Python3中,super函数多了一种用法是直接super(),相当于super(type,首参), 这个首参就是一般的传入的self实例本身啦. 因为在py2里面常用也是这种写法.
另外, 在py2中, super只支持新类( new-style class, 就是继承自object的).
为什么要调用父类?
在类继承时, 要是重定义某个方法, 这个方法就会覆盖掉父类的相应同名方法. 通过调用父类实例, 可以在子类中同时实现父类的功能.例如:
# Should be new-class based on object in python2.
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
super(B, self).__init__()
print "leave B" >>> b = B()
enter B
enter A
leave A
leave B
通过调用super获得父类实例从而可以实现该实例的初始化函数. 这在实践中太常用了 (因为要继承父类的功能, 又要有新的功能).
直接使用父类来调用的差异
事实上, 上面的super函数方法还可以这么写:
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
A.__init__(self)
print "leave B"
通过直接使用父类类名来调用父类的方法, 实际也是可行的. 起码在上面的例子中效果上他们现在是一样的. 这种方法在老式类中也是唯一的调用父类的方法 (老式类没有super).
通过父类类名调用方法很常用, 比较直观. 但其效果和super还是有差异的. 例如:
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
A.__init__(self)
print "leave B" class C(A):
def __init__(self):
print "enter C"
A.__init__(self)
print "leave C" class D(B,C):
def __init__(self):
print "enter D"
B.__init__(self)
C.__init__(self)
print "leave D"
>>> d=D()
enter D
enter B
enter A
leave A
leave B
enter C
enter A
leave A
leave C
leave D
可以发现, 这里面A的初始化函数被执行了两次. 因为我们同时要实现B和C的初始化函数, 所以分开调用两次, 这是必然的结果.
但如果改写成super呢?
class A(object):
def __init__(self):
print "enter A"
print "leave A" class B(A):
def __init__(self):
print "enter B"
super(B,self).__init__()
print "leave B" class C(A):
def __init__(self):
print "enter C"
super(C,self).__init__()
print "leave C" class D(B,C):
def __init__(self):
print "enter D"
super(D,self).__init__()
print "leave D"
>>> d=D()
enter D
enter B
enter C
enter A
leave A
leave C
leave B
leave D
会发现所有父类ABC只执行了一次, 并不像之前那样执行了两次A的初始化.
然后, 又发现一个很奇怪的: 父类的执行是 BCA 的顺序并且是全进入后再统一出去. 这是MRO表问题, 后面继续讨论.
如果没有多继承, super其实和通过父类来调用方法差不多. 但, super还有个好处: 当B继承自A, 写成了A.__init__, 如果根据需要进行重构全部要改成继承自 E,那么全部都得改一次! 这样很麻烦而且容易出错! 而使用super()就不用一个一个改了(只需类定义中改一改就好了)
Anyway, 可以发现, super并不是那么简单.
MRO 表
MRO是什么? 可以通过以下方式调出来:
>>> D.mro() # or d.__class__.mro() or D.__class__.mro(D)
[D, B, C, A, object] >>> B.mro()
[B, A, object] >>> help(D.mro)
#Docstring:
#mro() -> list
#return a type's method resolution order
#Type: method_descriptor
MRO就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表 (类继承顺序表去理解也行) 啦.
这个表有啥用? 首先了解实际super做了啥:
def super(cls, inst):
mro = inst.__class__.mro()
return mro[mro.index(cls) + 1]
换而言之, super方法实际是调用了cls的在MRO表中的下一个类. 如果是简单一条线的单继承, 那就是父类->父类一个一个地下去罗. 但对于多继承, 就要遵循MRO表中的顺序了. 以上面的D的调用为例:
d的初始化
-> D (进入D) super(D,self)
-> 父类B (进入B) super(B,self)
-> 父类C (进入C) super(C,self)
-> 父父类A (进入A) (退出A) # 如有继续super(A,self) -> object (停了)
-> (退出C)
-> (退出B)
-> (退出D)
所以, 在MRO表中的超类初始化函数只执行了一次!
那么, MRO的顺序究竟是怎么定的呢? 这个可以参考官方说明The Python 2.3 Method Resolution Order. 基本就是, 计算出每个类(从父类到子类的顺序)的MRO, 再merge 成一条线. 遵循以下规则:
在 MRO 中,基类永远出现在派生类后面,如果有多个基类,基类的相对顺序保持不变。 这个原则包括两点:
- 基类永远在派生类后面
- 类定义时的继承顺序影响相对顺序.
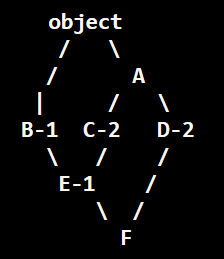
那么MRO是: F -> E -> B -> C -> D -> A -> object
怎么解释呢?
根据官方的方法, 是:
L(O) = O
L(B) = B O
L(A) = A O
L(C) = C A O
L(D) = D A O
L(E) = E + merge(L(B),L(C))
= E + merge(BO,CAO)
= E + B + merge(O,CAO)
= E + B + C + merge(O,AO)
= E + B + C + A + merge(O,O)
= E B C A O
L(F) = F + merge(L(E),L(D))
= F + merge(EBCAO,DAO)
= F + EBC + merge(AO,DAO)
= F + EBC + D + merge(AO,AO)
= F EBC D AO
看起来很复杂..但还是遵循在 MRO 中,基类永远出现在派生类后面,如果有多个基类,基类的相对顺序保持不变。所以, 我个人认为可以这么想:
- 先找出最长深度最深的继承路线
F->E->C->A->object. (因为必然基类永远出现在派生类后面) - 类似深度优先, 定出其余顺序:
F->E->B->obj,F->D->A-object - 如果有多个基类,基类的相对顺序保持不变, 类似于merge时优先提前面的项. 所以排好这些路线: (FEBO, FECAO, FDAO)
F->E->B->obj且E(B,C)决定B在C前面.所以F->E->B->C->A->obj(相当于F+merge(EBO,ECAO)).F->D->A-object且F(E,D)决定了D在E后, 所以D在E后A前. 因为相对顺序, 相当于FE+merge(BCAO, DAO), 所以FE BC D AO
super 是个类
当我们调用 super() 的时候,实际上是实例化了一个 super 类。你没看错, super 是个类,既不是关键字也不是函数等其他数据结构:
>>> class A: pass
...
>>> s = super(A)
>>> type(s)
<class 'super'>
>>>
在大多数情况下, super 包含了两个非常重要的信息: 一个 MRO 以及 MRO 中的一个类。当以如下方式调用 super 时:
super(a_type, obj)
MRO 指的是 type(obj) 的 MRO, MRO 中的那个类就是 a_type , 同时 isinstance(obj, a_type) == True 。
当这样调用时:
super(type1, type2)
MRO 指的是 type2 的 MRO, MRO 中的那个类就是 type1 ,同时 issubclass(type2, type1) == True 。
那么, super() 实际上做了啥呢?简单来说就是:提供一个 MRO 以及一个 MRO 中的类 C , super() 将返回一个从 MRO 中 C 之后的类中查找方法的对象。
也就是说,查找方式时不是像常规方法一样从所有的 MRO 类中查找,而是从 MRO 的 tail 中查找。
举个栗子, 有个 MRO:
[A, B, C, D, E, object]
下面的调用:
super(C, A).foo()
super 只会从 C 之后查找,即: 只会在 D 或 E 或 object 中查找 foo 方法。
多继承中 super 的工作方式
再回到前面的
d = D()
d.add(2)
print(d.n)
现在你可能已经有点眉目,为什么输出会是
self is <__main__.D object at 0x10ce10e48> @D.add
self is <__main__.D object at 0x10ce10e48> @B.add
self is <__main__.D object at 0x10ce10e48> @C.add
self is <__main__.D object at 0x10ce10e48> @A.add
19
下面我们来具体分析一下:
- D 的 MRO 是: [D, B, C, A, object] 。 备注: 可以通过 D.mro() (Python 2 使用 D.__mro__ ) 来查看 D 的 MRO 信息)
- 详细的代码分析如下:
class A:
def __init__(self):
self.n = 2 def add(self, m):
# 第四步
# 来自 D.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @A.add'.format(self))
self.n += m
# d.n == 7 class B(A):
def __init__(self):
self.n = 3 def add(self, m):
# 第二步
# 来自 D.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @B.add'.format(self))
# 等价于 suepr(B, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 B 之后的 [C, A, object] 中查找 add 方法
super().add(m) # 第六步
# d.n = 11
self.n += 3
# d.n = 14 class C(A):
def __init__(self):
self.n = 4 def add(self, m):
# 第三步
# 来自 B.add 中的 super
# self == d, self.n == d.n == 5
print('self is {0} @C.add'.format(self))
# 等价于 suepr(C, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 C 之后的 [A, object] 中查找 add 方法
super().add(m) # 第五步
# d.n = 7
self.n += 4
# d.n = 11 class D(B, C):
def __init__(self):
self.n = 5 def add(self, m):
# 第一步
print('self is {0} @D.add'.format(self))
# 等价于 super(D, self).add(m)
# self 的 MRO 是 [D, B, C, A, object]
# 从 D 之后的 [B, C, A, object] 中查找 add 方法
super().add(m) # 第七步
# d.n = 14
self.n += 5
# self.n = 19 d = D()
d.add(2)
print(d.n)
调用过程图如下:
D.mro() == [D, B, C, A, object]
d = D()
d.n == 5
d.add(2) class D(B, C): class B(A): class C(A): class A:
def add(self, m): def add(self, m): def add(self, m): def add(self, m):
super().add(m) 1.---> super().add(m) 2.---> super().add(m) 3.---> self.n += m
self.n += 5 <------6. self.n += 3 <----5. self.n += 4 <----4. <--|
(14+5=19) (11+3=14) (7+4=11) (5+2=7)

现在你知道为什么 d.add(2) 后 d.n 的值是 19 了吧 ;)
参考
最新文章
- 设计模式03备忘录(java)
- ES6(let 和 const)
- XCode一直显示"scanning for working copies"的解决办法
- The 1st day with Python
- jQuery类级别插件--返回顶部,底部,去到任何部位
- WPF入门学习
- poj 2362
- Python Generators vs Iterators
- Google改变生活
- Hibernate中HQL语句中list与iterate区别
- Guava API学习之Preconditions优雅的检验参数 编辑
- HttpServletRequest 报错 myeclipese支持tomcat
- jquery处理页面元素
- C#中StreamReader读取中文时出现乱码问题总结
- 51 nod 1188 最大公约数之和 V2
- bzoj5248 [2018多省省队联测]一双木棋
- P2440 木材加工(二分+贪心)
- php 对象赋值后改变成员变量影响赋值对象
- Java 多线程 interrupt方法
- 给博客添加fork me on github图标