ElasticSearch(三):通分词器(Analyzer)进行分词(Analysis)
2024-09-01 16:37:12
ElasticSearch(三):通过分词器(Analyzer)进行分词(Analysis)
## Analysis与Analyzer
* Analysis文本分析就是把全文转换成一系列单词的过程,也叫做分词。
* Analysis是通过Analyzer来实现的,它是专门处理分词的组件。可以使用ElasticSearch内置的分词器,也可以按需定制化分词器。
* 除了在数据写入时用分词器转换词条,在匹配查询语句时,也需要用相同的分词器对查询语句进行分析。
Analyzer的组成
分词器是专门处理分词的组件,Analyzer由三个部分组成:
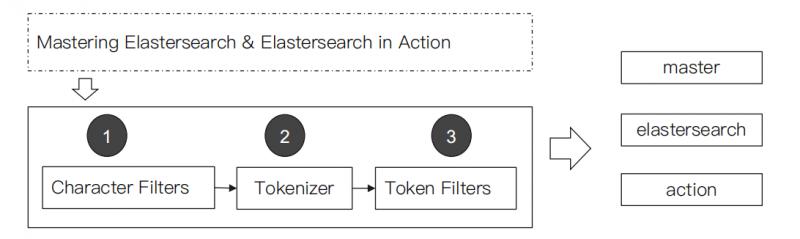
- Character Filters:主要作用是对原始文本进行处理,例如去除HTML标签。
- Tokenizer:主要作用是按照规则来切分单词。
- Token Filter:将切分好的单词进行加工,例如:小写转换、删除停用词、增加同义词。
ElasticSearch的内置分词器
- Standard Analyzer:默认分词器,按词切分,小写处理。
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",#小写处理
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "<ALPHANUM>",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
- Simple Analyzer:按照非字母切分(符号被过滤),小写处理。
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:数字2被过滤,Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
- Stop Analyzer:停用词过滤(is/a/the),小写处理。
#stop
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:2,in,the被过滤,Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
- WhiteSpace Analyzer:按照空格切分,不转小写。
#whitespace
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:按空格切分
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "Quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown-foxes",
"start_offset" : 16,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening.",
"start_offset" : 62,
"end_offset" : 70,
"type" : "word",
"position" : 11
}
]
}
- Keyword Analyzer:不分词,直接将输入当作输出。
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.",
"start_offset" : 0,
"end_offset" : 70,
"type" : "word",
"position" : 0
}
]
}
- Pattern Analyzer:正则表达式分词,默认\W+(非字符分隔)。
#pattern
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 12
}
]
}
- Language:提供了30多种常见语言的分词器。
#english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:running转为run,Quick转为quick,brown-foxes 转为brown、fox,in、the过滤等等
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "run",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "fox",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazi",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "even",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
- Custom Analyzer:自定义分词器。
#需要安装analysis-icu插件
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
#返回结果
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "说的",
"start_offset" : 1,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "确实",
"start_offset" : 3,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "在",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "理",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
中文分词比较:
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
#返回结果
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "说",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "的",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "确",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "实",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "在",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "理",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
最新文章
- Mono 3.2.3 TCP吞吐性能测试报告
- ASP.NET ZERO 学习 HangFire的使用二
- Linux常用命令笔记一
- jq中.prop()与attr()的区别
- Linux Kernel中获取当前目录方法(undone)
- 关于Linux的10个核心面试问题与答案
- SharePoint 2013 网站定义中添加页面布局
- css3 回到顶部书写
- dedecms---------自由列表标题:网站地图自由列表
- Android开源框架之SwipeListView导入及模拟QQ侧滑
- Linux中环境变量到底写在哪个文件中?解析login shell 和 no-login shell
- 在华为oj的两个月
- JavaWeb 后端 <十一> 之 DBUtils 框架 (基本使用 结果集 事务处理 对表读取)
- Android仿淘宝购物车demo
- 问题记录 --Error parsing column 1 (Function_Num=10 - String)”
- MVC四大筛选器—ActionFilter&ResultedFilter
- 最短路(hdu2544)Dijkstra算法二
- js 获取input选择的图片的信息
- JavaScript Event Delegation, and event.target vs. event.currentTarget
- BeautifulSoup使用注意事项
热门文章
- java并发之synchronized详解
- Spring-Data-Jpa使用总结
- Neo4j:图数据库GraphDB(三)创建删除及高级操作
- [Luogu3065][USACO12DEC]第一!First!
- [JZOJ4685] 【NOIP2016提高A组8.12】礼物
- Windows 批量修改文件后缀名
- pycharm中debug的使用
- spark运行java-jar:Exception in thread "main" java.io.IOException: No FileSystem for scheme: hdfs
- 图像配准SIFT
- 最优解的lingo和MATLAB解法