【OS_Linux】三大文本处理工具之grep命令
grep(global search regular expression(RE) and print out the line,整行搜索并打印匹配成功的行
语法:grep [选项] 搜索词 搜索的文件
选项:
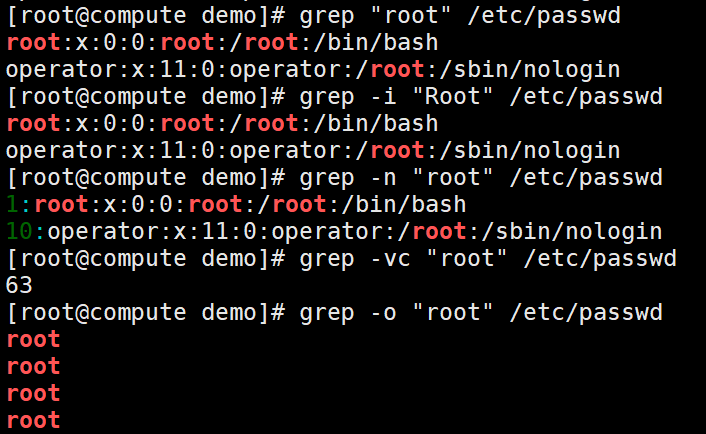
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号(number)
-w :全词(word)匹配,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :统计(count)含有搜索词的行有多少个,仅打印统计的数值而不打印行的内容。注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只(only)显示被匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
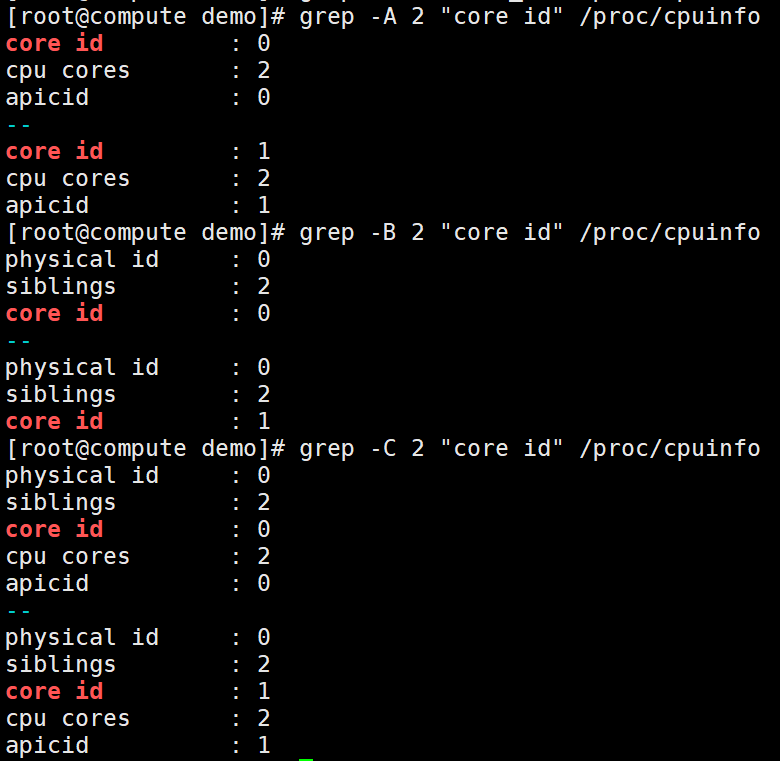
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
-E :开启扩展(Extend)的正则表达式。
示例:
搜索词:
1、直接输入要搜索的字符串,此时可以用fgrep(fast grep)来代替以提高查找速度,比如我要匹配一下hello.c文件中printf的个数:grep -c "printf" hello.c
2、使用正则表达式描述搜索词,下面谈关于基本正则表达式的使用:
字符匹配:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[^123] :反向匹配,这个字符不能是1、2、3中的任意一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]

次数匹配:
x\{m\}:m 个连续的字符x
x\{m,\}:m个以上连续的字符x
x\{m,n\}:m~n个连续的字符x
x*:连续任意个字符x,例如: /[abc] */表示abc中任意字符的若干次
位置匹配:
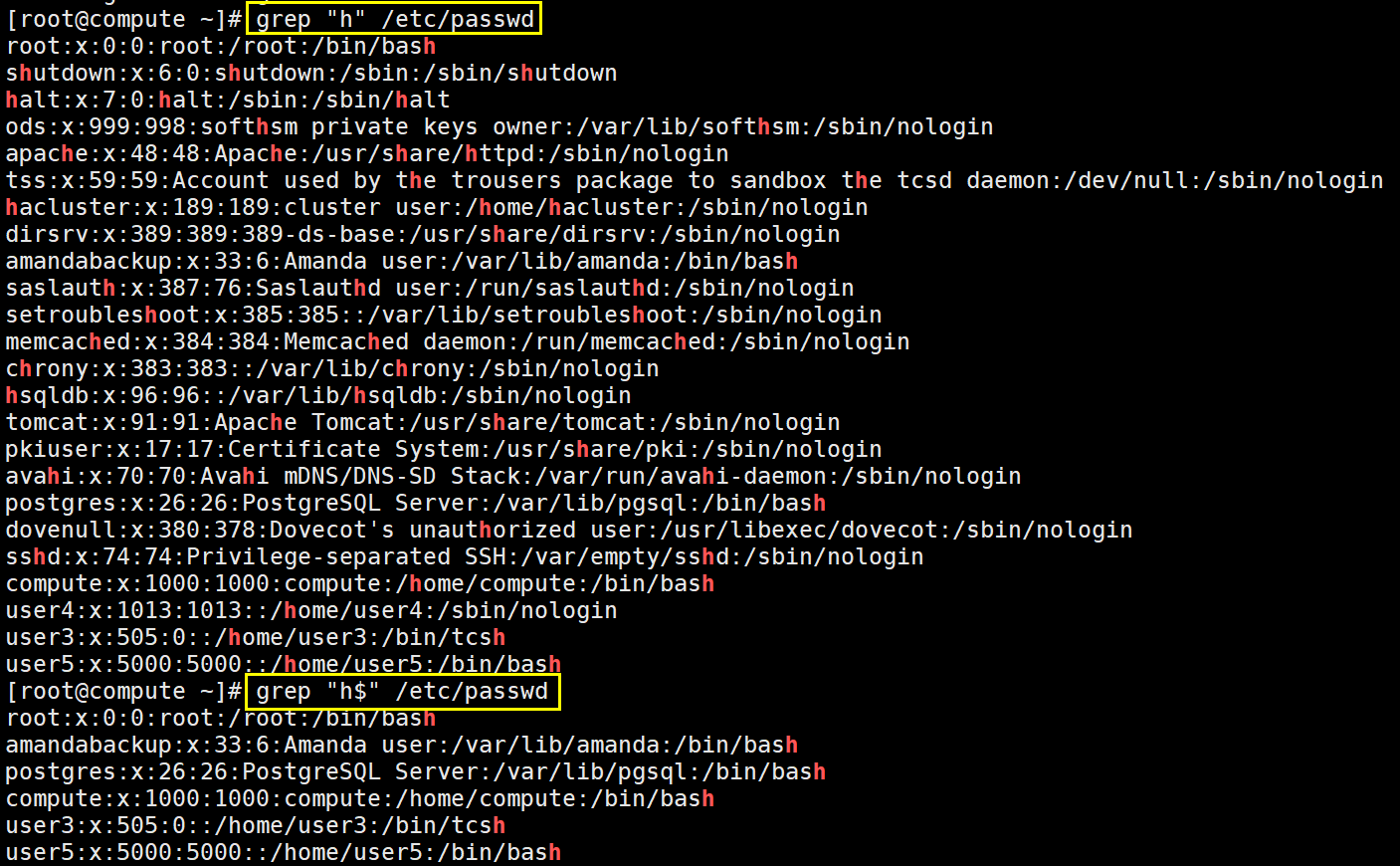
^ :锚定行首
$ :锚定行尾。技巧:"^$"用于匹配空白行。
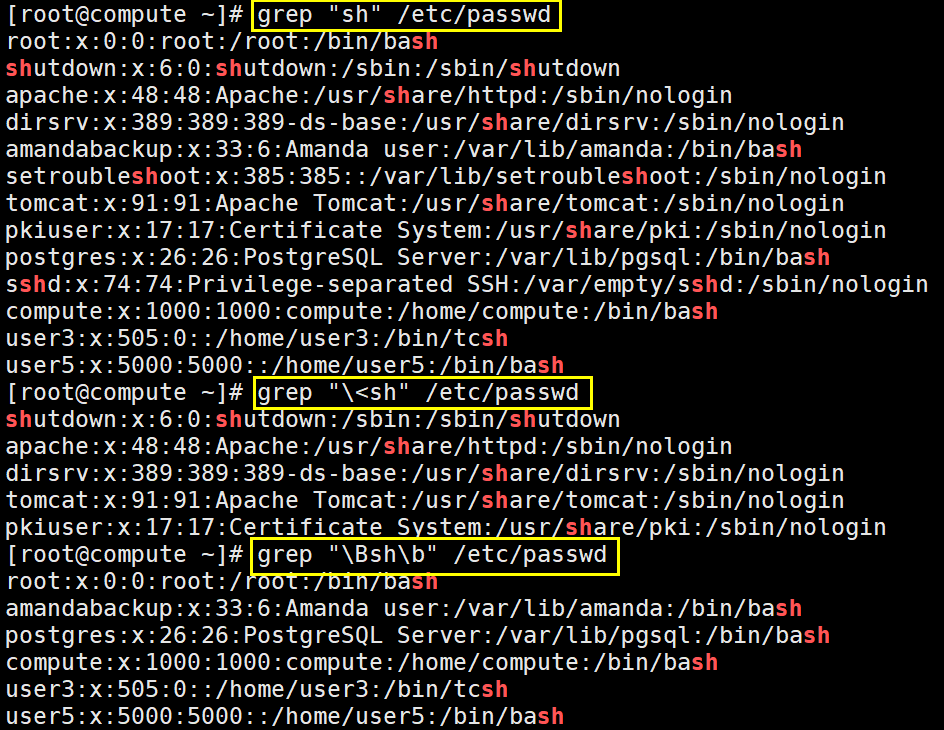
\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b待匹配的字符串\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
本博客参照与:linux中grep命令的用法
最新文章
- [AngularJS] AngularJS系列(3) 中级篇之表单验证
- 【转】windows环境下安装win8.1+Mac OS X 10.10双系统教程
- PL/SQL Developer连接本地64位Oracle数据库
- 《Head First Servlet JSP》学习笔记二
- Composite模式
- ASP.net MVC自定义错误处理页面的方法
- PDA移动开单系统-PDA开单,手机开单,开单APP,移动开单,移动POS开单
- 最牛叉的街机游戏合集 & 模拟器
- bzoj 2286: [Sdoi2011消耗战
- Max Sub-matrix
- javascript 第26节 jQuery对象
- java中对象的转型
- 利用自定义View实现扫雷游戏
- rabbitMq及安装、fanout交换机-分发(发布/订阅)
- 新式类单例模式之 __new__()
- s6 传输层
- spring boot启动后执行方法
- sourceInsight工具移除不掉项目 source Insight Add and Remove Project Files
- Redis进阶实践之五Redis的高级特性(转载 5)
- java代码分页