深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
2024-08-28 17:02:33
下面来看看groupByKey和reduceByKey的区别:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
val sc = new SparkContext(conf)
val words = Array("one", "two", "two", "three", "three", "three")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))
val wordsCountWithReduce = wordsRDD.
reduceByKey(_ + _).
collect().
foreach(println)
val wordsCountWithGroup = wordsRDD.
groupByKey().
map(w => (w._1, w._2.sum)).
collect().
foreach(println)虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
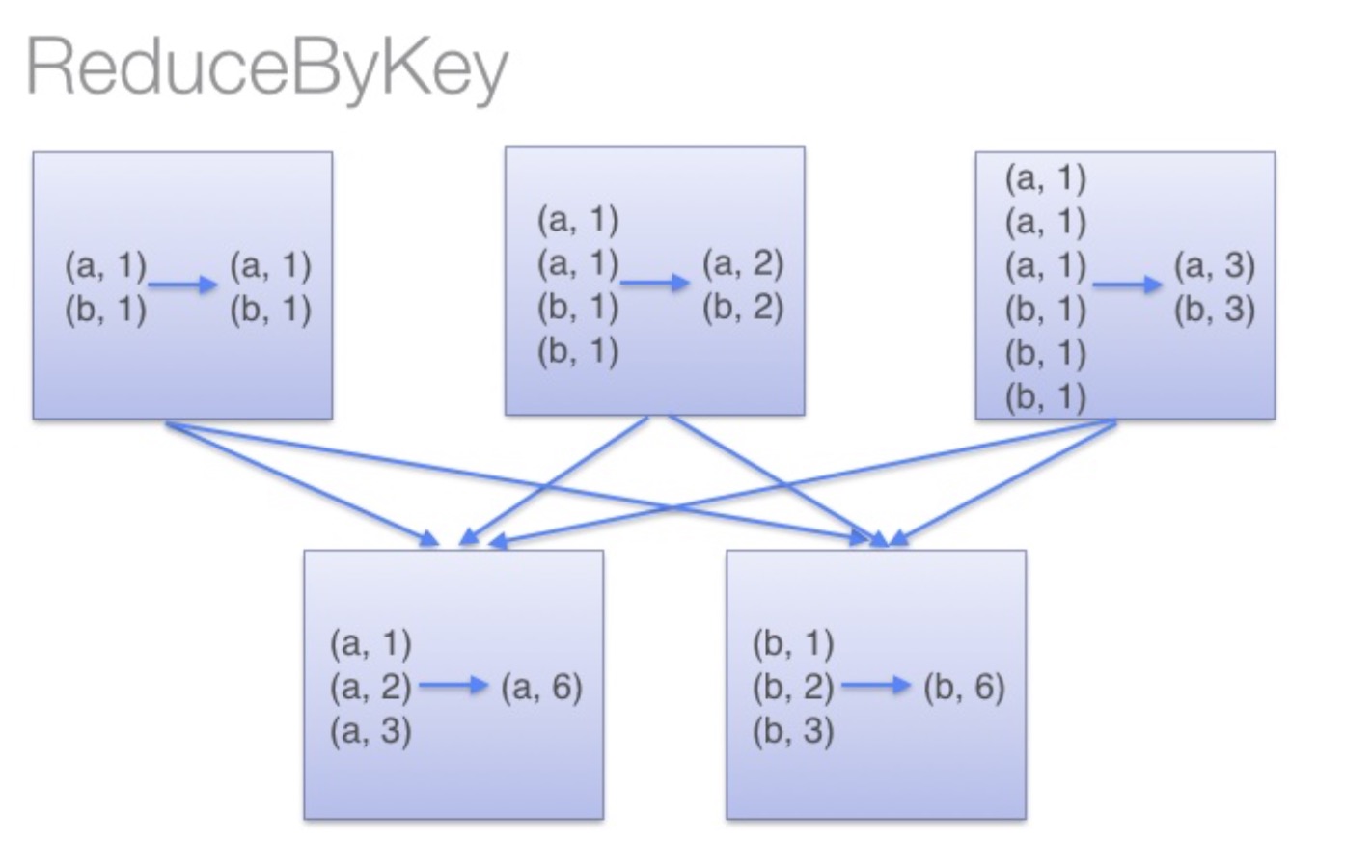
image
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的key调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时Spark会把数据保存到磁盘上。 不过在保存时每次会处理一个key的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
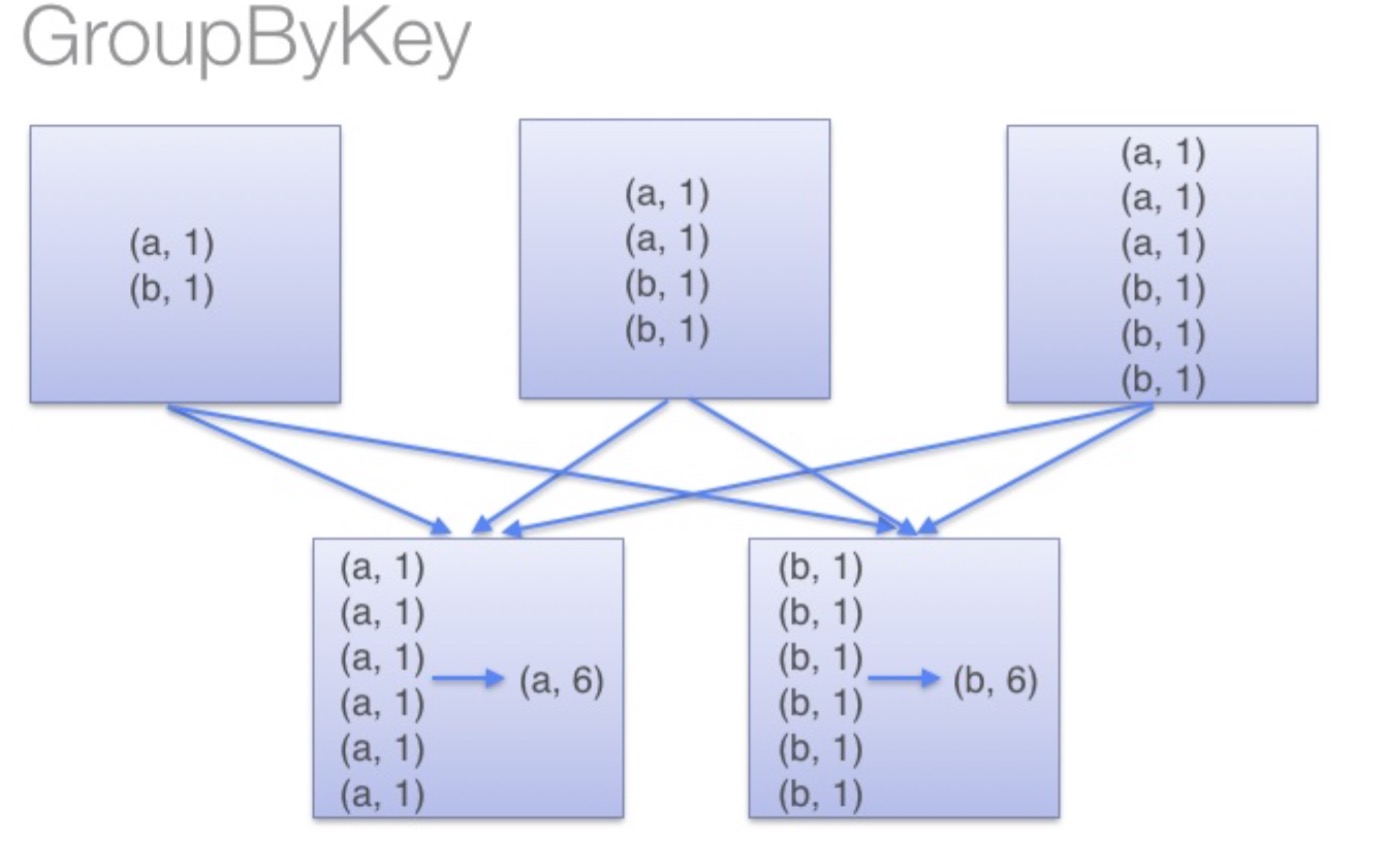
image
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
摘自:http://www.jianshu.com/p/0c6705724cff
最新文章
- (原) 2.2 ZkClient使用
- initrd image比lvm.conf文件舊導致RHCS切換服務unmount failed,reboot
- ural Cipher Message
- JAVA线程同步辅助类CountDownLatch
- PHP XML笔记汇总
- PyBayes的安装和使用
- nginx与ios实现https双向认证
- SQL查询今天、昨天、7天内、30天
- Ubuntu14.04安装samba
- 纯JS.CSS编写的可拖拽并左右分栏的插件(复制代码就能用)
- 读书笔记--Android Gradle权威指南(上)
- Jenkins+PowerShell持续集成环境搭建(八)邮件通知
- IDEA文件对比
- python----运算符、布尔值
- 比较好的一些 ConcurrentHashMap讲解博客
- avalon2学习教程06样式操作
- nginx lua集成
- python自学——列表
- python基础学习5----字典
- 使用OAuth Server PHP实现OAuth2服务