HDFS02
2024-09-07 17:53:07
读取流程

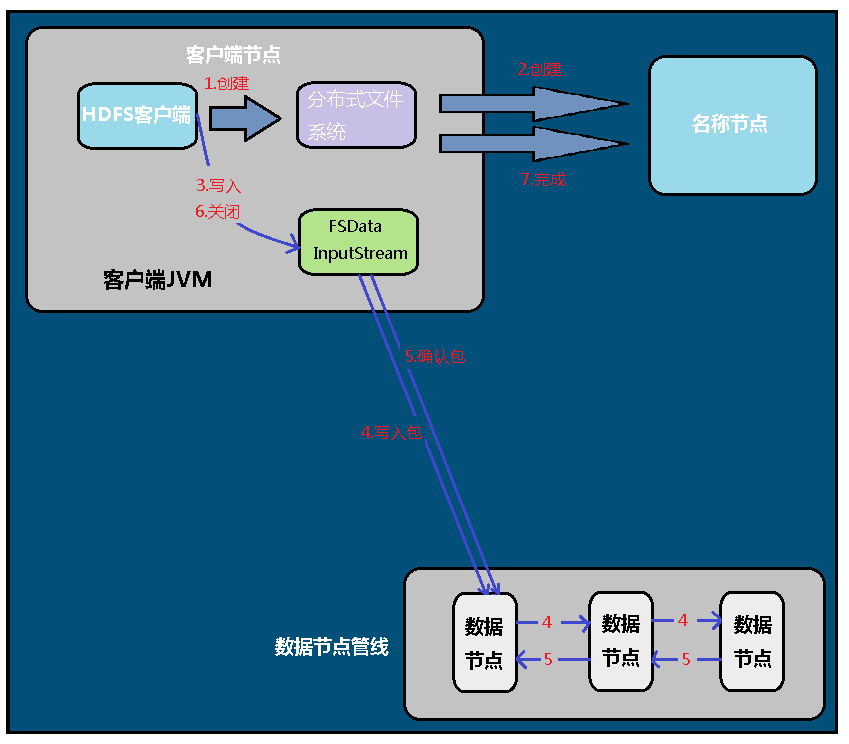
写流程
============SecondaryNameNode============
Namenode的一个快照
周期性的备份namenode
记录namenode中的metadata及其它数据
可以用来恢复Namenode
============HDFS优点============
高容错性 --------->
√数据自动保存多个节点
√备份丢失后,自动恢复
适合批处理 --------->
√移动计算而非数据
√数据位置暴露给计算框架
合适大数据处理 --------->
√GB、TB、甚至PB级数据
√百万规模以上的文件数量
√ 10K+节点规模
流式文件访问 --------->
√一次性写入、多次读取
√保证数据的一致性
可构建在廉价的机器上 --------->
√通过多副本提高可靠性
√提供了容错和恢复机制
============HDFS缺点============
低延迟数据访问 --------->
√比如毫秒级
√低延迟与高吞吐率
小文件存取 --------->
√占用NameNode大量内存
√寻道时间超过读取时间
并发写入、文件随时修改 --------->
√一个文件只能有一个写者
√仅支持append
最新文章
- .net中事件引起的内存泄漏分析
- eclipse构建maven+scala+spark工程 转载
- shell脚本调试
- 修改Android签名证书keystore的密码、别名alias以及别名密码
- BestCoder16 1002.Revenge of LIS II(hdu 5087) 解题报告
- robot API笔记1
- Jetty提交数据时报java.lang.IllegalStateException: Form too large270468>200000问题解决
- 关于Java序列化和Hadoop的序列化
- SQL Server 行的删除与修改-------------(未完待续P222 deep SQL Server 222 )
- 【Python之路】第七篇--Python基础之面向对象及相关
- 在Linux环境如何在不解压情况下搜索多个zip包中匹配的字符串内容
- maven项目如何手动打包
- GMT\UTC YYYY-MM-DDTHH:mm:ss.sssZ、YYYY-MM-DDTHH:mm:ss.sss+8:00意义及与北京时间转换
- 实现一个simple 3层的神经网络
- 【详记MySql问题大全集】一、安装MySql
- luogu3188/bzoj1190 梦幻岛宝珠 (分层背包dp)
- GNOME 3.28 启用桌面图标
- SqlServer 2008的tempdb数据文件大小暴增处理
- Top useful .Net extension methods
- Zookeeper 系列(一)基本概念