Pyspider爬虫简单框架——链家网
2024-08-31 03:49:55
pyspider
目录
pyspider简单介绍
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,
强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
官方文档: http://docs.pyspider.org/en/latest/
开源地址: http://github.com/binux/pyspider
中文文档: http://www.pyspider.cn/
pyspider框架的特性
- python脚本控制,可以使用用任何你喜欢的html解析包(内置pyquery)
- WEB界面编写调试脚本,启停脚本,监控执行状态,查看活动内容,获取结果产出
- 数据库存储支持MySQl,MongoDB,Redis,SQLite,Elasticsearch,PostgreSQL及SQLAlchemy
- 队列服务支持RabbitMQ,Beanstalk,Redis和Kombu
- 支持抓取JavaScript的页面
- 组件可替换,支持单机/分布式部署,支持Docker的部署
- 强大的调度控制,支持超时重爬及优先级设置
- 支持python2&3
pyspider的安装
pip install pyspider
- 安装完成后运行,在cmd窗口输入pyspider

pyspider的使用:
- 在浏览器中输入最后一行的IP和端口号。
- 在web控制台点create按钮新建项目。

- 保存后打开代码编辑器(代码编辑器默认有简单的示例代码)
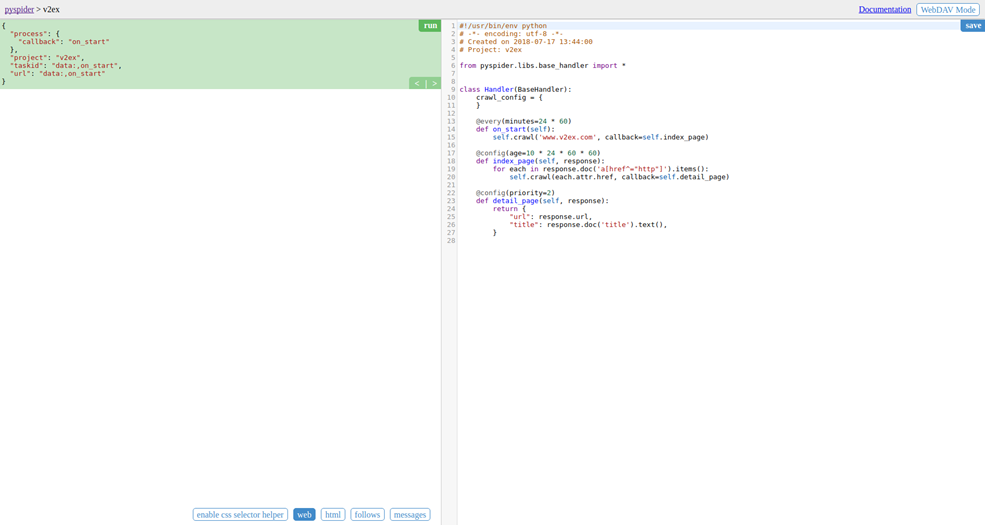
- 右侧就是代码编辑器,,以后可以直接在这里添加和修改代码。代码如下:

代码分析:
- def on_start(self)方法是入口代码。当在web控制台点击run按钮时会执行此方法。
- self.crawl(url, callback=self.index_page)这个方法是调用API生成一个新的爬虫任务,这个任务被添加到待爬取队列
- def index_page(self.response)这个方法获取一个response对象。response.doc是pyquery对象的一个扩展方法。pyquery是一个类似于jquery的对象选择器。
- def detail_page(self, response)返回一个结果即对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。也可以重写on_result(self, result) 方法来指定保存位置。

- 当完成脚本编写,调试无误后,请先保存脚本,然后返回控制台首页
- 直接点击项目状态status那栏,把状态由TTODO改成debug或running
- 最后点击项目最右边那个RUN按钮启动项目

- 当progress那栏有数据显示说明启动成功。就可以点击右侧的result查看结果了
技巧:
- pyspider访问https协议得网站是,会提示证书问题,需要设置validate_cert = False,屏蔽证书验证
- 预览网页得时候,可能会出现空白页面,是因为pysipder不加载JavaScript代码,用fetch_type='js',pyspider会自动调用phantomjs来渲染网页。前提是电脑上已经安装了phantomls.exe插件
- 当需要删除项目时,将status状态改成STOP,再将group写上delete,pyspider默认在STOP的delete状态下保存24小时后删除

enable css selector helper可以在点击了web 的网页预览下,获取网页的css选择器

点击图片箭头的按键,就会生成对应css选择器在光标所在的位置处
- follows是根据代码请求所跟进的url链接,点击
 实现网页跳转
实现网页跳转 - 当代码调试出错的时候,要回到最初的首页开始重新调试

实战
爬取链家网的信息:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-11-02 10:54:11
# Project: ddd from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60) # 设置爬取的时间间隔
def on_start(self):
self.crawl('https://cs.lianjia.com/ershoufang/', callback=self.index_page, validate_cert = False) # 参数三是设置不验证ssl证书 @config(age=10 * 24 * 60 * 60) # 过期时间
def index_page(self, response):
for each in response.doc('.title > a').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert = False) @config(priority=2) # 优先级 数大极高
def detail_page(self, response):
yield {
'title': response.doc('.main').text(),
'special': response.doc('.tags > .content').text(),
'price': response.doc('.price > .total').text(),
'sell point': response.doc('.baseattribute > .content').text()
}
结果:分别爬取了卖房的标题(title),特点(special),卖点(sell point)和价格(price),因为字典保存,所以无序

最新文章
- js-Event构造函数,也许你需要
- JavaScript学习02 基础语法
- SVG 2D入门11 - 动画
- NodeJS的小应用
- IT人的自我导向型学习:学习的4个层次
- Android的主要组件
- 给windows 7安装文件添加USB3.0驱动
- Objective-C中的Block
- [置顶] Android框架攻击之Fragment注入
- Cordova各个插件使用介绍系列(五)—$cordovaGeolocation获取当前位置
- CSS3实现轴心为x轴的3D数字圆环
- 最简单的SpringBoot整合MyBatis教程
- 纯css实现checkbox开关切换按钮
- Jenkins环境搭建(4)-配置定时构建
- 20190323——HeadFirestPython学习之异常处理
- php获取ip地址所在的地理位置的实现
- threading.local学习
- Redis入门指南之三(入门)
- unity中手机触摸代码
- 安装google 框架