Elasticsearch状态API接口排障总结
ES的Restful API,共四类API:
1. 检查集群、节点、索引等健康与否,以及获取其相应状态。
2. 管理集群、节点、索引及元数据
3. 执行CRUB操作(即:增删查改)
4. 执行高级操作,如:paging,filtering等。 ES API的访问接口: TCP:9200,并且ES是基于HTTP协议工作的. curl -X <Verb> '<Protocol>://Host:Port/<Path>?<Query_String>' -d '<Body>' 注:
Verb: 即HTTP的操作,GET, PUT, DELETE等.
Protocol: http,https
Path: 访问路径.
Query_String:查询参数,如: '?pretty':表示使用容易读的JSON格式显示输出.
Body:请求的主体。 如查看node1的状态:
curl -X GET 'http://1.1.1.1:9200/?pretty' ES的API接口: _cat API:
查看ES集群的状态:
curl -X GET 'http://1.1.1.1:9200/_cat/nodes?v'
注:
_cat: 这是ES的API接口名,一般ES的API接口名使用下划线开头.
此接口的功能是输出显示的。
?v: 问号v,是修饰符,v:是verbose,显示详情。
?help: 可显示帮助信息。
?h=name,ip,port,uptime,heap.current :可定义显示那些列.
curl -XGET 'http://1.1.1.1:9200/_cat/indices' #查看ES集群中所有的索引信息
curl localhost:9200/_cat/indices?s #默认可省略s,s: status
curl localhost:9200/_cat/indices?help #可查看支持的查询关键字 _cluster APIs:
查看ES集群健康状态详情:
curl -X GET 'http://1.1.1.1:9200/_cluster/health?pretty' 查看索引的健康状态:
health
curl -X GET 'http://1.1.1.1:9200/_cluster/health/索引名1,索引名2,...'
curl -X GET 'http://1.1.1.1:9200/_cluster/health/索引名1?level=Level'
注:
cluster:显示到集群级别
indices:显示到索引级别
shards:分片级别 查看集群的状态信息:
state:
curl -X GET 'http://1.1.1.1:9200/_cluster/state/version' curl -X GET 'http://1.1.1.1:9200/_cluster/state/master_node?pretty'
curl -X GET 'http://1.1.1.1:9200/_cluster/state/nodes?pretty' 查看集群的统计数据:
stats:
curl -X GET 'http://1.1.1.1:9200/_cluster/stats?pretty'
查看集群节点状态信息:
# curl 192.168.10.80:9200/_cat/nodes?v
堆内存% 总内存% CPU 1分钟 5分钟 15分钟 角色 *:主节点 节点名
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.2.2.81 14 87 0 0.14 0.12 0.11 mdi - node81
10.2.2.80 27 95 0 0.02 0.02 0.00 mdi * node80 # curl 192.168.10.80:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1564141337 11:42:17 myes1 green 2 2 40 20 0 0 0 0 - 100.0% # 下面可以看当前所有Index(索引)的状态统计,通过它,可获取当前ES集群中是否有red 或 yellow的Index,若有,
则需要通过下面的 _cluster/health?level=indices&pretty 来具体查看该Index分片的详细信息。
curl 192.168.10.80:9200/_cat/indices?v

#查看Index分片的状态信息
# curl "localhost:9200/_cluster/health?level=indices&pretty"
{
"cluster_name" : "myes1",
"status" : "green", #整个ES集群的状态为green,是因为下面所有Index的状态为green,若其中有任何一个Index的状态非Green,则整个ES的状态将会非Green。
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 20,
"active_shards" : 40,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0,
"indices" : {
".kibana_task_manager" : {
"status" : "green", #当前.kibana_task_manager这个Index的状态为green。
#通常若Index的分片出现丢失,状态将会是red或yellow:
#red:则表示有一个主分片丢失! yellow:则表示一个副本分片丢失!!但主分片依然可读
"number_of_shards" : 1, #shard的数量为1,即分片为1个
"number_of_replicas" : 1, #副本分片数为1,副本分片数决定了shard的个数,若shard个数与它不相同,则该Index的状态一定不是green:
"active_primary_shards" : 1, #当前活动的主分片数量
"active_shards" : 2, #这是当前所有活动的分片数量
"relocating_shards" : 0, #正在调度分配的分片个数【根据字面理解,不完全正确】
"initializing_shards" : 0, #正在初始化分片的个数
"unassigned_shards" : 0 #未分配的分片个数
},
...........................
#查看shard分片中那个分片没有分配,以及它在那个Node上丢失分片了
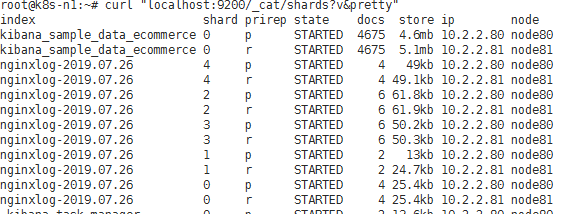
# curl "localhost:9200/_cat/shards?v&pretty"
# shard: 它表示index的分片编号
# prirep: 这是主分片和副本分片,其中:p: 表示主分片, r:表示副本分片
# state: 这个状态可能有这几种: relocating,initializing ,Started, unassigned ,其中unassigned 这表示未分配,若是这种状态,就需要注意了。
# docs 和 store: 就是此Index下文档数量和该docs所占的磁盘空间大小。
ElasticSearch集群出现Red 和 Yellow状态的原因
参考链接:https://www.jianshu.com/p/74fe89ab4af7
集群 RED 和 YELLOW 是 Elasticsearch 集群最常见的问题之一.
无论 RED 还是 YELLOW,原因只有一个:有部分分片没有分配,而且那怕只有一个也会导致集群故障。
red:则表示有主分片没有分配!
yellow:则表示有副本分片没有分配!!但主分片依然可读
对于集群 RED 或 YELLOW 的问题诊断推荐使用 Cluster Allocation Explain API,该 API 可以给出造成分片未分配的具体原因。
例如,如下请求可以返回第一个未分配的分片的具体原因:
curl -XGET localhost:9200/_cluster/allocation/explain?pretty
集群 RED 或 YELLOW 时,一般我们首先需要看一下是否有节点离线。
但单个的未分配分片也导致集群状态变为 RED 或 YELLOW,一些常见的未分配原因如下:
• 由于配置问题导致的,需要修正相应的配置
• 由于节点离线导致的,需要重启离线的节点
• 由于分片规则限制的,例如 total_shards_per_node,或磁盘剩余空间限制等,需要调整相应的规则
• 分配主分片时,由于找不到最新的分片数据,导致主分片未分配,这种要观察是否有节点离线,
极端情况下只能手工将旧的副本分片修改为主分片,但这会导致丢失一些新入库的数据。
# curl "localhost:9200/_cat/shards?v&pretty" | grep unassingned
#若上面查询中出现了 unassingned ,则可通过,下面命令来查看 该index的分片是什么原因导致未分配
curl -sXGET localhost:9200/_cluster/allocation/explain?pretty -d '{
"index":"myindex", #可指定index名
"shard":3, #指定要查看的Shard(分片)编号
"primary":true
}'
#若输出结果为:
{
"index" : "myindex",
"shard" : 0,
"primary" : true,
"current_state" : "unassigned",
..............
},
"can_allocate" : "no_valid_shard_copy",
"allocate_explanation" : "cannot allocate because all found copies of the shard are either stale or corrupt",
#无法分配,因为所找到的分片的所有副本都已陈旧或损坏
...........................
#这种错误可理解为:
Elasticsearch 找到了这个分片在磁盘中的数据,但是由于分片的数据不是最新的,无法将其分配为主分片。 分配分片的方法
若知道哪个索引的哪个分片丢失或损坏,就开始手动修复,通过reroute的allocate分配
curl -XPOST '{ESIP}:9200/_cluster/reroute' -H "content-type: application/json" -d '{
"commands" : [ {
"allocate" : {
"index" : "eslog1",
"shard" : 4,
"node" : "es1",
"allow_primary" : true
}
}
]
}'
分配时可能遇到的坑,需要注意的地方
分配副本时必须要带参数"allow_primary" : true, 不然会报错
当集群中es版本不同时,如果这个未分配的分片是高版本生成的,不能分配到低版本节点上,反过来低版本的分片可以分配给高版本,
如果遇到了,只要升级低版本节点的ES版本即可
(升级ES版本详见官方详细文档,我是ubuntu系统apt安装的,直接apt-get install elasticsearch升级的,elasticsearch.yml
配置文件没变不用修改,但是/usr/share/elasticsearch/bin/elasticsearch文件中有个内存配置ES_HEAP_SIZE=6G需要再手动加一下&重启es)
【摘自网络】
#分片没有被分配的最初原因有下列类型:
1. INDEX_CREATED
由于 create index api 创建索引导致,索引创建过程中,把索引的全部分片分配完毕需要一个过程,
在全部分片分配完毕之前,该索引会处于短暂的 RED 或 YELLOW 状态。因此监控系统如果发现集群 RED,不一定代表出现了故障。
2. CLUSTER_RECOVERED
集群完全重启时,所有分片都被标记为未分配状态,因此在集群完全重启时的启动阶段,reason属于此种类型。
3. INDEX_REOPENED
open 一个之前 close 的索引, reopen 操作会将索引分配重新分配。
4. DANGLING_INDEX_IMPORTED
正在导入一个 dangling index,什么是 dangling index?
磁盘中存在,而集群状态中不存在的索引称为 dangling index,例如从别的集群拷贝了一个索引的数据目录到当前集群,
Elasticsearch 会将这个索引加载到集群中,因此会涉及到为 dangling index 分配分片的过程。
5. NEW_INDEX_RESTORED
从快照恢复到一个新索引。
6. EXISTING_INDEX_RESTORED,
从快照恢复到一个关闭状态的索引。
7. REPLICA_ADDED
增加分片副本。
8. ALLOCATION_FAILED
由于分配失败导致。
9. NODE_LEFT
由于节点离线。
10. REROUTE_CANCELLED
由于显式的cancel reroute命令。
11. REINITIALIZED
由于分片从 started 状态转换到 initializing 状态。
12. REALLOCATED_REPLICA
由于迁移分片副本。
13. PRIMARY_FAILED
初始化副分片时,主分片失效。
14. FORCED_EMPTY_PRIMARY
强制分配一个空的主分片。
15. MANUAL_ALLOCATION
手工强制分配分片。
最新文章
- 3D拓扑自动布局之Node.js篇
- django字段设置null和blank的区别
- 深入理解Redis:底层数据结构
- 抢滩登陆游戏android源码
- LeetCode_ 4 sum
- python学习之 dictionary 、list、tuple操作
- PHP 获取linux服务器性能CPU、内存、硬盘、进程等使用率
- 第八章 关于SQL查询出错的一些问题
- 安装Mycat 曾经踩的那些坑
- Mybatis Generator 生成的mapper只有insert方法
- 一道题引发的self和super
- python中 =、copy、deepcopy的差别
- Oracle导出DMP文件的两种方法
- 001-mybatis框架
- thinkphp整合系列之phpexcel导入excel数据
- Linux高级编程--02.gcc和动态库
- JavaScript的this指针到底指向哪?
- 倍福TwinCAT(贝福Beckhoff)常见问题(FAQ)-PLC支持哪些PLC语言类型
- 傻瓜方法求集合的全部子集问题(java版)
- 算法 & 数据结构——收纳箱算法???