Python基础学习总结(持续更新)
https://www.cnblogs.com/jin-xin/articles/7459977.html
嗯,学完一天,白天上班,眼睛要瞎了= =
DAY1
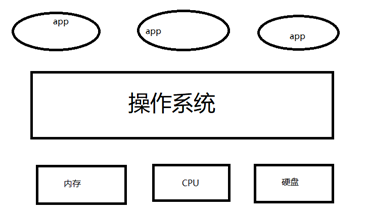
1,计算机基础。
CPU:相当于人的大脑,用于计算
内存:储存数据,成本高,断电数据即消失
硬盘:1T,固态硬盘,机械硬盘,储存数据,应该长久保持数据,重要文件
操作系统:下达命令
应用程序:在操作系统上运行
2,python历史。
宏观上:python2 与 python3 区别:
python2 源码不标准,混乱,重复代码太多,
python3 统一 标准,去除重复代码。因为:Python崇尚优美、清晰、简单
3,python的环境。
编译型:一次性将所有程序编译成二进制文件。
缺点:开发效率低,不能跨平台。
优点:运行速度快。
:C,C++等等。
解释型:当程序执行时,一行一行的解释。
优点:开发效率高,可以跨平台。
缺点:运行速度慢。
:python ,php,等等。
4,python的发展。
5,python种类。
Cpython是官方认可的Python解释器,将Python规范语言解释成C语言能识别的字节码,再转换成二进制的机器码交由操作系统处理,这也是课程学习的语言。
Jpython将Python规范语言解释成java语言能识别的字节符,再转换成二进制的机器码交由操作系统处理。
Pypy,一次性全部编译成字节码,运行速度快,开发效率相对低。
其他语言解释器。
运行第一个py文件:
python3x :python 文件路径 回车
python2x :python2 文件路径 回车
python2 python3 区别:python2默认编码方式是ascii码,直接print中文就会报错
解决方式:在文件的首行加:#-*- encoding:utf-8 -*-
python3 默认编码方式utf-8
6,变量。
变量:就是将一些运算的中间结果暂存到内存中,以便后续代码调用。
规范:1,必须由数字,字母,下划线任意组合,且不能数字开头。
2,不能是python中的关键字。
关键字:['and', 'as', 'assert', 'break', 'class', 'continue',
'def', 'del', 'elif', 'else', 'except', 'exec',
'finally', 'for', 'fro', 'global', 'if', 'import',
'in', 'is', 'lambda', 'not', 'or', 'pass', 'print',
'raise', 'return', 'try', 'while', 'with', 'yield']
3,变量命名具有可描述性。官方推荐:age_of_oldboy=17
4,不能是中文。
7,常量。
一直不变的量。 π
全部大写:就是常量BIR_OF_CHINA = 1949
8,注释。
方便自己方便他人理解代码。
单行注释:#
多行注释:'''被注释内容''' """被注释内容"""
9,用户交互
Input 输入

1,等待输入,
2,将你输入的内容赋值给了前面变量。
3,input出来的数据类型全部是str
10,基础数据类型初始。
数字:int 12,3,45
+
、-、 *、 /、 **次幂
%
取余数
判断数据的类型:type()
字符串转化成数字:int(str)
条件:str必须是数字组成的。
数字转化成字符串:str(int)
字符串:str,python当中凡是用引号引起来的都是字符串。
(1)可相加:字符串的拼接。

(2)要打印内容中有换行符必须用’’’ 引起来

(3)数字和字符串可相乘:str
* int

bool:布尔值。 True
False。And、or、<、>、==
Print(True,type(True))
Print(‘True’,type(‘True’))
11,if。
语法:必须有缩进来判断是否属于一段代码
if 条件:
(tab 键)结果1
if
条件:(嵌套)
(tab
键)结果1.1
Elif 条件:
(tab
键)结果1.2
Elif条件:
(tab 键)结果2
else:
(tab 键)结果3
12,while。
条件后必须加:就是为了提示python,while到冒号之间的这段为条件。
while 条件:
(tab键) 循环体
(tab键)无限循环(条件恒为真)。
终止循环:1,改变条件,使其不成立。
2,break
Continue
结束本次循环,开始下次循环
DAY2
1.pycharm
Ctrl+/ 即为快速注释,run、debug加断点都很方便
2.格式化输出
%为占位符,s为字符串,d为digit数字
想要在格式化输出中表示单纯的百分号,那么就在%前面再加一个%进行转义,即可达到目的
name = input('请输入姓名')
age = int(input('请输入年龄'))
height = input('请输入身高')
rank = input('请输入年级排名百分之几,只需数字即可')
msg = '我叫%s,今年%d,身高%s,年级排名前%s%%' %(name , age , height , rank)
print(msg)#要记得打印才看得到结果
"""格式化输出中包含',那么注释时候用双引号注释
name = input('请输入姓名')
age = input('请输入年龄')
job = input('请输入工作')
hobbie = input('请输入兴趣爱好') msg = '''------------ info of %s -----------
Name : %s
Age : %s
Job : %s
Hobbie: %s
------------- end -----------------''' %(name , name , age , job , hobbie)#按顺序替换
print( msg )
"""
3.while else
当while 循环被break打断,就不会执行else的语句
4.初始编码
电脑的传输还有储存的实际上都是二进制数位
ASCII码最开始是7位,包含128种可能,能满足美国本土的所有编码需要,在最左边预留了一位,全都是0,以便以后拓展,所以一共八位,八位为一个bit==一个字节(byte)
1024BYTE(字节)== 1KB
1024KB == 1MB
1024MB == 1GB
1024GB == 1TB
美国为了解决这个编码全球使用的问题,创建了一个万国码(Unicode)
最开始:
1) 1个字节可以表示所有的英文,特殊字符,数字等等
2) 2个自己,16位表示一个中文,不够,Unicode设计一个中文用四个字节表示,32位, 可是17位就可以满足目前中文的所有需要,那么32位就实在太浪费了,会白白占用很多存储空间。
3) 为了解决这个问题UTF编码浪费,升级版Unicode(UTF-8)一个中文用三个字节表示,24位,有研究表示,21位(2的21次方个)就能包含世界上有史以来的所有符号个数。由此可见,在使用python2版本的时候打印中文会报错,是因为python2默认用ASCII码编码,那么就不包含中文的编码,而加上#-*- encoding:utf-8 -*-将编码方式变成utf-8后就不会报错了。
4) GBK编码方式是中国人自己创建的,只包含中文和英文的编码,只在国内使用,一个中文用2个字节表示(包含不全,中文9万多字,至少需要17位二进制码表示)
5.运算符
https://www.cnblogs.com/jin-xin/articles/7459977.html
参见python基础一-三-10,基本运算符
在python2.6以前的版本用<>表示不等于,之后的版本都只用!=表示不等于
逻辑运算的优先级顺序:() > not > and > or
#运算优先级: () > not > and > or
# print(3>4 or 4<3 and 1==1)#F
# print(1 < 2 and 3 < 4 or 1>2)#T
# print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1)#T
# print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)#F
# print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)#F
# print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7
< 6)#F,注意前面的not
# x、y均为数字,x or y时,从左至右返回遇到的第一个非零数字;
x and y时,有一个数为零,全部为0;若全非零,取最小值。
print(1 or 2)#1
print(2 or 1)#2
print(0 and 3)#0
print(3 or 0)#3
print(100 or 0)#100
print(0 or 100)#100
print(1 or 100)#1
print(100 or 1)#100
print(100 and 1)#1
print(2 or 1 < 3)#2
print(1 > 2 and 3 or 4
and 3 < 2)#False
print(2 and 1<3 and 1)#1
6.基础数据类型补充
数值型(int)转换成布尔型(bool):非零数字转换成BOOL
TURE, 零转换成BOOL
FALSE.
Print(bool(数值))
Print(int(TRUE/FALSE))#0/1
DAY3
数据类型详解
https://www.cnblogs.com/jin-xin/articles/7562422.html
什么是数据类型
1) Int:整数型,1,2,3….用于计算
2) Bool:布尔型,True,False,用于判断
3) Str:字符串,存储少量数据,进行操作
4) List:表单型,存储大量任何数据,查询简单
5) 元祖tuple:只读型列表,存储大量任何数据
6) Dict:字典,也可以存储大量数据,基本都是关系型数据,一个对象的各种信息集中在其中,查询速度快
7) 集合set:高中数学当中的求交集和并集。
各种数据类型举例:
int 1,2,3用于计算。
bool:True,False,用户判断。
str:存储少量数据,进行操作
'fjdsal' '二哥','`13243','fdshklj'
'战三,李四,王二麻子。。。。'
list:储存大量的数据。
[1,2,3,'泰哥','12353234',[1,2,3]]
元祖:只读。
(1,2,3,'第三方',)
dict:字典{'name':'云姐','age':16}
字典{'云姐':[],'二哥':[200,200,200,。。。。。。]}
集合:{1,2,34,'asdf'}
1. Int
用于计算。
Bit_length将数值转换成最小位数的二进制长度。
2. Bool
用于判断。1比true的效率更高;非空字符串就是TRUE
3. Str
用’ ’引号引起来的内容,存储少量数据,用于操作。
1) 索引,取单个元素
字符串内部都是有顺序的,从第0位开始表示第一个字母。
s[取第几位],0表示第一位,-1表示最后一位,-2表示倒数第二位。
定义s = 'ABCDLSESRF'
S1 = s[0] ————>S1的结果是A,用[]即可索引到具体位数的字符,S1是一个新的字符串
2) 切片,取片段
s[从第几位开始取:取几位(尾):步长],顾头不顾尾,步长默认为1
s[0:] 或s[:]都是取整个字符串s
s[0:0]为空字符串
定义s = 'ABCDLSESRF'
S2 = s[0:4]————>从第一位开始取,取4位,所以S2=’ABCD’
S3 = s[0:5:2] ————>从第一位开始取,在总长度为5的字符串里按步长为2取,返回’ACL’
S4 = s[4::-1] ————>从第5位开始取,在总长度为5的字符串里按步长为-1取(倒着取),返回’LDCBA’
s15 = s[::-1] =s[-1::-1]————>倒着将s取出来,返回’ FRSESLDCBA’
3) 字符串的操作
s = 'alexWUsir'
a) s.capitalize() # 首字母大写
s1 = s.capitalize() # 首字母大写——>Alexwusir
b) s.upper()# 全大写
s2 = s.upper()# 全大写——>ALEXWUSIR
c) s.lower()#全小写
s3 = s.lower()#全小写——>alexwusir
d) s.swapcase()# 大小写翻转
s4 = s.swapcase()# 大小写翻转——>ALEXwuSIR
e) s.center(20,'~') #居中,填充(不设置值就默认空白)
s5 = s.center(20,'~') #居中,填充(不设置值就默认空白)——>~~~~~alexWUsir~~~~~~
f) s.expandtabs()#连同/t之前的字符串一共补充到八位
s = 'alexWU\tsir'
s6 = s.expandtabs()#连同/t之前的字符串一共补充到八位,超过八位的补充到十六位——>alexWU sir(补了两个空格)
g) s.endswith('ir')#判断字符串以什么结尾
s = 'alexWUsir'
s7 =s.endswith('ir')#判断字符串以什么结尾——>True
h) s.startswith('e',2,5) #判断字符串以什么开头
s71 = s.startswith('e',2,5) #判断字符串以什么开头,也可以从中间判断,从第零位开始数数位,startswith('e',2,5)就代表判断第三个字符到第5个字符组成的这个片段是否以e为开头——> True
i) s.find('WU') # find
s8 = s.find('WU') # find 通过找整体返回该整体第一个元素的索引位置,返回值类型为int,找不到返回-1——>4
j) s.index('WU') # index
s81 = s.index('WU') # index通过找整体返回该整体第一个元素的索引位置,返回值类型为int,找不到报错 ——>4
k) s.replace('old','new'<,替换次数,默认全部替换>)#替换
s11 = s.replace('old','new'<,替换次数,默认全部替换>)#替换
l) len(s.strip())#length函数对列表类型也直接通用,求长度
s12 = len(s.strip())#length函数对列表类型也直接通用,求长度,一般来说要加strip未来避免有空格——>9
m) name.isalnum()、name.isalpha()、name.isdigit()#判断字符串组成类型,bool型变量。
name = ‘oskdnmocwu128734’
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成
n) s.title()# 每个隔开(特殊字符或者数字)的单词首字母大写,其余小写
s = 'aLex*eGon wusir'
s5 = s.title()
print(s5) ——>Alex*Egon Wusir
s = 'fade,crazy*w4rri0r_songsong node_3'
s6 = s.title()
print(s6) ——>Fade,Crazy*W4Rri0R_Songsong Node_3
o) s.strip(' %*') # strip默认删除前后空格或特殊字符 rstrip只删除右边的空格或特殊字符 lstrip只删除左边的空格或特殊字符
s = ' *a%lexWUsi* r%'
s91 = s.strip(' %*') ——>a%lexWUsi* r
username = input('请输入名字:').strip()
if username =='春哥':
print('恭喜春哥发财')
p) s.count('al') #count计算目标字符串中有多少标的字符的个数,可以是一个子字符串,列表中也通用
s = 'alexaa wusirl'
s10 = s.count('al') ——>1
q) s.split(';') # split str ---->list;默认按空格分列,字符串转换成列表就用split,列表转换成字符串用join,
s = ';alex;wusir;taibai'
s11 = s.split(';') ——>['', 'alex', 'wusir', 'taibai']
4) 高级格式化输出
#format的三种玩法 格式化输出
I. res='{} {} {}'.format('egon',18,'male')#直接用{}作为占位符,最后按顺序填充
II. res='{1} {0} {1}'.format('egon',18,'male') #占位符{}和索引号配合,最后按索引位置填充
III. res='{name} {age} {sex}'.format(sex='male',name='egon',age=18)# 占位符{}和变量名配合,最后按变量赋值填充
s = '我叫{},今年{},爱好{},再说一下我叫{}'.format('太白',36,'girl','太白')
name = input('请输入名字:')
s = '我叫{0},今年{1},爱好{2},再说一下我叫{0}'.format(name,36,'girl')
name = input('请输入名字:')
s = '我叫{name},今年{age},爱好{hobby},再说一下我叫{name}'.format(age=18,name=name,hobby='girl')
5) for循环(有限循环)
s = 'fhdsklfds'
for i(可迭代对象) in s:
(tab)print(i)——>依次将s中的字符赋值给i并循环打印出,直到最后一个字符结束
s = 'fdsa苍井空fdsalk'
if '苍井空' in s:
(tab)print('您的评论有敏感词...')
DAY4
1. 列表list
li = ['alex',[1,2,3],'wusir','egon','女神','taibai']
1) 增
a) Append在列表最后新增一个元素
li.append(‘Elsa’)——>#在li列表最后新增了一个元素’Elsa’,类型为str
li.append(1) )——>#在li列表最后新增了一个元素1,类型为int
b) Insert在列表之中插入
li.insert(4,'lxy')在列表中的第四个元素后面插入’lxy’,’lxy’的索引号为li[4]
c) Extend按可迭代对象的最小元素为列表加入多列
Int为不可迭代对象(can’t iteration)
li.extend('天伦') ——>在li列表中新增了最后两个元素’天’,’伦’
2) 删
a) pop(索引号),按索引号删除,有返回值
li.pop(1) # 返回值为被删掉的列表中第二个元素本身,也是增删改操作中唯一有返回值的。
li.pop() # 如果索引号为空,默认删除最后一个
b) remove(元素),按元素删除
li.remove('taibai')
c) clear()清空列表
li.clear()
d) del命令,删除列表本身
del li
del li[0:2] # 切片去删除,删掉前两个
3) 改
a) 单元素修改,直接按索引位置重新赋值
li[0] = '可爱'#将列表中第一个元素新赋值为’可爱’
b) 多元素切片修改
其实就是先片段删除再在原位置上按指示增加,增加的个数并不受删除个数的限制。
li[0:3] = 'abcd'——>['a', 'b', 'c', 'd', '女神', 'taibai']#删除原来的前三个元素后,在原位置按字符串迭代增加
li[0:3] = [1,2,3,'春哥','咸鱼哥'] ——>[1, 2, 3, '春哥', '咸鱼哥', '女神', 'taibai']#若给定列表,则按顺序将新列表的所有元素完整的加入进li列表,但这并不是嵌套,只是单纯的将元素插入了进来。
4) 查
a) 直接按索引号查
Print(li[0])
b) 用for循环打印每个元素
For i in li:#li必须是可迭代对象。
Print(i)
c) 切片查询(返回值为列表)
Print(li[0:3])
5) 公共方法
a) 长度len
Column_Num = len(li)——>返回li列表中的元素个数
b) 次数count
Element_Num = li.count(‘taibai’)——>返回’taibai’这个元素在列表中出现的次数
c) Index
列表中查询索引号只能用index,查不到就报错。eg: li.index('wusir')——>返回2
d) 排序sort(对纯数字列表或者纯字母列表)
正向排序:li.sort()
反向排序:li.sort(reverse=True)
如果列表中都是字符串元素,也可以进行排序,排序按照字符串元素的第一个字母的ASCII码的大小进行排序。
e) 列表反转reverse,无返回值:
li.reverse()——>直接将li整个列表反转顺序,无返回值
6) 列表自身嵌套着列表的增删改查操作
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
print(li[1][1])#找出武藤兰的腾
li[0] = li[0].capitalize()#将'taibai'首字母改成大写
li[2] = '苑日天'#把苑昊改成苑日天
li[2] = li[2].replace('昊','ritian')#把苑昊改成苑ritian
li[3][0] = li[3][0].upper()#将嵌套列表中的alex改为大写
7) 典型题
#算一串字符串中包含多少整数
s = input("请输入一串字符和数字的混合")
count = 0
for i in s:
if i.isdigit():
count += 1
print(count)
# 算一串字符串中包含多少整数(升级版:几个数相邻算作一个整数)
info = input('>>>').strip()
for i in info:
if i.isalpha():
info = info.replace(i," ")
l = info.split()#通过split默认按空格分列,将info分成以整数组成的列表。
print(len(l))#再求出列表的元素个数即可解决
2. 元祖tuple——只读列表(子元素不能改,孙元素可能可以改)
tu = (1,2,3,'alex',[2,3,4,'taibai'],'egon')
1) 查询
同列表,三种方式
a) print(tu[3])
b) print(tu[0:4])
c) for i in tu:
print(i)
2) 修改孙元素(列表中的删改操作都可用)
tu[4][3]=tu[4][3].upper()——>(1, 2, 3, 'alex', [2, 3, 4, 'TAIBAI'], 'egon')
tu[4].append('sb')——>(1, 2, 3, 'alex', [2, 3, 4, 'TAIBAI', 'sb'], 'egon')
3. Join(列表转换成字符串用join,字符串转换成列表用split)
在可迭代对象的每个元素之间加指定字符,返回一个字符串(列表转换成字符串用join,字符串转换成列表用split)。
s = 'alex'
s1 = '~'.join(s)——>a~l~e~x
li = ['taibai','alex','wusir','egon','女神',]
s = '-'.join(li)——> taibai-alex-wusir-egon-女神
4. Range(起始数(默认为0),终止数(依旧顾头不顾尾),步长)
#range [1,2,3,4,5,6,.......100........]其实就是一个等差数列,公差为1或-1,设定步长(更改公差)就可以间隔输出数字
for i in range(3,10):
print(i)
3
4
5
6
7
8
9
for i in range(10):
print(i)
0
1
2
3
4
5
6
7
8
9
for i in range(0,10,3):
print(i)
0
3
6
9
for i in range(10,0,-2):
print(i)
10
8
6
4
2
for i in range(10,-1,-2):
print(i)
10
8
6
4
2
0
for i in range(0,10,-1):
print(i)
输出为空,什么都没有。
for i in range(10,-1):
print(i)
输出为空,什么都没有。
for i in range(10,-2,-1):
print(i)
10
9
8
7
6
5
4
3
2
1
0
-1
#将列表中的孙元素也打印出来
li = [1, 2, 3, 5, 'alex',[2,3,4,5,'taibai'], ('a', 'b', 'c', 'd'), 'afds']
自写方法一:
for x in li:
if type(x) != int and type(x) != str:
for y in x:
print(y)
else:
print(x)
方法二:用range搭配length就可以表示出索引长度,因为range是从0开始的。
for i in range(len(li)):
if type(li[i]) != int and type(li[i]) != str:
for j in li[i]:
print(j)
else:print(li[i])
DAY5
字典 dict
Python中的唯一的映射数据类型,一个键(key,不可变数据类型,可哈希,只有元祖、str、int、bool四种选择)对应一个值(value,任意数据类型)。
字典的优点:
所有的键对应一个哈希值,字典中有一个哈希表,查找时用二分查找法,就不需要像列表中查找需要做循环,效率慢;存储大量的关系型数据。
字典的特点:
在Python3.5及其以前字典都是无序的。
数据类型划分
a) 可变数据类型
List、dict、set(集合本身是可变数据类型,但集合之中的元素是不可变的)。 又名不可哈希
b) 不可变数据类型(自身不可变)
元祖、bool、int、str。 又名可哈西希
1) 增
dic1 = {'age': 18, 'name': 'jin', 'sex': 'male',}
dic1['high'] = 185 #没有键对应,添加新键
dic1['age'] = 16 #如果有键对应,则值覆盖
dic1.setdefault('abc',xxx) # 有键对应,不做任何改变,没有才添加,如果没有设置值,默认为None。
dic1.setdefault('weight') ——> {'weight': None, 'age': 18, 'sex': 'male', 'name': 'jin'}
dic1.setdefault('name','二哥')——>{ 'age': 18, 'sex': 'male', 'name': 'jin'}
2) 删
a) Pop按键删除(最推荐)
dic1.pop('age') # 有返回值,按字典中的键去删除
dic1.pop('二哥','没有此键')#可设置返回值。当要删除字典里一个自己不确定有没有的键时,直接删如果没有就会报错,这个时候在后面加上一个参数(如’没有此键’)作为做不到此键时的默认返回值。
b) Popitem随机删除
dic1.popitem() # 随机删除键 有返回值(元祖,键及其对应的值) 元组里面是删除的键值
c) clear清空字典
dic1.clear()
d) 删除字典(按键删除时有缺陷)
Del dic1
del dic1['name']#也可以只删除键,没有此键时会报错
3) 改
a) 直接根据原值索引号覆盖
dic1['age'] = 16 #如果有键对应,则值覆盖
b) update(覆盖已有的键,增加没有的键)
dic = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic2.update(dic) #dic2中和dic相同的键被更新成和dic相同,dic中有而dic2中没有的键被添加进dic2.
4) 查
a) dic.keys()、dic.values()、dic.items()
print(dic1.keys(),type(dic1.keys()))——>dict_keys(['sex', 'age', 'name']) <class 'dict_keys'># dict_keys可以看做列表,列表的组成元素为字典的键。
print(dic1.values(),type(dic1.values()))——>dict_values(['male', 18, 'jin']) <class 'dict_values'># dict_values可以看做列表,列表的组成元素为字典的值。
print(dic1.items(),type(dic1.items()))——>dict_items([('sex', 'male'), ('age', 18), ('name', 'jin')]) <class 'dict_items'># dict_items可以看做列表,但其是由键值对构成一个元祖,再以元祖为元素构成列表。
for i in dic1: #查询字典类型不加任何函数操作,默认直接返回字典键
print(i)
输出结果:
age
name
sex
for i in dic1.items():
print(i)
输出结果:
('name', 'jin')
('age', 18)
('sex', 'male')#思考:键值对虽然打印出来了,但是很不美观,是元祖的形式,如何改进?
引申:多变量一行代码赋值
a,b = [1,2],[2,3]#a = [1,2] b = [2,3]
a,b = (1,2)#a = 1 b = 2
a,b = [1,2,3]#报错,左右两边必须参数个数一样才可赋值。
面试题
#一行代码交换a,b的值
a = 1
b = 2
a,b = b,a
print(a,b)
#变量与值得对应关系在内存中专门有一块空间保存,调用print函数时,便会到内存中去查找a变量所对应的值的内存地址是多少,再相应的读取出该内存地址所代表的空间存储的值。a,b = b,a相当于就是交换了a与b在内存空间当中的与值对应的内存地址。
因为可以多变量同时赋值,那么同样可以在for循环中应用,解决键值对以元祖方式打印不美观的问题:
for k,v in dic1.items():
print(k,’:’,v)
输出结果:
age : 18
name : jin
sex : male
b) 直接根据键来查(有缺陷)
v1 = dic1['name']
print(v1)——>返回这个键对应的值
v2 = dic1['name1'] # 报错
print(v2)——>直接插查不到键’name1’,报错,
c) dic.get()(最推荐)
v2 = dic.get(’name1’,’没有这个键’)#可以设置查找键时的默认返回值(不设置就是None),避免报错的情况。
5) 字典自身嵌套着字典、列表的增删改查操作
dic = {
'name':['alex','wusir','taibai'],
'py9':{
'time':'1213',
'learn_money':19800,
'addr':'CBD'
},
'age':21
}
# 将键age重新赋值
dic['age'] = 56
# 在字典的name列表中新增元素ritian
dic['name'].append('ritian')
# 将字典的name列表中第二个元素全部改为大写
dic['name'][1] = dic['name'][1].upper()
#在字典中的字典py9里面新增一个键female : 6
dic['py9']['female'] = 6
print(dic)
DAY6
小知识点总结
1. 编码
ascii
英:00000010 8位 一个字节
unicode
英: 00000000 00000001 00000010 00000100 32位 四个字节
中:00000000 00000001 00000010 00000110 32位 四个字节
utf-8
英 : 00100000 8位 一个字节
欧:00000001 00000010 16位二个字节
中 : 00000001 00000010 00000110 24位 三个字节
gbk
英:00000110 8位 一个字节
中:00000010 00000110 16位 两个字节
注意
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的储存,传输,不能是unicode(只能是utf-8 utf-16 gbk,gb2312,asciid等,因为Unicode实在太大了,浪费许多存储空间)
python3中str转换成bytes后再存储:
python3中的str 在内存中是用unicode编码。——>不能直接储存和传输,因为Unicode实在太大了,浪费许多存储空间,编码方式要转换成Utf-8或者GBK,表现形式就是str转换成了bytes。
bytes类型——也是一个数据类型和STR很像,区别就在于编码方式,
它直接用UTF-8/-16或者GBK编码,所以存储或者传输一个字符串时,先将其转化为bytes类型再进行存储或传输。
对于英文:
str :表现形式:s = 'alex'
编码方式: 010101010 unicode
bytes :表现形式:s = b'alex'
编码方式: 000101010 utf-8 gbk…..
对于中文:
str :表现形式:s = '中国'
编码方式: 010101010 unicode
bytes :表现形式:s = b'x\e91\e91\e01\e21\e31\e32'#这就是我们不直接使用bytes的原因,因为对于中文来说,它的表现形式在bytes中是十六进制,这对于人而言是很难被看懂的。
编码方式: 000101010 utf-8 gbk。。。。#上面的例子就是utf-8,应为两个中文对应了六个字节,说明是用三个字节表示一个中文,符合UTF-8对中文的编码特征,如果两个中文只对应了四个字节,那么编码方式就是GBK。
#str转成bytes,因为str要转成bytes后才能存储和传输
s1 = 'alex'
# encode 编码,如何将str --> bytes, (可以设置编码方式),表现形式是将str转换成了bytes,实际内部是将Unicode转换成了utf-8或者gbk或者GB2312
s11 = s1.encode('utf-8')
print(s11)# b'alex'
s11 = s1.encode('gbk')
print(s11) )# b'alex'
s11 = s1.encode('gb2312')
print(s11) )# b'alex'
s2 = '中国'
s22 = s2.encode('utf-8')
print(s22)# b'\xe4\xb8\xad\xe5\x9b\xbd'
s22 = s2.encode('gbk')
print(s22)# b'\xd6\xd0\xb9\xfa'
s22 = s2.encode('gb2312')
print(s22)# b'\xd6\xd0\xb9\xfa'
str与bytes在python3中的关系示意图
2.
python2与python3的一些区别
python2中
print() print
'abc'#python2 print可以不加括号
range()
#xrange() 生成器
raw_input() #python2中的input的函数
python3中
print('abc')#必须加括号
range()
input()
最新文章
- MySQL语句学习记录
- 关于java的递归写法,经典的Fibonacci数的问题
- set 集合容器实现元素的插入与中序排序
- 带领大家安装Rational rose
- TreeMap按照key排序
- HTC Vive开发笔记之UI Guideline
- ss 如何解决margin-top使父元素margin失效
- IBInspectable的使用
- 【Linux】鸟哥的Linux私房菜基础学习篇整理(八)
- python 解析 配置文件
- python word操作深入
- 一步一步学Python(2) 连接多台主机执行脚本
- 一键访问Google和YouTube等国外知名网站
- 通过git上传本地代码到github仓库
- DDMS调试工具
- Number (float bool complex)浮点型、bool 布尔型 True、False 、complex 复数类型
- python httplib2应用get post
- Javaweb学习(三):Servlet程序
- 基于设备树的controller学习(1)
- activity_main.xml 要用 Android Common XML Editor打开,双击的方式直接跳转到浏览器了